







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
一文看懂,Scrapy 底层逻辑是如此的简单
 2023-03-07
2023-03-07 浏览次数:次
浏览次数:次 返回列表
返回列表序 (Jacky 说)
文:朱元禄(数据分析-jacky)
科学和技术总是假装的高大上,把许许多多的入门者拒之门外;了解 Python 爬虫的人都知道,Scrapy 是一个可以商用的爬虫框架,如果我们要做专业的爬虫,就要引入专业的爬虫框架;那什么是框架,什么又是商用框架;其实框架也没有那么高大上,无非是被人给你封装代码,而已。就像是 java 中的 spring 框架也是别人封装好的,你拿来用而已。在进一步说,框架也是人写的,既然是人写的就会有规律,这个规律就是设计模式,什么是模式?模式就是抽象了的思想(这个是我说了,不严谨,但正确)举个例子,Scrapy 这个商用的爬虫框架,官网中的体系结构如下图,那作为Python最拿的出手的框架之一,设计Scrapy的这哥们(我暂时认为是男的),是怎么设计出这个出名的框架的呢?下面正文,jacky(朱元禄)会深入浅出的介绍爬虫框架的设计原理,其实真的很简单
(一)为什么会有爬虫
近十年,我们从PC互联网时代进入了移动互联网时代,在移动互联网时代,我们随时随地都会产生数据,我们就餐、散步、或用手机APP购物等等,都会产出数据。而这些数据对商家后期的决策,供应链的管理,产品的设计以及对客户的偏好的摄取都有非常重要的作用和价值。
爬虫从本质上说一种数据获取的手段;而现阶段数据获取的手段主要有三种:
第一种:自有数据(银行、医院、阿里 等等)
第二种:购买数据
第三种:通过爬虫获取
(二)Scrapy 底层的设计模式
1. 爬虫的运行原理每个网页的背后都是 html 的源代码,html 的源代码是通过浏览器解析后显示结果,在一个页面的下面又分为很多其他的链接,而其实这些链接就是一个一个的 a 标签;
这个爬虫的过程,无非就是通过网络去获取目标页面的源代码,然后把源代码解析获得感兴趣的数据,保持以后带存储的超链接并且要去重处理,这样就会产生出新的带爬取的地址,接下来我们又去获取这个新的页面信息和里面有价值的数据,如此循环就构成了整个爬虫的运行机制。
2. 爬虫的设计模式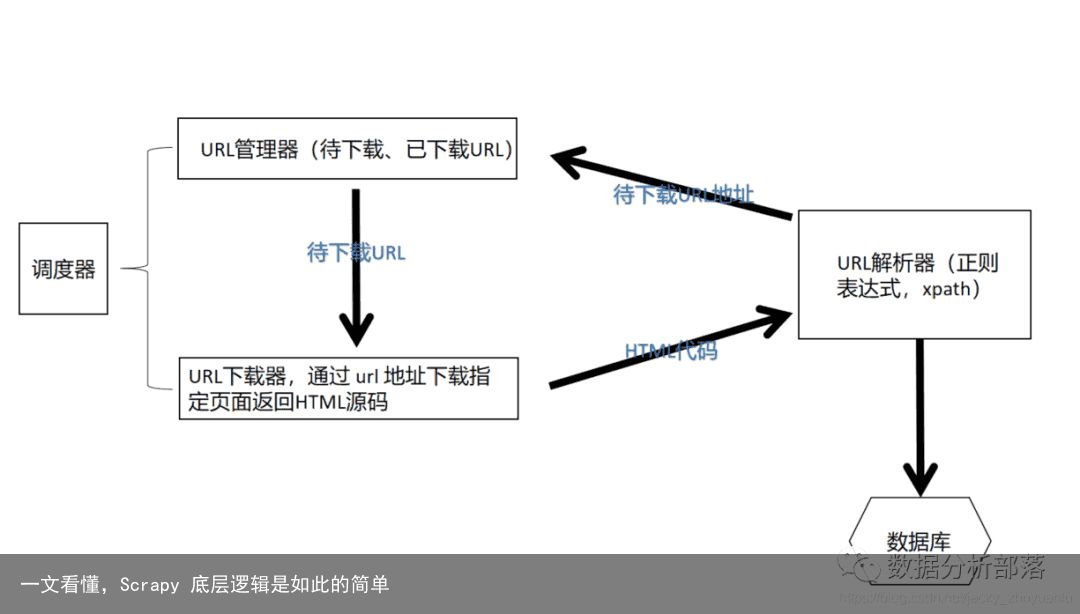
(1)URL 管理器(待下载的地址和已下载的地址)
通过两个 set 集合来管理。(set集合的特点是没有顺序,且不能重复)
所谓待下载,就是已经存起来,但还没有下载的网页中的地址;
为什么要保持已经下载过的地址呢?如果我们到达另一个页面,另一个页面也有当前的地址,如果当前这个地址已经被下载过,就不应该让它再次下载。
那这里的设计模式就是,我们应该设计什么样的模式保持当前待下载和已下载地址?
(2)URL 下载器
通过URL管理器中的地址,下载指定的页面返回HTML源代码
(3)URL 解析器
在URL下载器返回的HTML源码中,找出有价值的数据,每个公司对有价值数据的定义都不一样,有价值的数据需要对HTML的源码进行解析;
通常来说最强大的解析器就是正则表达式,
(4)调度器
上述模块中相互怎么调用,先执行谁,执行后数据如何传递,我们开始时如何指定初始地址,以及爬虫什么时间结束等等。
(三)总结
后面 jacky 会连载介绍 scrapy 框架,我们只要理解爬虫框架通用的设计思想,我相信在学习 Scrapy 框架的时候,会有更好的理解。
