







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
3分钟带你了解流式数据架构基本概念(实时流式大数据处理实战pdf)
 2023-11-18
2023-11-18 浏览次数:次
浏览次数:次 返回列表
返回列表1 流
流(streaming)是一种为无界数据集设计的数据处理引擎,这种引擎具备以下特征:
具备强一致性,即支持exactly-once语义。提供丰富的时间工具,如事件时间、处理时间、窗口等。保证系统具有可弹性、伸缩性。同时保证高吞吐、低延迟与容错。支持高级语义,如流式关系型API(SQL)、复杂事件处理(CEP)2 时间
在无界数据处理中,主要有两类时间概念:
事件时间(Event Time):事件实际发生的时间。处理时间(Processing Time):事件被处理的时间。在现实世界里,事件时间和处理时间往往并不一致,两者的偏差也因数据源特性、处理引擎、硬件差别而千差万别,这种变化给处理引擎的设计带来了不小的挑战。
3 窗口
窗口是将(有界或无界)数据集拆分成一个个有限长度数据区间的机制,用于将事件按照时间或其他特征分组分析。通常有三类窗口:
滚动窗口(Tumbling Window)
将时间拆分成固定长度。
滑动窗口(Sliding Window)
按照滑动步长将时间拆分成固定的长度。当滑动步长小于窗口长度时,相邻窗口间会有重叠。
会话窗口(Session Window)
以活动时间间隔为边界,将一系列连续时间拆分到不同的会话中。会话窗口的长度是动态的。
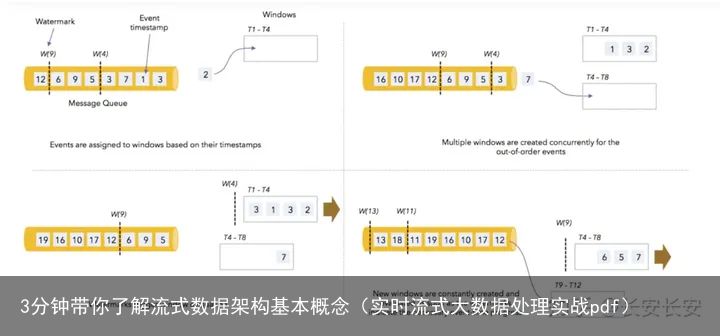
4 水印
水印(watermark)是嵌入在事件时间轴上用于判断事件时间窗口内所有数据均以到达引擎的一种时间推理工具,是一种既可以在流处理侧嵌入,又可以在消息系统侧嵌入的时间戳。
水印的语义是事件时间小于水印标记时间的事件不会再出现,在遇到水印后,会将事件时间小于水印时间的事件执行,因此水印是事件的推进器。
5 触发器
触发器(trigger)决定在窗口的什么时间点启动应用程序定义的数据处理任务。
水印迟到会拉长窗口生存周期,水印早到会导致数据处理结果不准确,触发器就是为了解决这两个问题而被引入的。
6 数据处理模式
有界数据处理
通常使用批处理引擎处理有界数据集(尽管流处理引擎也具备这个功能)。
无界数据批处理
在流处理引擎没有出现之前,业界通常使用窗口机制将无界数据集分割成一系列有界数据块,使用批处理方式分析每个数据块,即微批处理模式
无界数据流式处理
基于微批模式的无界数据批处理的原理是,将多个微批处理任务串接起来构建流式数据处理任务,这通常是以牺牲延迟和吞吐为代价的。解决这个缺陷是流式处理引擎的发展目标之一,解决方案建立在分析无界数据集的无序和事件时间偏差特性的基础上。
无序意味着引擎需要时间处理机制事件时间偏差意味着引擎不能假定在某个时间窗口内能观察到所有事件。7 如何理解流式数据架构的内在机制
可以通过以下4个问题来深入理解流式数据处理的内在机制。
what:定义数据处理是什么,即对数据进行怎样的转换操作,如Spark的算子。where:定义转换操作的输入数据取自什么时间区间,窗口是这个问题的答案。when:定义转换操作发生在时间轴的什么时间点,水印和触发器是这个问题的答案。how:定义如何刻画同一窗口内多次转换操作结果的关系,累计模式是这个问题的答案。参考资料:《深入理解Flink 实时大数据处理实践》
