







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
03-怎么用Excel进行数据分析
 2023-03-12
2023-03-12 浏览次数:次
浏览次数:次 返回列表
返回列表每一位数据分析师都离不开Excel,它是日常生活中最常用的分析工具。它不仅可以帮助我们去掉重复繁琐的体力劳动,提高工作效率;也能适应目前的发展潮流,具有数据建模的能力;更是可以绘制精美的数据图文报告,成为打动上司的敲门砖,使升职加薪成为可能。下面我们就来看一下用Excel怎么来进行数据分析。
数据分析的步骤:
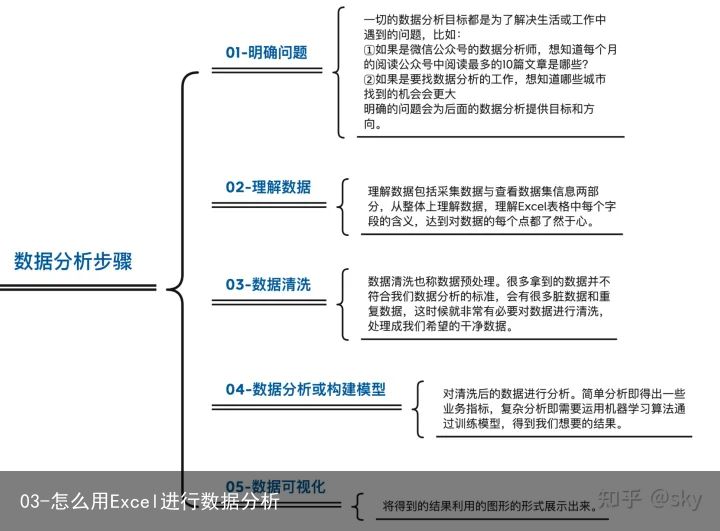
一、明确问题
如果想要从事数据分析的岗位,就需要对岗位有所了解,最直接的方式就是从招聘网站获得数据,进而指导目前的学习方向以及后续的简历准备。下面我们以招聘网站数据分析岗位的招聘信息为例,对其进行一些探索分析。假设让我们分析以下三个问题:
(1)哪些城市找到数据分析师工作的机会比较大?(2)数据分析师的薪水如何?(3)根据工作经验的不同,薪酬是如何变化的?【注意】:要养成良好的习惯,将原始数据进行备份,防止后续数据操作不当,原始数据丢失(并命名为清洗数据,后续操作皆在清洗数据的Excel文件中进行操作)。
二、理解数据
2.1 熟悉Excel工作界面
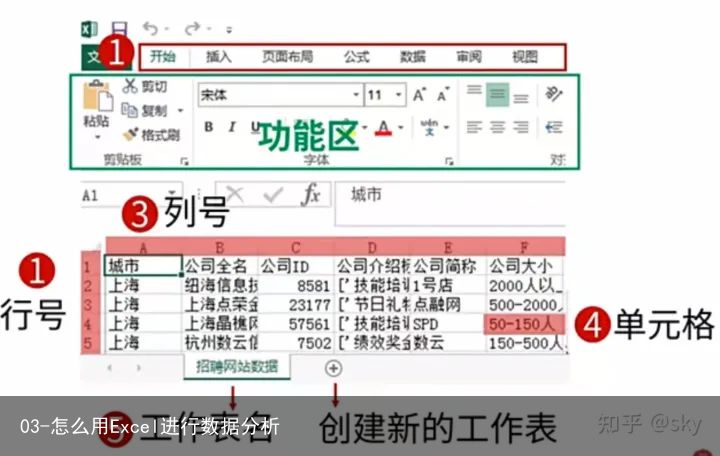
2.2 数据类型
数据会有多种类型,不同的数据类型会在不同的场景下使用。比如记录数字会使用数值型数据;记录文本会使用字符串类型数据;记录日期会使用日期型数据…
Excel中也有区分任一单元格数据类型的方法:
步骤为:选中单元格–>右键–>设置单元格格式–>可查看数据类型
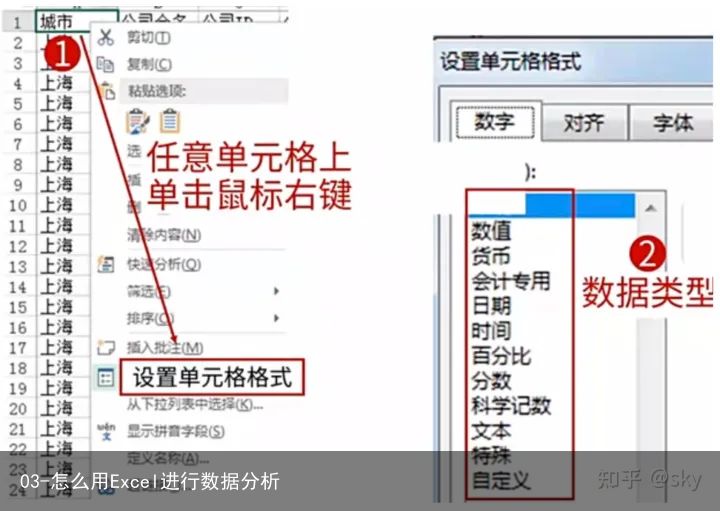
总结来看:数据分类一般包括字符串型,数值型与逻辑型

【注意】:字符串类型数据不能用于计算
那么Excel中如何快速查看数据类型呢?
步骤:选中任意单元格—>查看单元格格式
【注意】: (1)如果单元格格式是“常规”,则不能判断单元格的数据类型。
默认情况下:(2)字符串类型:左对齐;数字类型:右对齐
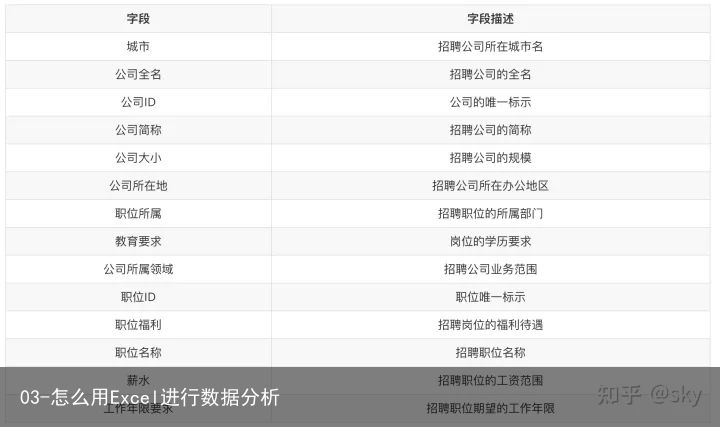
2.3 字段描述
该招聘网站数据表有14个字段,共计6874条数据,其字段含义如下:
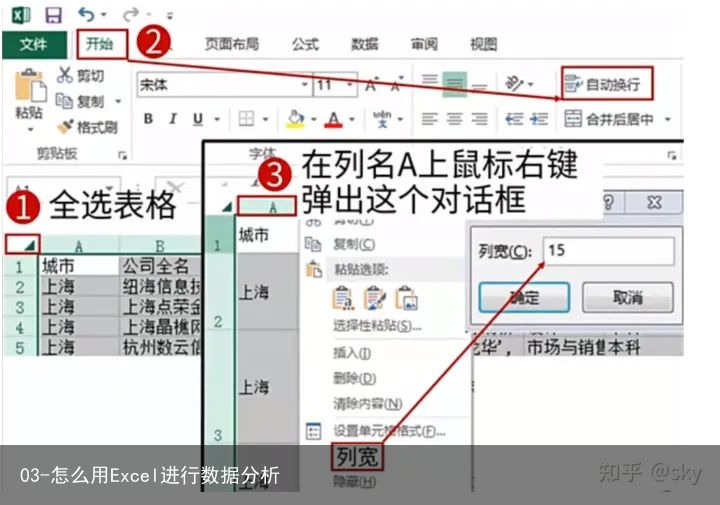
【注意】:如果某一列文本过多,导致文本被遮挡,如何显示遮挡内容?
步骤1:全选表格–>开始选项卡–>自动换行(可显示所有数据)–>选中列名(右击可通过设置列宽显示数据)
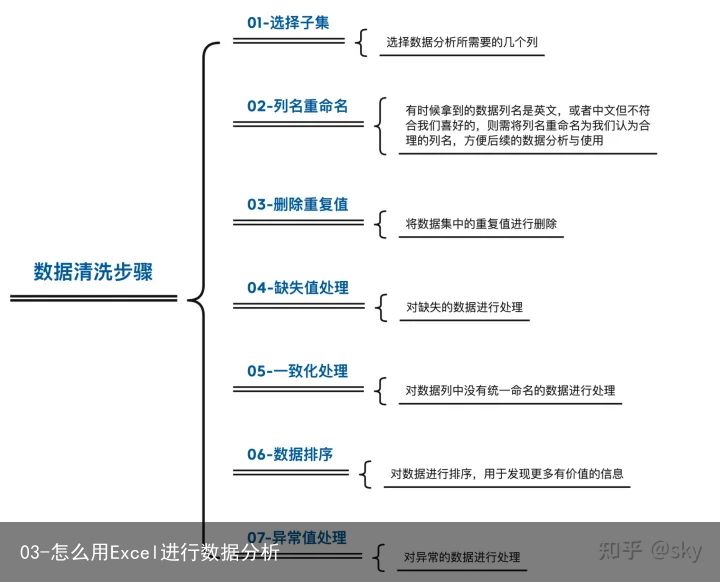
三、数据清洗
在数据分析的过程中,有多达60%的时间都是用在数据清洗这一流程,比如处理缺失数据,删除异常值等。其目的是把原始数据整理成我们想要的形式,以便后续的探索与分析。数据清洗步骤如下:
3.1 选择子集—Excel的隐藏功能
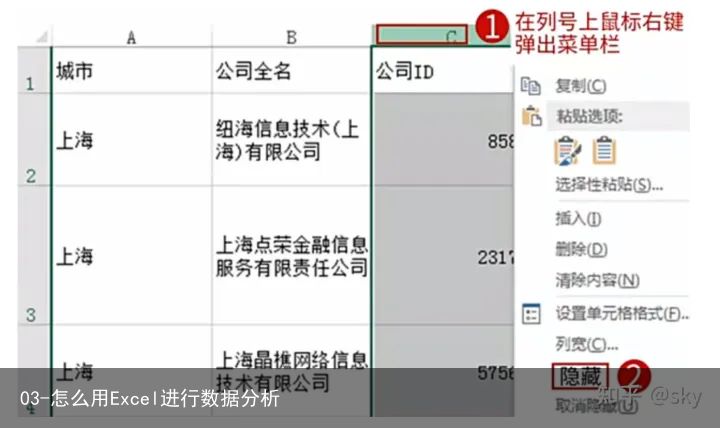
有时我们拿到的数据过大,并不是所有数据都是我们所需要的,此时就需要对数据进行选择,选择所需要的几个列即可。在Excel中所使用的方法就是Excel的隐藏功能,通过其隐藏功能可以实现数据集的灵活选取。
步骤:选中列—>在列号点击右键–>选择隐藏。具体操作如下:
针对该案例,进行子集选取:
(1)隐藏公司ID:职位ID作为招聘的唯一标识,公司ID就显得不必要了,故将公司ID进行隐藏。(2)隐藏公司全名:公司全名和公司简称表述含义相同,只需保留其一即可,这里保留简称。【注意】:要养成对不需要的数据尽量采取隐藏的方式,而不是删除,这样可以保证数据的完整,以便后续需要时可以随时恢复。
那么如何将数据列进行恢复呢?步骤:全选表格–>选择开始选项卡–>选择格式–>在弹出的对话框中点击“隐藏和取消隐藏”–>选择取消隐藏行还是隐藏列。具体如下:

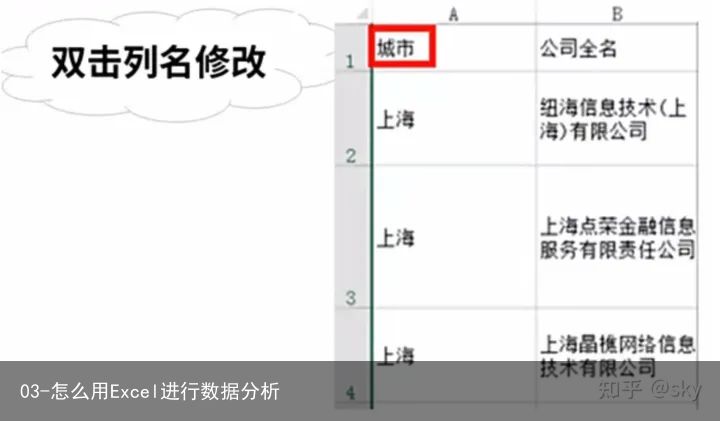
3.2 列名重命名–双击列名修改
可以按照自己命名习惯对不合理的列名进行修改。Excel中修改列名的方法是“双击列名”进行修改。
3.3 删除重复值–删除重复项
本案中职位id是每个职位的唯一标识,如果该列值重复了,说明有重复的数据,就需要进行删除。Excel中通过删除重复项来实现重复数据的删除。
步骤:点击数据选项卡–>选择删除重复项–>在弹出的对话框中点击“取消全选”–>选择对应的列名–>点击确定。具体操作如下:
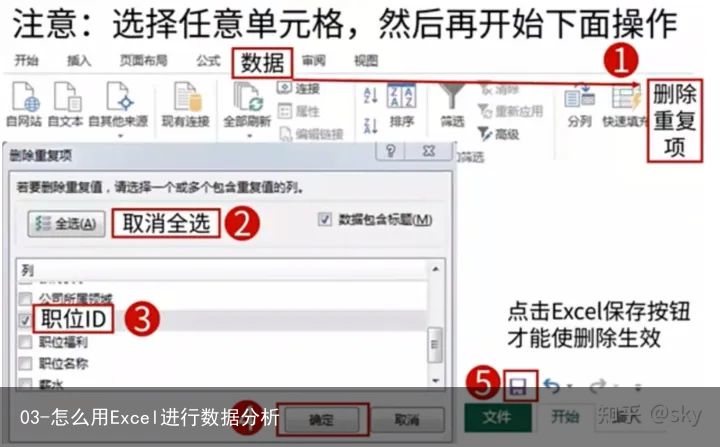
此时删除重复值后,数据共计5033条。
3.4 缺失值处理
缺失值是指为空的属性值。缺失值处理包括识别缺失值与填充/删除缺失值两部分。如果想要对缺失值进行处理,就需要先统计出缺失数据有多少,看是否与数据总量相同,来判断是否有缺失值。
造成数据缺失的原因有以下几种:
(1)数据未输入。例如工作人员故意或不小心没有输入数据。
(2)设备故障。例如收款机故障,导致顾客消费明细无法输入。
(3)因数据内容不一致而被删除。例如A数据表和B数据表中都有某个会员的信息,但是信息不同,这时两个表里本应该相同的信息不能匹配,为了避免错误的数据影响分析结果的准确性,可能会将该项数据以空值取代,因此产生数据缺失。
3.4.1 识别缺失值
Excel中判断是否有缺失值的步骤如下:点击列名(职位ID)–>在右下角查看”计数“后的数值【此时为5033条】。
本案例中:由于职位ID为所有招聘信息的唯一标识,所以此列数据是完整的,没有缺失。通过将其他列数据总数与该列总数对比即可知道是否有缺失值,缺失了多少条数据。每个字段缺失信息如下:
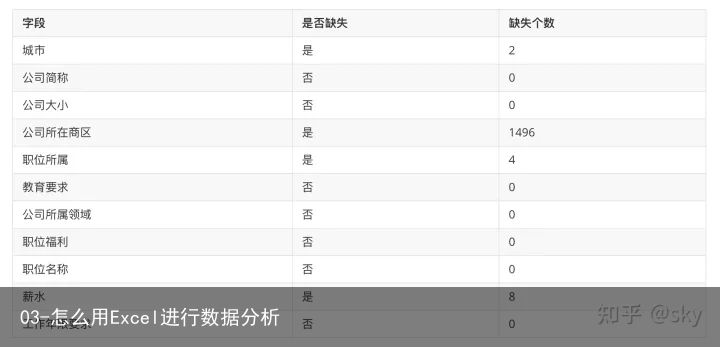
发现城市,公司所在商区,职位所属以及薪水有缺失,其中公司所在商区字段缺失达20%以上。
3.4.2 处理缺失值
处理缺失值有以下四种方法:
【1】人工手动补全:适用于缺失值比较少的情况
【2】删除缺失数据
【3】用平均值填充缺失值
【4】用统计模型预测值来填充缺失值
在本案例中发现城市,公司所在商区,职位所属以及薪水有缺失,其中城市,职位所属以及薪水缺失值较少,公司所在商区缺失值较多,超过20%以上。
下面以处理“城市”列为例,介绍使用Excel如何处理缺失值。由于城市列缺失数据较少,可以通过查找缺失位置进行人工填充。
【重点来了】如何定位缺失值呢?
定位缺失值的步骤:选中缺失的数据列–>打开开始选项卡–>选择查找和选择–>选择定位条件–>在弹出对话框选择空置–>点击确定即可。具体操作如下:
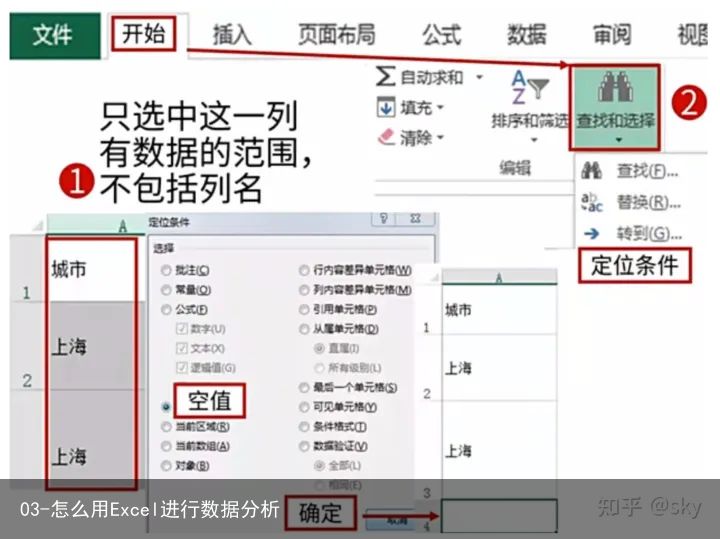
通过判别发现缺失位置对应的城市应该属于上海,则填入即可。
【注意】有个快速填充的方法:CTRL+ENTER即可完成其他空白单元格的批量填充。

3.5 一致化处理–Excel的分列功能
我们拿到的原始数据中可能会存在数据不一致(没有统一的标准或命名)的情况,比如在本案例中“公司所属领域”列,有些是单个比如移动互联网,有些属于多个所属领域用逗号隔开,比如“企业服务,数据服务”,这种格式是不一致的,如果不进行处理,可能会影响数据分析的结果。因此针对这种情况,需要对数据进行统一的命名和处理。
在EXCEL中可以使用分页功能,将某一列按照特定的功能拆分。
【注意】:拆分数据会覆盖其他列数据,因此要将需要拆分的数据列放在最后一列。
3.5.1 将要拆分的数据列复制到最后一列
步骤:选中需要拆分的列–>右键点击复制–>在最后一列进行粘贴。具体操作如下:
【注意】将原始列复制后,原始列就用不到了,需要进行隐藏。
3.5.2 数据分列
步骤:选择数据选项卡–>点击分列–>选择分隔符–>确定分隔符号(勾选其他,并键入分割符号)–>点击下一步–>选择需要拆分的区域–>点击确定即可。具体操作如下:
分列后数据如下:
3.5.3 常用函数
在对数据进行一致化处理时,也会用到一些函数,下面就来介绍一下Excel中的常用函数。
3.5.3.1 常用的函数:平均值
有一些数据本身无法进行运算,但是可以转化成可以计算的形式,比如本案例中的“薪水”,我们可以对该列进行拆分,拆分成最低薪水,最高薪水,进而求出平均薪水,但是我们使用Excel要怎么处理呢?
步骤1:在后面空白列建立三列:最低薪水,最高薪水,平均薪水;用于存放薪水数据清洗后的清洗数据
步骤2:使用分列功能,以“-”作为分隔符进行分割,分成最低薪水与最高薪水
步骤3:利用删除和替换功能,将k进行删除
步骤4:使用AVERAGE()函数求的平均薪水
(1)选择average()函数
(2)选择函数要输入的数据,并得到输出结果
(3)也可以直接在单元格使用函数,结果与上述操作相同。
【注意】如果在计算平均薪水时,出现“零除错误”可能原因如下:
(1)数据中空白单元格被当作了零处理
(2)部分单元格数据是数字型字符串,不能参与运算。
那么如何将字符串形式的数字,转化为数字呢?步骤如下:
3.5.3.2 常用函数:查找和字符串截取函数
【1】查找函数–find
【2】截取函数
find函数一般配合截取函数一起使用。
具体操作如下:
针对本案例,计算最低薪水和最高薪水的具体操作如下:
计算最高薪水计算最低薪水【注意】这么计算完结束了吗?显然不是,我们要对拆分的数据进行检查,看是否有错误。具体操作如下:
【1】按条件筛选,看是否有值错误
“#VALUE!”则表示有值错误
【2】查找错误的值是什么?所属原因?
发现:1:薪水的“k”是大写,需要使用替换功能将“K” 转换为“k”
2:薪水列没有最大薪水。比如薪水为“15K以上”,需要将最大薪水也定义为15K
【3】使用替换功能将“K” 转换为“k”
【4】将没有最大薪水的数据,最大薪水定义为与最低薪水相同
【5】再去查找是否有值错误,直至无错误为止(筛选的过程要做多次)。
3.6 数据排序
数据经过排序以后,可以帮助我们看多更多有用的信息。以平均薪水排序为例:比如想知道数据分析行业中拿到的平均薪水最高是多少?此时我们可以对平均薪水进行降序排列【从大到小排列】。具体操作如下:
发现:数据分析师岗位平均薪水最高为75K。
3.7 异常值处理
由于异常值处理需要用到数据透视表的功能,因此首先对数据透视表进行讲解。
3.7.1 分组汇总:数据透视表
数据透视表的原理:(1)数据分组(split):按照某种规则对数据进行分类
(2)应用函数(apply):对分组后的数据进行操作(求平均值,最大值,标准差等)
(3)组合结果(combine):将应用函数的计算结果进行汇总
下面以一个例子来具体描述:
假设有从法国起飞的一航班的信息表,包括目的地,到达延误时间以及距离,具体数据如下:
求:航班航行距离与到达延误时间的关系?我们使用数据透视表来解决此问题
【1】数据分组:将数据按照目的地分为“北京”,“上海”两组。
【2】应用函数:分别计算平均延误时间与平均距离
【3】组合结果:将北京和上海的结果进行汇总
那么如何使用Excel来进行数据透视表的操作呢?具体步骤如下:
对应到数据透视表的原理如下:
3.7.2 异常值处理
通过数据透视表的排序功能来查看哪些职位名称出现的次数最多?
因为我们爬取的是数据分析师的招聘岗位信息,如果职位名称不是数据分析师,就可称为是“异常值”,需要进行删除。具体步骤如下:
步骤1:将数据分析师职位的数据查找出来(新增数据分析师职位名称列;将属于数据分析师的定义为“是”,非数据分析师的定义为“否”)
步骤2:利用筛选功能将值为“是”的筛选出来。
四、数据分析或构建模型
该部分数据分析内容主要是明确问题部分中业务部门给我们的业务指标。主要是使用Excel的数据透视表来分析。
4.1 问题1:在哪些城市找到数据分析师工作的机会比较大?
【明确问题】:不同工作年限的招聘岗位数量分别是多少?
步骤1:使用城市进行数据分组,放在行标签步骤2:应用函数选择计数,放在值标签步骤3:将工作年限放在列标签步骤4:按照计数进行降序排列,即可获得汇总结果具体步骤如下:
【排序】
本案例得到结果如下:
【注意】:我们发现直接从总数上还不能较为清晰的展示每个城市的数据占比情况,那需要怎么做呢?—使用百分比展示会是一个比较好的选择。具体步骤如下:
步骤1:点击值显示位置,点击值显示方式步骤2:选择列汇总的百分比(值显示方式有多种,实际工作中根据自己的需求选择即可)步骤3:点击确定即可具体操作步骤如下:
本案例得到结果如下:
通过表格发现:
【1】从招聘城市来看:
1、全国数据分析师的人才需求将近一半需求是在北京,位居全国第一2、全国数据分析师人才需求位居前五的城市为:北京,上海,深圳,广州以及杭州;几乎占据了全国数据分析师人才需求的80%以上。【2】从工作年限来看:
1、对工作年限为1-3年的熟手需求是最大的,3-5年的次之。说明数据分析师是一个比较年轻的工作方向,大部分招聘需求集中在1-5年。4.2 问题2:平均薪水的描述统计如何做?
4.2.1 按照分析工具库
在做描述性统计分析前,Excel需要先安装数据分析工具库。
安装步骤:打开文件—>选择选项–>选择加载项–>点击转到–>勾选分析工具库–>点击确定即可。
具体操作如下:
4.2.2 使用分析工具进行描述性统计分析
描述性统计分析主要指标:平均值,四分位数,标准差,标准分等。不清楚的同学可以查看我上节的02-描述性统计分析。
使用Excel做描述性统计分析的步骤如下:
本案例具体结果如下:
根据表格结果发现:
1、从整体趋势来看:各城市平均薪水为14.35K,位于中间位置的薪水为12.5K,职位最普遍的薪水为15K。从这平均值,中位数以众数三个指标来看,薪资基本持平2、从薪资浮动情况来看:各城市的浮动薪资还是较大的,最小值为1.5K,最大值75K,标准差达到7.39K之多。4.3 问题3:数据分析师的薪水如何?
步骤1:使用城市进行数据分组,放在行标签步骤2:按照平均薪水进行取平均值,放在值标签具体操作步骤如下:
本案例具体结果如下:
发现:
1、深圳的数据分析师岗位平均薪资最高,约为15.31K,其次是北京,上海,杭州,苏州等4.4 问题4:根据不同的工作经验,薪水是如何变化的?
步骤1:使用工作年限进行数据分组,放在行标签步骤2:按照平均薪水进行取平均值,放在值标签本案例结果如下:
发现:
1、随着经验的提升,数据分析师的薪酬也在不断增加2、从该组数据来看,数据分析师是一个比较年轻的职业方向,并且在10年内大概率不会因为年龄的增长而导致收入下降,反而还会有一个比较可观的涨幅。五、数据分析—原来还有这些
本节主要针对一些数据分析中用到额外数据处理方法进行介绍。包括日期数据如何处理;多表如何进行关联查询以及三种引用方式。
5.1 日期起数据如何处理?
日期数据的处理也是经常会出现在我们的日常生活中。由于统计来源的不同,或者记录人员的差异会导致日期格式多种多样。这就需要进行日期格式统一,以免对数据分析结果造成影响。
假如给定这样一个某公众号数据表格,包括标题,日期与当日涨粉量,数据如下:
我们发现:日期这一列,形式多样,没有统一的格式,会导致后续数据分析时不方便。因此有必要对日期数据进行处理。步骤如下:
第一步:选中日期这一列
第二步:点击数据选项卡–>分列–>选中分割符号–>选中Tab键–>点击下一步
第三步:在文本分列导向卡下选择“日期”,格式顺序为“YMD”(表示年月天的日期格式)
发现日期列还有格式不准确,还需要第四步。
第四步:选中日期列–>右键选择设置单元格格式–>通过自定义“yyyy/m/d”–>点击确定即可
此时日期列就变成了统一的格式。
5.1.1 案例分析
表格中数据描述的是公众号每天的涨粉量,那如果想知道如果想知道每个月涨粉多少;以及用户想看出最近几个月涨粉量的变化趋势?这个时候要怎么进行分析呢?如何使用透视表来实现该需求呢?
【问题1】:每个月涨粉量分别是多少?
第一步:选中数据–>选择插入选项卡–>创建透视表
第二步:按照日期进行分组,拖至行标签;将当日涨粉量的求和作为值,拖至值标签
发现:此时得到的数据透视表统计还是按照天来统计的,不是按月统计的。需要进行以下步骤
第三步:在日期列任选一单元格–>点击右键–>在菜单栏中选择创建组–>在组合窗口中,选择年和月–>点击确定
本案例计算结果如下:
如果按照周汇总,需要怎么操作呢?
【问题2】:每个周涨粉量分别是多少?
相比计算每个月的涨粉量,只需要将第三步进行修改。在组合时设置终止日期,步长设置为7天,点击确定即可
本案例得到结果:
【问题3】:每个月的最大值是多少?
第一步:选中数据–>选择插入选项卡–>创建透视表第二步:按照日期进行分组,拖至行标签;将当日涨粉量作为值,拖至值标签第三步:点击值(下三角)按钮,弹出值字段设置对话框,选择计算类型为最大值即可(后续可以根据自己的分析需要选择合适的计算类型)【问题4】:每个月涨粉量的变化趋势。
该问题可以通过统计每个月的涨粉量,然后按照时间绘制折线图即可,这部分内容会在下节可视化章节来讲解。
5.2 多表关联查询–vlookup函数
如果有多张表时,如何将一张表匹配到另一张表中呢?这时就需要使用vlookup函数。该函数可以按照条件查找出数据,极大提高工作效率。
5.2.1 vlookup
vlookup函数有4个参数:
vlookup(找什么,在哪找,第几列,是准确找还是近似找)vlookup有两个功能,分别是关联查询与数据分组。
5.2.2 案例分析1:两表关联查找
假设有两张表,分别是表2三好学生表(记录了三好学生的姓名),表1学生信息表(记录所有学生的学号,姓名,出生年月,性别以及班级等信息)。现在想知道三好学生表学生中对应的班级,这使用Excel要如何操作呢?
我们发现姓名和班级都出现在表1中,因此要想知道三好学生表学生中对应的班级,就需要将表2中的姓名作为连接条件,在表1中找到三好学生对应的班级即可。理论步骤如下:
第一步:找什么;表示三好学生对应的班级(比如猴子属于哪个班级)第二步:在哪找;因为班级在表1中,所以要在表1中进行查找;结果发现有在两个班中有猴子,故找到了两行数据第三步:在第几列;发现班级所在列是E列;两行数据一个是1班一个是3班第四步:是准确找还是近似找;准确找为0,近似找为1;准确匹配是从头开始查找,查找到即停止,返回第一个找到的值;模糊匹配则是查找所有的值,返回最后一个找到的值使用Excel的操作如下:
第一步:选中班级列B2单元格–>选择公式选项卡–>插入函数–>搜索函数vlookup—>转到–>点击确定
第二步:找什么
第三步:在哪找
第四步:在第几列
第五步:是准确找还是近似找;准确找为0,近似找为1
【注意】:我们在使用vlookup时,发现该函数有个弱点,就是无法查找重复值。那如果遇到有重复值的情况,需要怎么操作才能都找出来呢?步骤如下:
第一步:在表1前加入辅助列,将姓名和学号联合起来作为非重复的唯一字段
&:可以将两个字符串拼接在一起5.2.3 如何对数据分组?
根据每个月的消费情况,对消费进行分组(高消费,中消费,低消费),如何对其进行分组呢?—使用vlookup 来实现。数据如下:
第一步:在表中建立分组定义(三组消费各自的区间范围,将每一组区间范围的最小值作为阈值)第二步:在数据分组列插入vlookup函数,设置四个参数。注意:分组时第四个参数选择1(近似查找),因为这里操作的是一个范围。第三步:第二个参数,在哪找;注意要设置绝对引用(按F4可以将相对引用变为绝对引用)5.3 三个引用
三种引用方式的快速替换
