







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据之道 | 属性图在增强分析平台中的实践(图形数据和属性数据的区别)
 2023-11-22
2023-11-22 浏览次数:次
浏览次数:次 返回列表
返回列表
供稿 | eBay DSS Team
作者 | 唐明君
编辑 | 顾欣怡本文5447字,预计阅读时间17分钟更多干货请关注“eBay技术荟”公众号导读
本文为“数据之道”系列第三篇,主要介绍属性图在eBay数据增强分析平台Nous上的部分应用,包括数据导航、数据血缘分析等。通过构建属性图,并基于图进行搜索和查询,我们可以有效解决增强分析中的各种问题,这种基于图的数据分析方式也值得学习和推广。
序
数据分析在如今的商业和技术领域是不可缺少的,它被广泛地应用在工业、市场、投资、人才等方向。通过数据分析,我们能够更好地了解现有业务,指导商业决策,做到心中有数。
eBay作为互联网电商巨头,其数据分析的地位尤其重要。eBay有大量的数据分析师和数据科学家,每天使用各种各样的方法进行数据分析,这些方法包括传统的BI分析和增强分析(augmented analytics),建立的分析模型包括各种规则模型(rule based model)和基于机器学习的模型(machine learning based model)。不仅如此,eBay还将自己的数据分析能力赋予用户,帮助买家和卖家更好地进行商业交易。
Nous作为eBay的数据增强分析平台,给客户提供了各种强大的数据分析功能,帮助他们轻松地探索业务发展的关键指标,并做出正确且及时的商业决策。在传统BI工具的功能基础上,我们提供了基于自然语言处理和属性图的搜索入口,以及让客户可以轻松整合指标并高度可定制化的故事白板,还有基于时间序列数据及机器学习模型的数据洞察分析。其中,基于属性图的搜索和查询在增强分析中扮演了非常重要的角色,也正是本篇文章的重点。
本文将依次介绍属性图的涵义,Nous与属性图,基于属性图的搜索和查询,以及一些具体的应用,例如数据导航、数据血缘分析等。同时,文中涉及的eBay信息都已经过脱敏处理。
一、属性图简介
属性图是一个有向的多重图,图上的边和节点带有用户定义的属性。一个属性就是一个自定义的key-value之间的一一对应。一个有向多重图首先是一个有向图,也就是说边是有方向的。其次边可以是多重的,相同的起始节点和结束节点之间可以有多条边。支持多重平行边的好处,就是很多场景的模型里相同节点之间都有着多重关系。举个例子来说,鲁迅和许广平之间的师生关系是一条边,同时他们也是恋人关系。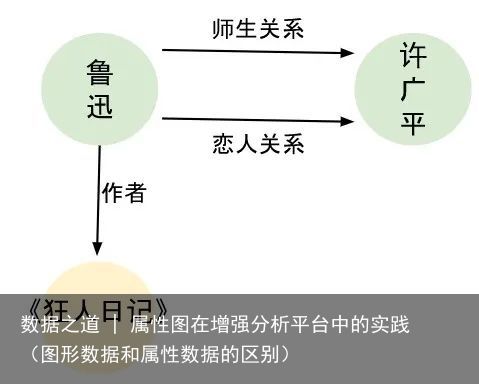 节点上的属性描述的是节点的性质,比如人的年龄、性别、产品的生产日期、商品的价格、猫的颜色等等。同理,边上的属性描述的是边的性质,比如账户之间转账的金额,运动员之间胜负的场次数,某台机器完成某个任务需要的时间等等。同时,每个节点会有一个唯一标识符,以此来和其他节点进行区分。然而,节点之间是无序的。无序意味着当按照一定条件筛选出一些节点之后,这些节点之间是没有隐含顺序的,除非额外对这些节点按照某些属性进行排序。边的唯一性则是由起始点、结束点和关系的类型确定的,可以记作 edge=(source, target, edge_label)。当然,一条边的起始和结束也可以是另一条边的结束和起始,比如父亲到儿子的父子关系是一条边,儿子到父亲的子父关系也可以是另一种类型的一条边。注意,即使类型相同,(n1,n2,type)和(n2,n1,type)也是不同的边,例如(丈夫,妻子,夫妻关系)和(妻子,丈夫,夫妻关系)是不同的边。从之前的例子可以看出,在同一个图的模型中,不同的节点属于多个类型是很自然的。比如鲁迅这个节点的类型是老师,许广平这个节点的类型是学生。这里的老师和学生就是不同的类型。同时边也可能是不同的类型,描述不同的关系。尽管边是有方向的,但大多数的图数据库系统和图计算引擎都支持从不同的方向扩展边,且性能上可能有比较大的差距,和当前节点的出度相关。以美剧《生活大爆炸》中的人物为例,一个可能的属性图如下所示:
节点上的属性描述的是节点的性质,比如人的年龄、性别、产品的生产日期、商品的价格、猫的颜色等等。同理,边上的属性描述的是边的性质,比如账户之间转账的金额,运动员之间胜负的场次数,某台机器完成某个任务需要的时间等等。同时,每个节点会有一个唯一标识符,以此来和其他节点进行区分。然而,节点之间是无序的。无序意味着当按照一定条件筛选出一些节点之后,这些节点之间是没有隐含顺序的,除非额外对这些节点按照某些属性进行排序。边的唯一性则是由起始点、结束点和关系的类型确定的,可以记作 edge=(source, target, edge_label)。当然,一条边的起始和结束也可以是另一条边的结束和起始,比如父亲到儿子的父子关系是一条边,儿子到父亲的子父关系也可以是另一种类型的一条边。注意,即使类型相同,(n1,n2,type)和(n2,n1,type)也是不同的边,例如(丈夫,妻子,夫妻关系)和(妻子,丈夫,夫妻关系)是不同的边。从之前的例子可以看出,在同一个图的模型中,不同的节点属于多个类型是很自然的。比如鲁迅这个节点的类型是老师,许广平这个节点的类型是学生。这里的老师和学生就是不同的类型。同时边也可能是不同的类型,描述不同的关系。尽管边是有方向的,但大多数的图数据库系统和图计算引擎都支持从不同的方向扩展边,且性能上可能有比较大的差距,和当前节点的出度相关。以美剧《生活大爆炸》中的人物为例,一个可能的属性图如下所示: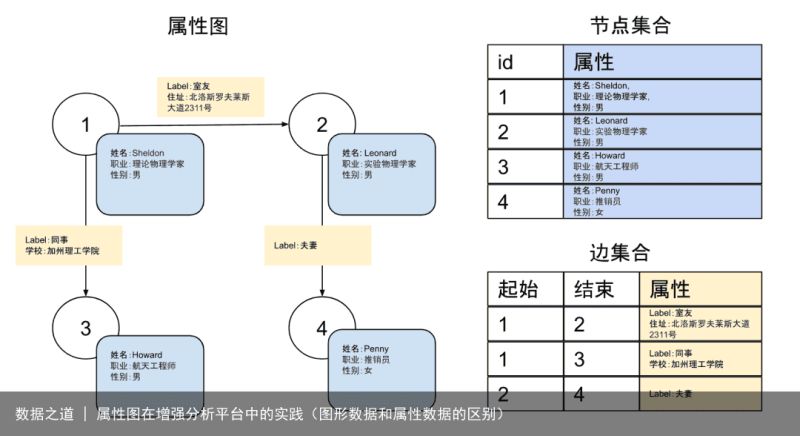 图1(点击可查看大图)我们知道,SQL有关系代数作为数学基础,属性图也有相应数学基础,以便进行标准化和证明推理等。因此,在对属性图有一个大致的了解之后,让我们一起来看下属性图的数学定义。以下是参考文献[1]中的定义原文:
图1(点击可查看大图)我们知道,SQL有关系代数作为数学基础,属性图也有相应数学基础,以便进行标准化和证明推理等。因此,在对属性图有一个大致的了解之后,让我们一起来看下属性图的数学定义。以下是参考文献[1]中的定义原文: 图2 来自参考文献[1](点击可查看大图)
图2 来自参考文献[1](点击可查看大图)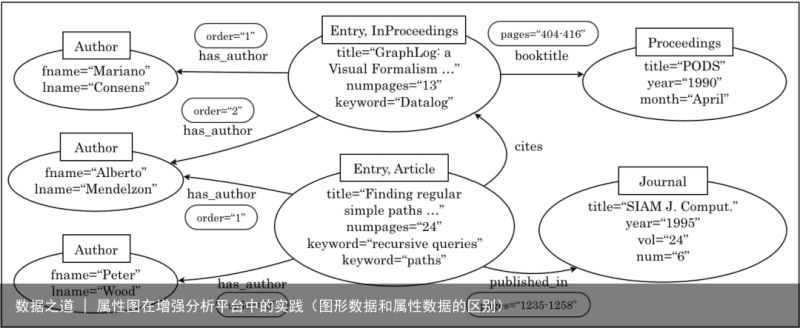 图3 来自参考文献[2](点击可查看大图)
图3 来自参考文献[2](点击可查看大图)
According to the definition, we have

图4(点击可查看大图)
关于属性图的代数模型,详见参考文献[2],本文就不赘述了。目前支持属性图的图数据库有neo4j, JanuasGraph,同时还有一些支持离线批任务的图计算引擎,比如Spark GraphX等(详见参考文献[3][4][5])。二、Nous与属性图
在eBay的增强分析平台Nous中,我们使用的是一个多标签的属性图,不同的标签代表了不同类型的节点和边。在实现中,我们采用了Neo4j作为Nous的图数据库系统。
我们根据eBay的业务抽象出了不同的标签:Metric 指标,通常是时间序列的数据,比如电商网站的销售量等Dimension 维度,指标的维度,比如地区,国家等Dimension value 维度值,维度的具体某个值,比如中国,美国等Table 数据平台中的一张表Column 表上的columnMetric_formula 指标的计算法则,加减乘除聚合等Domain 不同的业务领域每个标签的节点有不同的属性,同时根据节点之间的关系抽象出不同类型的边。Has_metricDomain到相关Metric的有向边Has_columnTable到包含的Column的有向边…每条边也有不同的属性。下图是使用neo4j进行visualization得到的属性图:
图5(点击可查看大图)
下图表明的是节点和边上的属性: 图6(点击可查看大图)好了,现在我们已经构建好了属性图,接下来我们看下Nous是如何基于此实现搜索、查询功能的,以及它们是如何解决增强分析场景中的各种问题的!
图6(点击可查看大图)好了,现在我们已经构建好了属性图,接下来我们看下Nous是如何基于此实现搜索、查询功能的,以及它们是如何解决增强分析场景中的各种问题的!三、属性图的搜索
我们可能都使用过web search(网页搜索),例如Google, Bing。但是,基于属性图的搜索和web search不一样,它更类似于eBay网站上的item search(实体搜索)。搜索的结果不是网页的列表,而是一个一个的实体,或者说item。举个例子,我们搜索白色的iphone,出现的结果是iphone的列表。
图上的搜索定义为:基于文本的输入,搜索的结果是一个子图,包含输入的约束条件。属性图分析的场景为什么需要搜索呢?一是给分析师提供友好的接口进行数据的模糊探索,便于缩小范围,定位到相关的节点或者子图。二是不同于严格的规则引擎,搜索的结果具有一定的启发性,同时根据相关度和重要程度有排序。因此,搜索可以用在规则引擎之前供分析师做业务探索。那么图上的搜索和查询有什么区别呢?主要从输入和输出看:输入的区别搜索的输入是自然语言文本,例如gmv on us site, 结果是us site上名字里有GMV的metric。图查询的输入是规范定义的DSL,例如:SELECT n.name FROM MATCH(n)-[:has_friend]->(m)GROUP BY n HAVING COUNT(m)>10,结果是朋友数大于10的人。
输出的区别搜索的结果是有序的,这个排序可以是基于规则的,也可以是通过机器学习训练的,且一般来说输入的约束条件之间是“或”的关系。查询的结果则需要严格满足输入的约束,结果默认不排序,当然也可以按某些字段排序。对图搜索有了一些直观的认识之后,让我们来尝试进行数学定义:
图7(点击可查看大图)
以生活大爆炸的属性图为例,一个可能的搜索是:和Penny有关的女性理论物理学家。如果是查询,结果集为空,因为约束条件是女性。而搜索的结果为:Sheldon和Leonard,Sheldon排序更高,因为他满足条件里的理论物理学家,而Leonard是实验物理学家。一个high level的流程图如下:
图8(点击可查看大图)
以搜索gmv on us site为例,流程图中的数据结构如图9所示: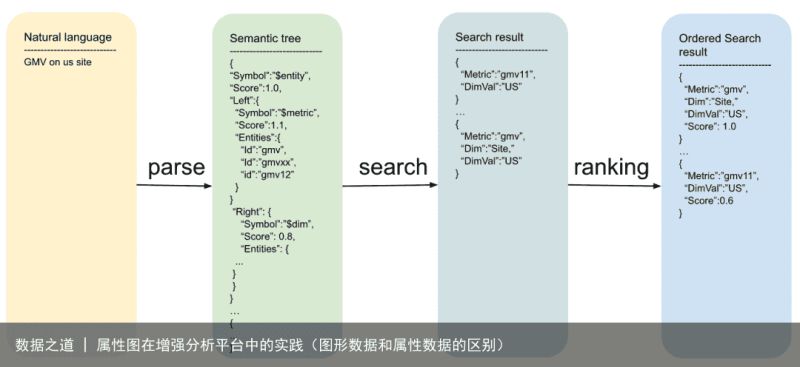
图9(点击可查看大图)
Parser会负责基本的自然语言解析,包括句子划分(Segmentation),词性还原(Lemmatization),词干提取(Stemming),命名实体识别NER,CFG语法(Context Free Grammar)解析等。举例来说,GMV on United States的句子需要划分成GMV | on | United States的三个部分,United States两个词组成一个部分。鉴于用来搜索的句子都比较短,我们采用了遍历的方法进行划分。词性还原承担的工作类似于将does,doing还原成do,was还原成be等。词干提取会将effective提取成effect等。在实现过程中,我们借助Apache Lucene配置lemmatizer和stemmer来进行词性还原和词干提取。同时,大量的专有名词(缩写或者几个词表示一个实体,例如GMV)需要被识别出来。在有完整的专有名词字典的情况下,我们基于Elasticsearch搜索来进行命名实体识别。语法解析的核心算法则采用了CYK算法。关于Parser的源码,eBay内部感兴趣的同学可以参考:https://github.corp.ebay.com/mingjtang/cfg-parser.git
经过Parser的解析,用户的输入会转化成一个语义树的列表(森林),语义树上的叶子节点对应属性图上的节点或者边。Engine负责将语义树转化成图的查询,抽取出语义树中的节点和边,根据语义生成对应的属性图查询语言提交到图数据库上进行查询,每一个查询的结果都可能是多个符合条件的子图。因此需要将语义树森林查询得到的所有子图进行融合和去重。由于语义树的列表可能会比较大,考虑性能,我们进行了启发式的剪枝。Ranker会对上一步得到的所有子图进行排序,这里使用的是pointwise的排序算法,每个子图有一个单独分数。这个分数是通过属性图上节点和边的name属性生成文本,计算生成文本和用户输入文本的文本相似度得到。同时,基于对用户的搜索点击日志进行分析,抽取出特征,例如语义树的节点数,结果子图的节点数等,使用XGBoost训练回归树模型,持续提高排序的质量。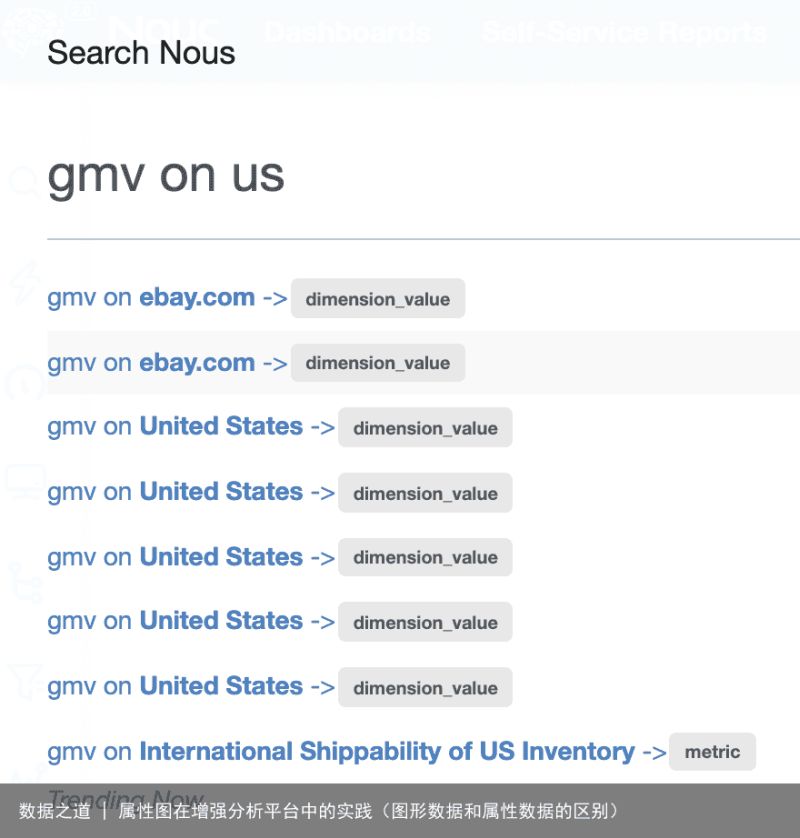
图10 来自参考文献[6]
(点击可查看大图)
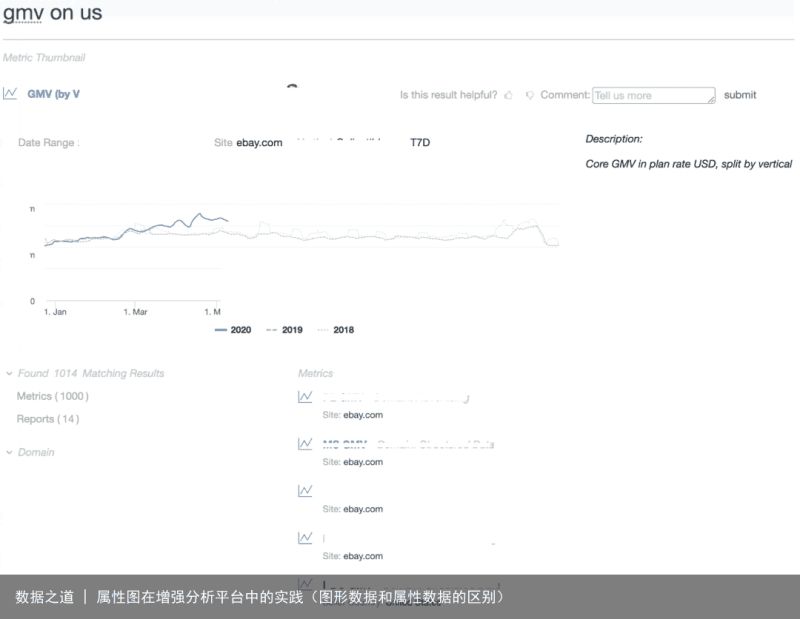
图11 来自参考文献[6]
(点击可查看大图)
基于图结构的搜索能力十分强大,可以实现很多业务场景的问题。举个最近的例子,比如防疫的案例中,某中年男子在德国中心工作,最近14天到过重点地区,家庭成员或同事中也有人在最近14天里到过重点地区。结果是符合一条或多条约束的节点,家庭成员和同事都是图上的边的约束。四、属性图的查询
4.1
查询语言
作为一个图数据库,查询是基本需求。基于关系代数的关系型数据库有标准化的查询语言SQL,其实在图数据库领域,基于属性图的模型也有相应的查询语言,主要分为两类查询语言:一类是基于过程的traverse的API,代表有gremlin。这类查询多半是函数式,数据流的语言,需要指定traverse的过程。
图12 来自参考文献[7]
(点击可查看大图)
另一类是声明式的语言,其中有neo4j的cypher[8], oracle的PGQL[9]等。这类语言设计思路参考SQL,关注查询目标而非过程,降低了使用的难度,更加适合分析场景使用。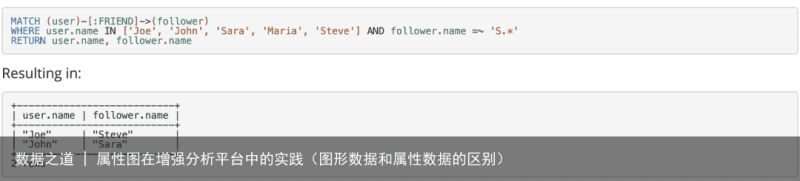
图13 来自参考文献[8]
(点击可查看大图)
值得一提的是,目前属性图上的各种查询语言各自发展,群雄割据,对SQL的支持也百花齐放。基于此,ISO SC32/ WG3 members于2017年开始提出构建基于SQL的统一的图查询语言。2018年5月,GQL宣言正式发布,开放投票。2019年9月,GQL正式成为官方的ISO database language,是SQL之后30多年来的第一个。目前,GQL还处在早期阶段,相信随着数据中心计算能力的增进,以及越来越多的图计算需求,降低图查询的门槛会越发重要,GQL也会在不久的将来大放异彩,在图计算系统中扮演一个重要的角色[10]。
4.2
数据可视化
尽管有了可用的查询语言,但我们依然需要对查询的结果进行一些可视化。可视化的用户可能是精通业务但不善于编程的分析师或者业务专家。也有可能是需要直观地在图上作一些数据探索的用户,比如查看某个IP地址有哪些终端使用过,或者复杂一点的情况:选中两个账户,查看账户之间有哪些可能的关系,例如转账关系或者账户主之间存在亲属关系。总之,可视化为业务探索、提炼业务知识提供了直观的体验。下表中列举了一些支持图数据可视化的工具:图14(点击可查看大图)
下图是Graphexp可视化的样例:图15 来自参考文献[11]
(点击可查看大图)
在Nous中,我们采用了Neo4j开源社区的可视化工具:图16(点击可查看大图)4.3
图查询应用
4.3.1
数据导航
在增强分析平台Nous的场景中,例如分析师这样的用户更聚焦在业务上,而不是关心数据在什么表,怎么取。分析师或者产品经理之间沟通业务使用的也是metric,而不是具体的table/column等。数据导航负责将业务上的metric/dimension等等导航到具体的table/column,方便后续使用SQL engine查询和计算需求的数据,为用户屏蔽了底层查询的复杂度。底层查询的复杂度体现在:大量的表,用于分析的数据库表可能有成千上万张;不同的数据平台,分析所需的数据可能来源于各种不同的平台,例如:Kylin/Hive/Mysql/Elasticsearch等等,甚至是各种data services;
数据可能存在冗余,比如同样的数据在Kylin和Elasticsearch上可能都有(面向的业务场景不同),怎样选取最佳的数据源读取数据进行分析是一个复杂的问题。
我们分两步来解决这个问题。第一步,查询所有可能的计算路径,比如相关的table和column。例如,用户需要知道US Site上的GMV(Gross Merchandise Volume, 一段时间内的成交总额)。首先,我们根据Metric=GMV,Dimension=Site,Dimension Value=US查询相关的table和column。查询如下:图17(点击可查看大图)
查询结果如下:图18(点击可查看大图)
从图18中可以看出,可行的计算路径有多个。第二步,在所有可能的路径中,根据规则和成本,选取最优的计算路径。这个规则可以根据平台、响应速度、表数据质量和更新频率等来决定。
4.3.2
跨平台Join查询优化
上面的例子是所需的数据可以在同一张表中查询。如果将分析限定在同一张表上,就会极大限制分析的能力。而分析中尤为重要的一环就是建立联系,包括建立业务的联系,建立数据的联系。因此,跨平台跨数据库随用随取地获取数据,是一个分析平台非常重要的功能。Nous提供了多元异构数据的分析能力,其中跨平台的join路径优化是非常典型的图计算的场景。图19(点击可查看大图)
如图19所示,如果C1和C2在同一张表中,我们需要的query是SELECT SUM(C1) AS C GROUP BY C2。然而C1和C2散落在不同的平台上,且存在多个可能的查询路径。类似于数据导航,第一步我们找出可能的查询路径,查询如下:图20(点击可查看大图)
第二步根据Join的路径长短,以及相同平台优先等原则选取出最优的查询路径。最后生成SQL提交给Nous内的跨平台SQL查询引擎执行。生成的SQL类似于SELECT SUM(a.C1) AS name, b.C2 FROMMYSQL.DB.A aJOIN KYLIN.DB.B b ON a.FK1=b.FK1 GROUP BY b.C2
4.3.3
数据血缘分析
数据血缘分析也是增强分析中常用的方法。我们关心的数据都是从SQL表中计算得到的,这些SQL表之间有着千丝万缕的联系。比如产品经理关心的metric,metric是在ETL表的基础上通过一定的公式计算出来的。它们可能来自同一张表,通过filter,aggregation,join或者加减乘除等计算得到,因此这些metric之间有着天然的相关性,无论是正相关或者负相关。这些相关性可以用作metric趋势的预测或者metric异常时的归因分析。Data Lineage的构建需要借助SQL PARSE工具。SQL PARSER将ETL SQL和BI SQL解析,逐条分析出SQL中的table和column之间的依赖关系。将这些逐条分析出的关系构建成一个完整的关系图,图上的节点是table和column,边则是产生具体依赖关系的算子,Data Lineage关系图就构建完成了。图21(点击可查看大图)得到上述的血缘关系图后,有两种典型用法:找出两个metric之间有无血缘以及血缘的相关类型;找出一个metric血缘相关的所有metric,可以用于判断一个metric改变时哪些metric可能会受到影响。
下图是Nous中有血缘关系的两个metric,我们可以看到这两个metric的时间序列有很大的相似性,其趋势和异常都十分相似,比如这两个时间序列在二月底有一个同步的上涨和回落,这在时间序列中作预测和异常归因分析都很重要。图22(点击可查看大图)图23(点击可查看大图)
五、总结
本文主要介绍了属性图在增强分析中的部分应用。通过构建属性图,基于图进行搜索和查询可以解决增强分析中的很多问题,尤其边的引入能更自然地表示数据之间的联系,文中列举的应用场景也已经在eBay得到了验证。相信随着数据量的成倍增加和大数据处理技术的发展,基于图的分析方式也会越来越受大家的青睐,成为一个重要的可落地的分析手段。在基于属性图做增强分析的领域里,也还有很多内容值得大家一起去探索。
参考文献:[1] Joshua S., Ryan W., Algebraic Property Graphs,https://arxiv.org/pdf/1909.04881.pdf
[2] Renzo Angles, The Property Graph Database Model,http://ceur-ws.org/Vol-2100/paper26.pdf
[3] Neo4j, https://neo4j.com/
[4] JanusGraph,https://janusgraph.org
[5] Spark graphx, https://spark.apache.org/graphx/
[6] Nous, https://nous.corp.ebay.com/nous20/#/search[7] Gremlin, https://tinkerpop.apache.org/gremlin.html[8] Cypher, https://neo4j.com/docs/cypher-manual/current/introduction/[9] PGQL, https://pgql-lang.org[10] GQL, https://www.gqlstandards.org/home[11] GraphExp, https://github.com/armandleopold/graphexp
您可能还感兴趣:数据之道 | SLA/SLE监控与告警
重磅 | eBay提出强大的轻量级推荐算法——洛伦兹因子分解机
实战 | 利用Delta Lake使Spark SQL支持跨表CRUD操作
一探究竟 | eBay流量管理之DSR在基础架构中的运用及优化
干货 | Rheos SQL: 高效易用的实时流式SQL处理平台
分享 | “三高”产品设计的这些坑,你是不是也踩过?(上)
