
大家好,我们接着来分享系列课程,给数据分析师看的Python。上一次我们分享了如何手工建立DataFrame以及如何读入文本文件的数据,今天我们来看看如何读入Excel文件。
1、读入Excel文件。先来看看我们的Excel长什么样子。我们有一个叫做test的Excel工作簿,里面有一个sheet,内容如下图所示。
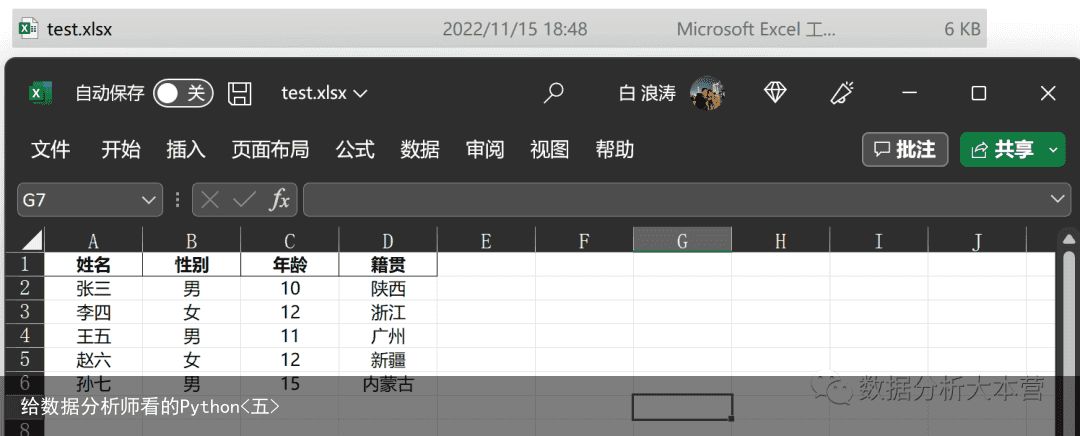
要读入这个Excel的数据我们首先要引入Pandas包,然后使用Pandas下面的read_excel()函数来导入Excel数据。我们来看看具体代码。
# 导入需要的包import pandas as pd# 读入Excel数据df1 = pd.read_excel(rE:/公众号Python/test.xlsx)向右滑动可查看完整代码我们来解释一下这个代码。第一句自然不用说,是引入Pandas包,我们来看read_excel()这个函数,有个参数,就是我们要读入的Excel文件的地址,这个地址是个字符串,所以要用单引号包起来,也可以使用双引号,但是都必须是英文状态的,那么前面的这个r是什么意思呢?这里是转义符的作用,比如\t是换行符的意思,但是我们这里\t只是个巧合而已,没有换行的意思,前面加个r就是要告诉程序,这里\t没有特殊含义,就仅仅是\和t的意思。我们把的读入的这个数据框赋值给变量df1。

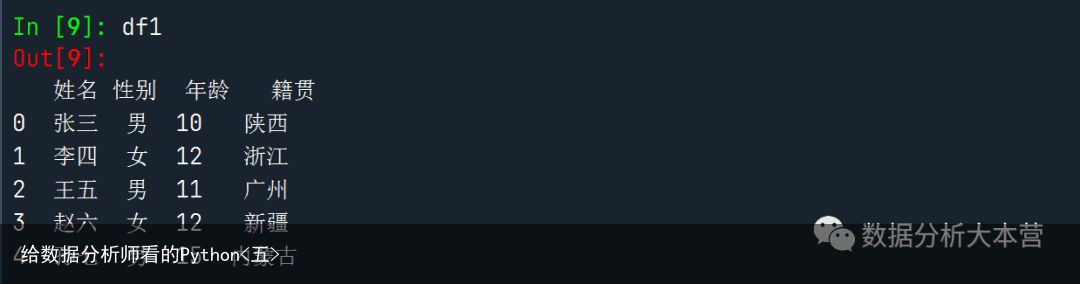
选中df1运行,就可以看到我们df1长这个样子。
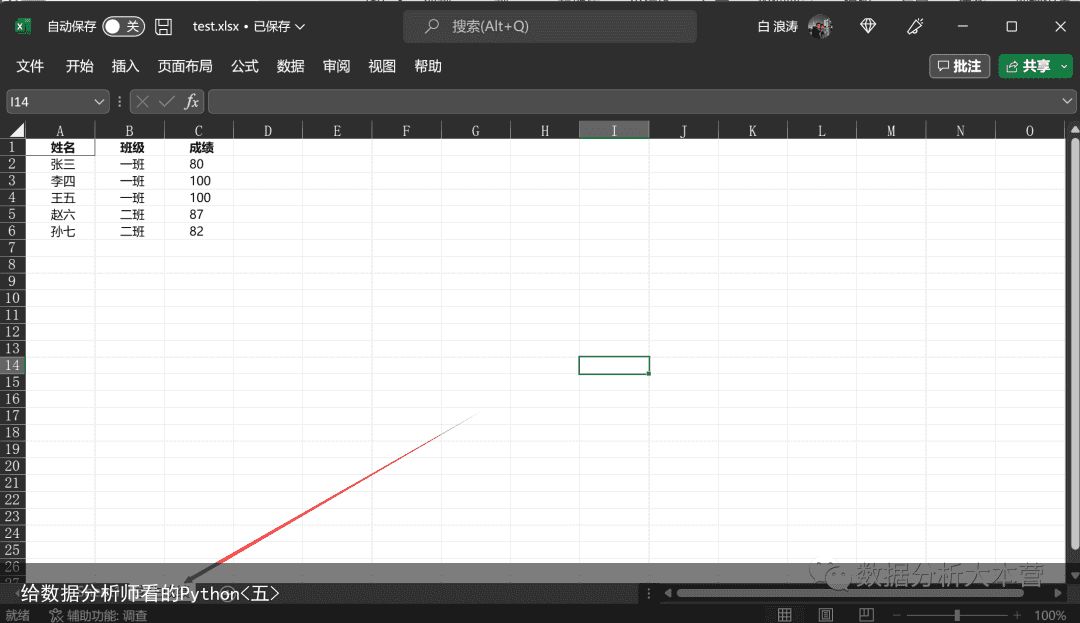
那我们都知道,一个Excel工作簿是可以有很多个工作表的,程序怎么知道我读入的是哪个呢?其实read_excel()中有个参数叫sheet_name,就是用来指定具体读入哪个sheet的数据的。我们前面的演示之所没有指定具体哪个sheet依旧可以正确读入,是因为这个函数默认是读入Sheet1这个表的数据,而我们的数据恰好就在Sheet1中。假如我们的数据在“学生成绩”这个sheet中,我们该怎么读入呢?
df2 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=学生成绩)向右滑动可查看完整代码我们只要在sheet_name参数中给定要读入的表名即可。要
注意:①该函数默认读入的是Sheet1的数据,其中S是大写,因为Excel中是大写,②默认读入的是
Sheet1的数据,而
不是第一个sheet的数据,即使你把学生成绩表移到前面,如果你没有指定具体的sheet_name,默认读入的还是Sheet1的数据而不是学生成绩表的数据。有时候我们的Excel数据前面会有一些注释,如下图所示。
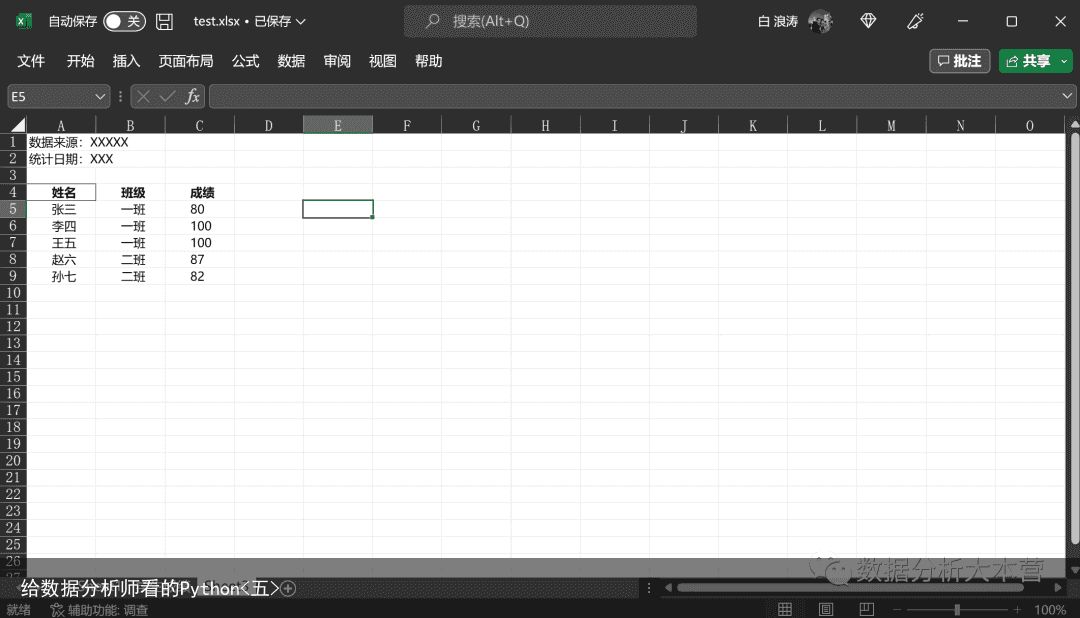
我们如果直接读入就会有问题,我们来试一试。
df3 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet3)读入后的结果如下图所示:
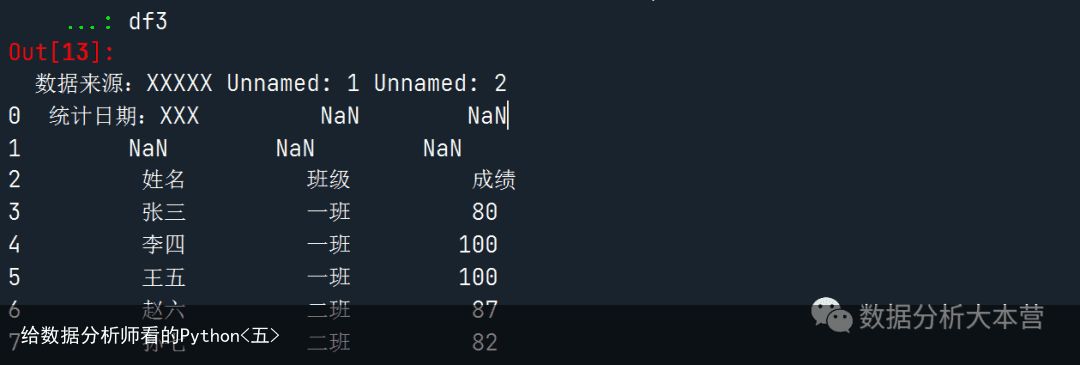
这显然不是我们想要的结果,我们想要的是把上面的注释和空行都不要的数据,这样该如何实现呢?这里,就要用到header参数。它是用来指定字段名在哪一行的。我们看看表格,第一行如果按0开始,那么我们的字段名是在第三行,因此header应该指定为3。这样我们就可以正确读入数据。
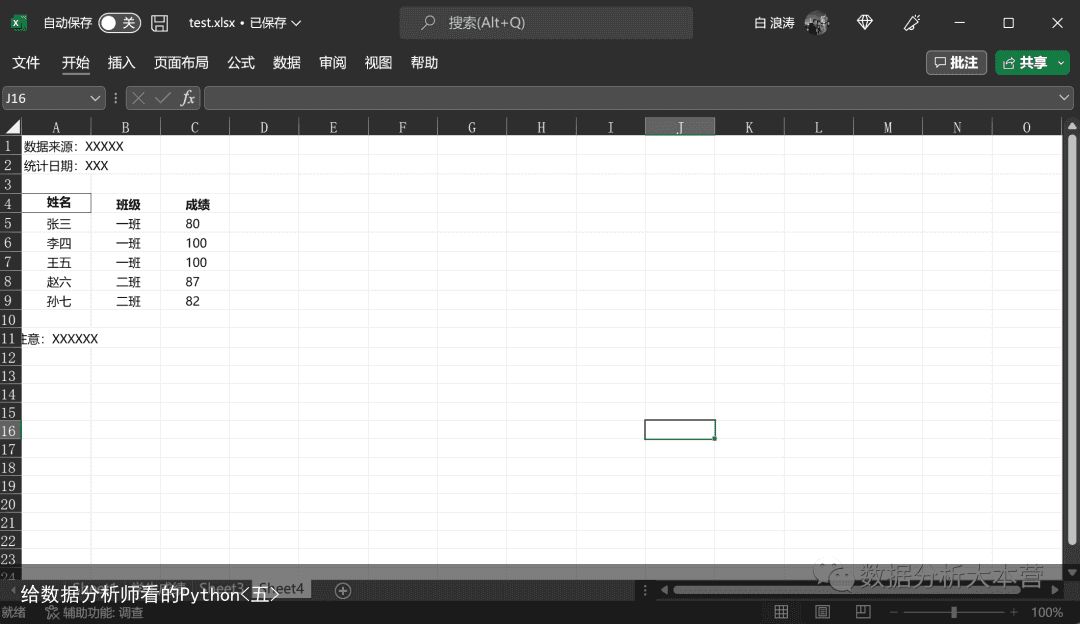
df3 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet3, header=3)向右滑动可查看完整代码我们再来增加个难度,加入我们的数据后面还有些不需要的注解啥的,如下图所示:我们又该如何处理呢?
这里我们就需要指定读入的行数了,用到的参数是nrows。我们相当于要告诉程序,读入Sheet4工作表的数据,它的标题在第3行(以0开始计),总共我们读入5行数据(不包含标题)。代码如下:
df4 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet4, header=3, nrows=5)向右滑动可查看完整代码我们继续,有时候并不是数据源中所有的列都是我们要读入的,那么我们可以使用usecols参数来指定要读入的列。假设我们只要读入学生成绩表的姓名和成绩两列。我们把列名写入一个list,然后赋值给usecols参数。
df5 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=学生成绩, usecols=[姓名, 成绩])向右滑动可查看完整代码我们继续。假设我们的数据是这样的,第一列是学号,是一列文本型的数值。我们该如何正确读入呢?
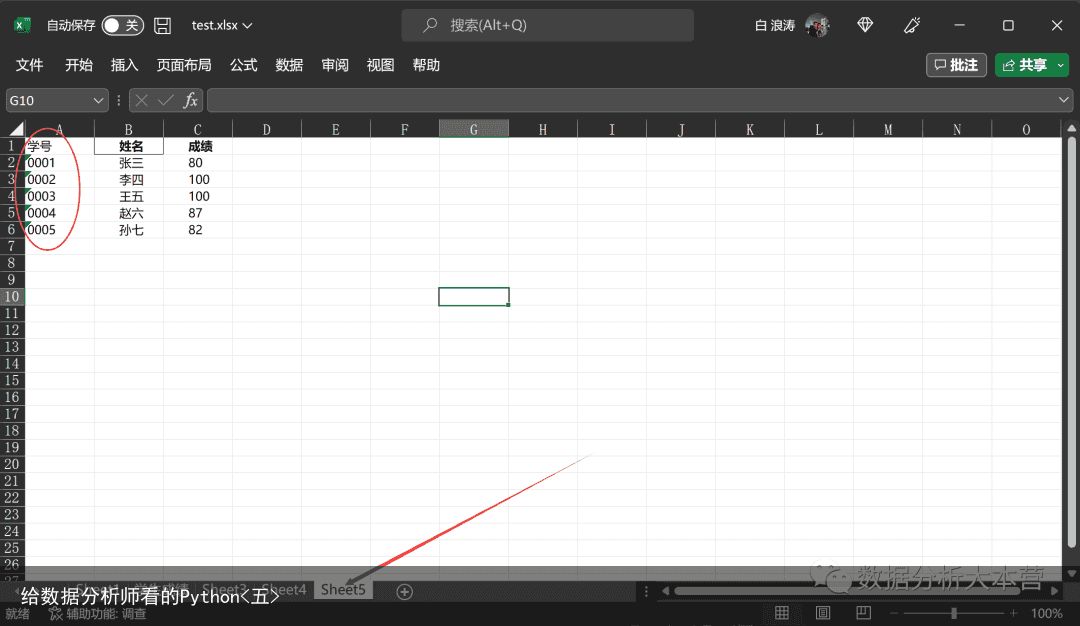
如果使用我们前面学到的方法,大家可以尝试一下,读入的数据是有问题的。学号一列前面的0全部都没有了。

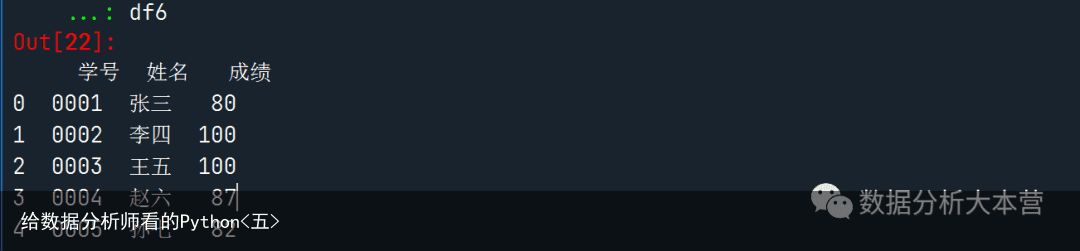
之所以会出错是因为Pandas认为我们读入的第一列是个数值,而实际上我们的第一列应该是文本才对,那么这个信息如何传递给程序呢?这里就要使用dtype参数来指定读入数据的数据类型。代码如下:其中str就是代表字符也就是文本这种类型。df6 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet5, dtype=str)向右滑动可查看完整代码读入结果如下:
读入后我们对成绩这列求个和,看看有啥问题。这句代码我们后面会介绍,这里大家只要知道是对成绩列求和就好了。df6[成绩].sum()计算结果如下:

显然是不对的,它是把所有成绩都组合在了一起,为什么会这样呢?因为我们读入数据的时候,指定了数据类型是’str,这样Pandas就认为每一列的数据类型都是str,这显然是不合适的。那么如何只指定学号列是字符串呢?或者更具普遍性一些,这个问题是如何在读入时对不同列指定不同的数据类型呢?我们可以这样写。
df7 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet5, dtype={学号:str, 成绩:float})向右滑动可查看完整代码我们把一个字典赋值给dtype参数,这个字典的键是列名,值是对应的各列的数据类型。这里的意思就是学号列使用字符型,成绩列是浮点型。读入结果如下:

我们继续对成绩列求和就没有任何问题了,结果如下:

假设我们数据源中没有标题,我们该如何在读入的时候指定合适的标题呢?比如下图所示的情况。
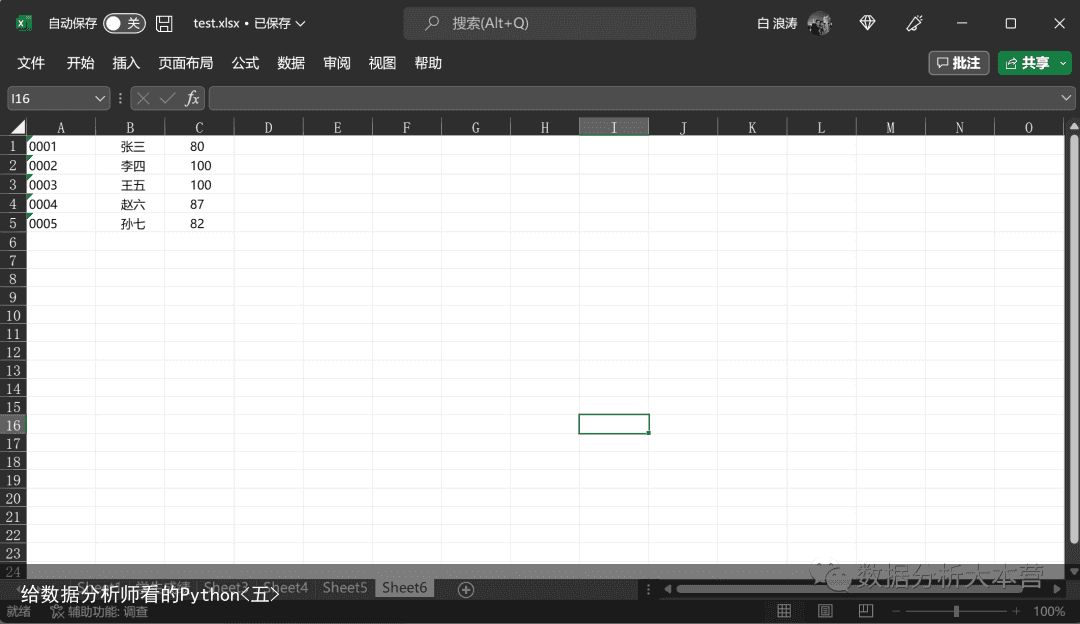
我们可以使用header = None来告诉程序,这个数据没有字段名,然后使用names参数来指定列名。(还记得读入文本文件时候也有相同的问题么?)df8 = pd.read_excel(rE:/公众号Python/test.xlsx, sheet_name=Sheet6, dtype=str, header = None, names=[学号,姓名,成绩])向右滑动可查看完整代码
读入后,结果如下:

以上就是我们今天分享的如何读入Excel文件的内容,这里只是介绍了read_excel()常用的一些参数,还有很多参数是没有介绍的,大家如果有兴趣可以去看看官方文档或者百度一下。好了,我们今天的分享就到这里。感谢大家的关注。
大家对于我们这个系列课程的分享,有什么好的意见和建议,请一定告诉我,我会在后续的分享中改进。大家有什么问题,也可以加入我们QQ群或者微信群进行交流。
扫描二维码和群友一起交流学习吧~









![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)


 2023-03-06
2023-03-06 浏览次数:次
浏览次数:次 返回列表
返回列表