







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
Excel数据分析基础应用-用户行为分析(用户行为数据集)
 2023-11-28
2023-11-28 浏览次数:次
浏览次数:次 返回列表
返回列表一、选取合适的数据集
在excel上用一些基础的功能和函数来实现基本的数据分析。那先获取数据源,从阿里云天池上可以下载到“用户行为分析”的数据集,因数据量过大,这里随机选取出了50000条数据进行分析,数据集的具体信息如下:
数据来源:User Behavior Data from Taobao for Recommendation-数据集-阿里云天池
表格主要包括4个字段:用户id,商品id,用户行为,日期。
用户行为包括4个属性:pv(点击)、buy(购买)、cart(加入购物车)、fav(收藏)
数据描述:用户在2017年11月24~2017年12月3日之间,对各种商品的各种行为(点击、购买、购物车、收藏)进行统计。
二、数据预处理
拿到任何数据后,第一步都要做数据预处理,将一些异常的数据清理掉,其目的是保证统计顺利的进行 和 分析结果的精确。这里按照 删除重复值>处理缺失值>数值转换 的流程去操作。
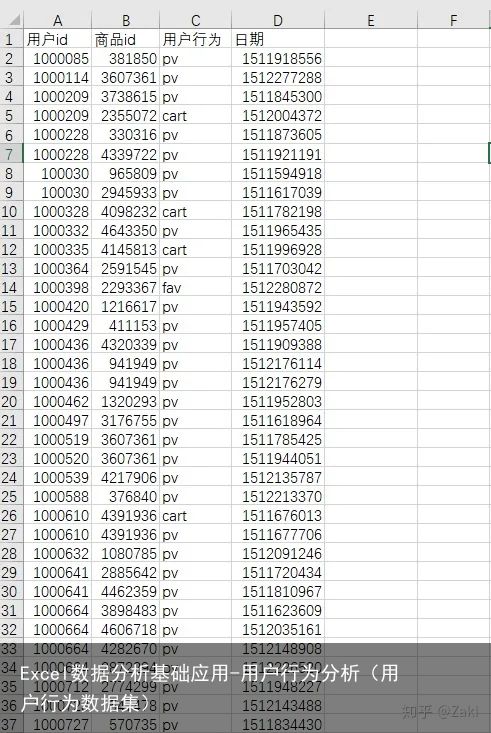
1)删除重复值
重复值表示一条数据被多次记录,造成结果的偏差。选中数据集后,点击“数据”工具栏下“删除重复值”功能,系统就会自动删除重复值。这里结果显示,有8个重复值被删除了。
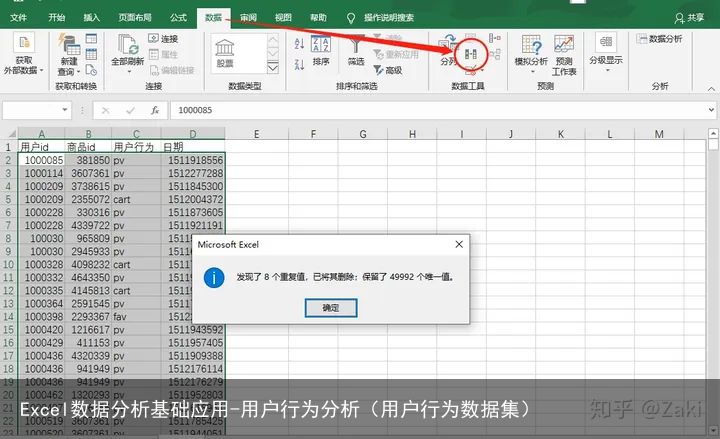
2)处理缺失值
缺失值就是没有数据,在excel里会是一个空白的表格,一般是由于数据输入过程中造成的。最简便快速的查找缺失值的方法就是用鼠标挨个选取每一列数据,看最底部的统计数是否一样,统计数较少的就肯定存在缺失值。
这里每列显示的结果都一样,计数为49993,也就表示没有缺失值。若假设真的存在缺失值时该如何处理呢?从业务角度进行分析,用户id虽然是一串数字,但这些数字之间是没有关联性的,也就是说不能计算用户id的平均值再去填补这个空缺的地方,同理商品id和用户行为也是一样的。遇到这类情况可以直接删除整行信息,确保剩下的数据能顺利进行统计。但要是日期出现缺失值时,是可以用全部日期的中位数或平均数去填补的,因为这份数据集采集的是2017年11月24~2017年12月3日之间用户的各种行为,也就是说日期肯定是在这个范围内的。
3)数值转换
通俗的讲就是把看不懂的数据转换成能看得懂的或是便于观看的。就像日期这一列,它其实是时间戳类型。这部分就需要一定的公式来进行处理,转换的公式为:
公式:(时间戳+8*3600)/86400+70*365+19
详细的计算过程就不展开了,这里直接展示计算后的结果。
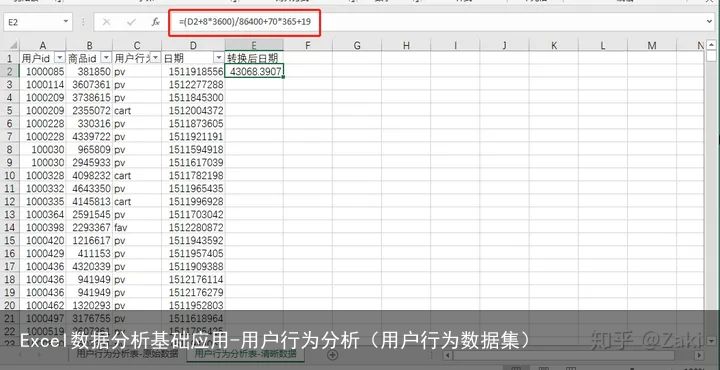
公式带入计算后发现结果还是一串数字,这时候还需要进行一步简单的操作才能完成转换。选择数据,再点击“开始”工具栏下的“数值格式”下拉框,在里面选择日期类型就可以了。
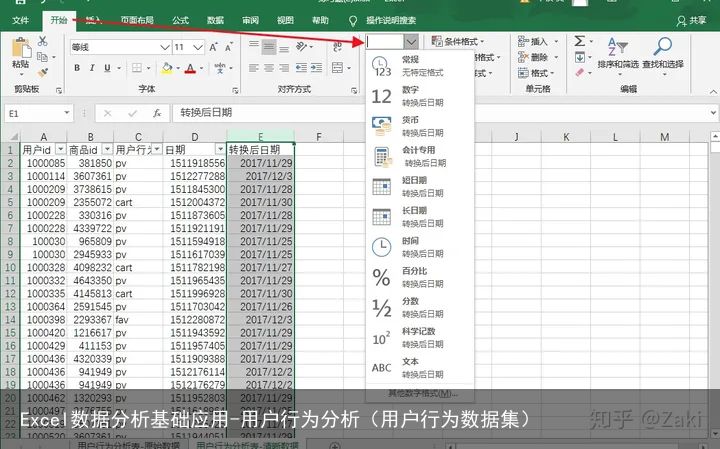
三、数据分析
对数据进行过预处理后,就可以开始正式的数据分析了,这里主要分析以下两个问题。
1)每种商品的各种行为之间的转化率问题。
关键字段:商品id,用户行为
分析思路:用户行为有pv(点击)、buy(购买)、cart(加入购物车)、fav(收藏)4个行为,从业务的角度来讲,不管是购买、加入购物车还是收藏,必定会经过点击这一步。也就是说一个用户必定要点击一个商品后,才能进行购买等操作。所以要计算 点击 与其他三种行为之间的比值来得出转换率,然后再统计每种商品被购买的转换率、被收藏的转化率、被加入购物车的转化率。
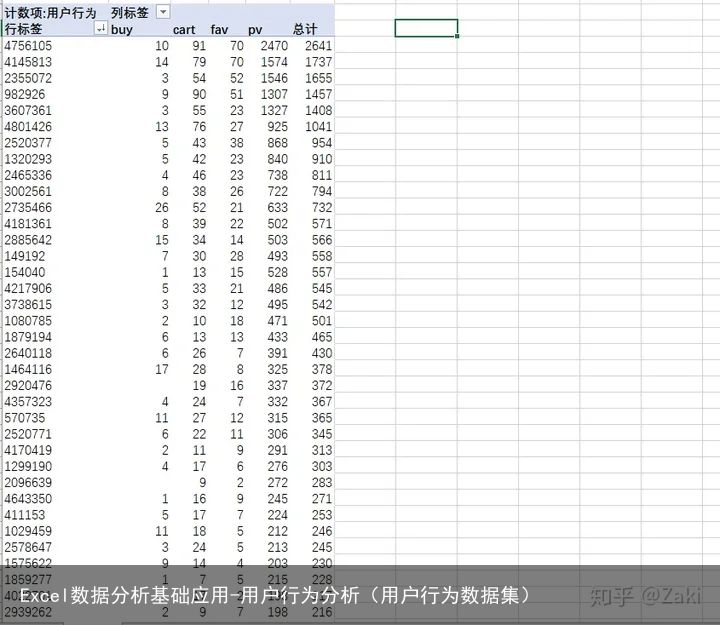
操作步骤:先选取商品id和用户行为两列,以商品id为行,用户行为为列,创建数据透视表。得到的结果就是 每个商品的各自被购买、点击、收藏了多少次。
由于在数据透视表中进行公式操作不太方便,这里复制数据并在新的表单中粘贴。同时新建三个列,分别为“购买转化率”、“购物车转化率”、“收藏转化率”。
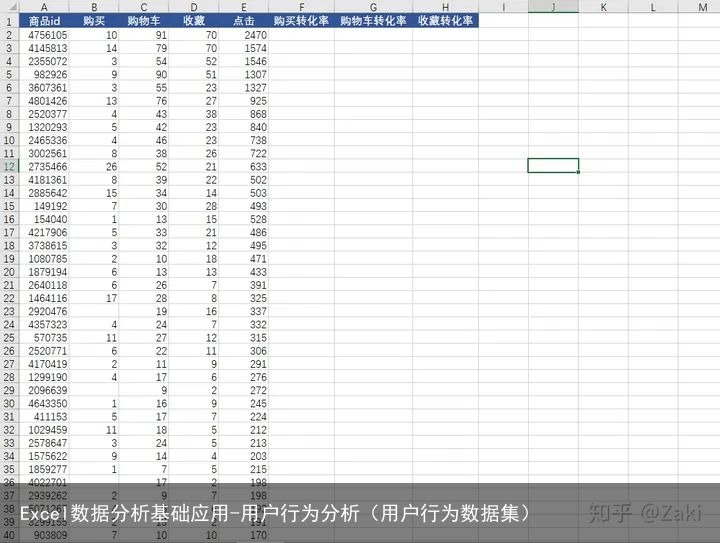
然后开始计算,购买转化率=购买数/点击数。直观的理解就是,该商品每被点击多少次,就会被购买1次。同理,购物车转化率和收藏转化率也是这样计算,最终效果如下。
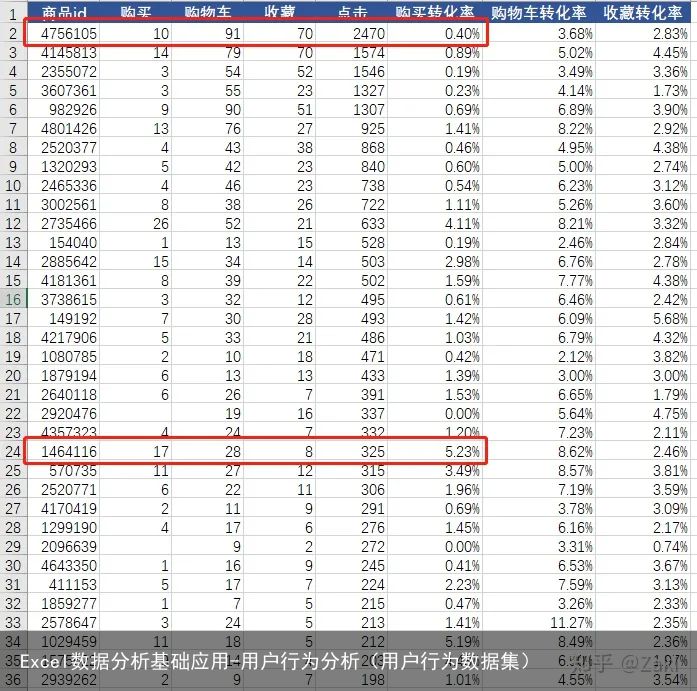
由于数据较多,这里就用红框标出两条数据来进行解读和分析,并推导出一些假设。
先看第一条,该商品的点击数是最高的,但相比其他商品购买转化率却很低,那有可能就意味着这个产品还不够吸引人,或是叫好不叫座,看的人多买的人少。那问题大概率就出在产品自身上面。
再看第二条,虽然点击数很低,但购买转化率较高。那有可能这个产品对比其他产品来说是比较吸引人的,但是投放的渠道不好,以至于知道它的人少;也有可能产品页面图片太差,让人没有欲望去点。所以问题大概率出在宣传方面和渠道方面。
2)用户价值分析,找出前100价值度最高的客户
关键字段:用户id,用户行为
分析思路:先统计每位用户的各种行为的总量,然后按“购买意向”给每种行为添加权重,来计算得出每位用户的价值。按常理来讲,“购买意向”的权重的大小排列为 购买>购物车>收藏>点击。所以先假设 各种行为的权重值为 :购买0.55 购物车0.25 收藏0.15 点击0.05。通过计算后在排序筛选出前100的用户 。
操作步骤:先选取用户id和用户行为两列,以用户id为行,用户行为为列,创建数据透视表。得到的结果就是 每个用户的购买、点击、收藏、加入购物车的次数。
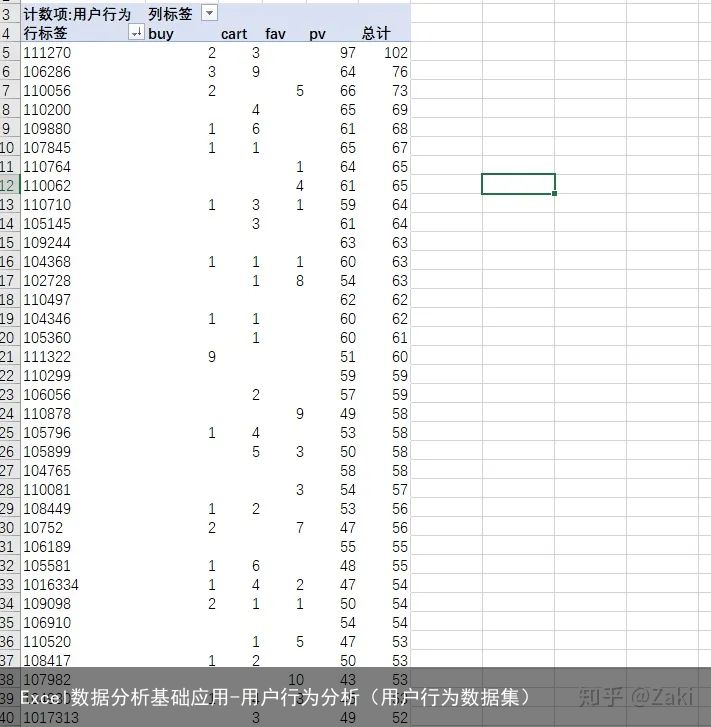
同样复制粘贴表格后,创建一个“用户价值”列。用上述提到的权重公式来对这一列进行计算。
公式:购买*0.55+购物车*0.25+收藏*0.15+点击*0.05
计算得出结果后,对“用户价值"列按降序进行排序。但是发现从常理的角度讲,数据存在不合理的现象,有些客户购买数那么低,为何排名还这么靠前?

那就说明这里的公式不合理,也就是权重没有分配好,那么修改公式并重新计算。
公式:购买*0.74+购物车*0.15+收藏*0.10+点击*0.01
这里说明一下,公式是凭经验设计出来的,没有固定的格式和原理。它遵循的逻辑就是买过东西的人权重就高,没买过的权重就低。但考虑到又不能单一的以购买来衡量,所以其他行为作一个小的加分项来处理。最后计算结果如下:
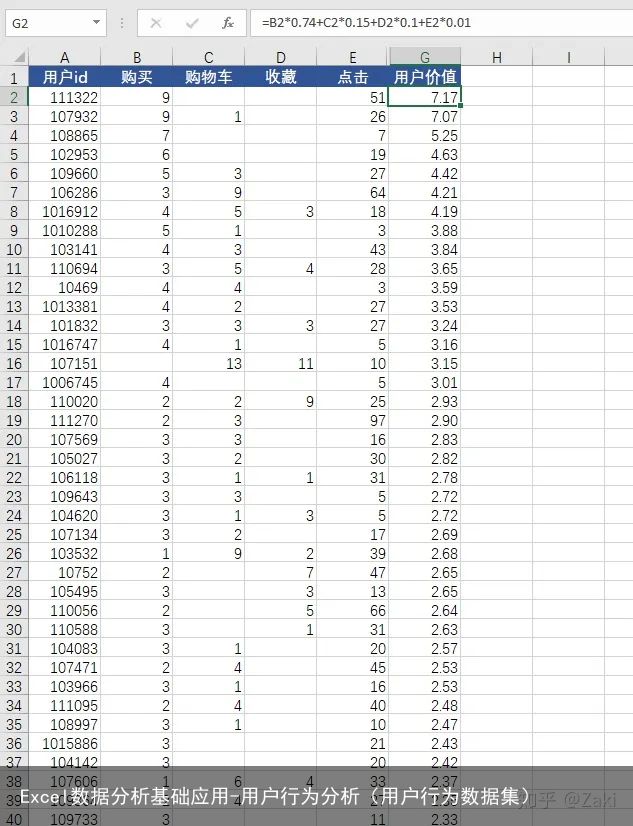
发现整体效果要比之前合理很多,这里也不再继续优化下去了,就把该结果作为答案。前100条数据的用户就可以判断为价值度最高的客户。
