![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
订单数据分析(订单数据分析报告范文)
 2023-11-26
2023-11-26 浏览次数:次
浏览次数:次 返回列表
返回列表首先,为了达到分析目的,我想要达到的效果是利用Python强大的数据处理功能结合业务逻辑,形成如pie chart tree一样的数据分流图像,就像一个(水)管网图,选择具有可操作性的特性作为数据分流的依据(节点),根据问题数据的分流程度,依次找出产生主要问题的节点并关闭,动用最少的资源解决最多的问题。当主要问题解决了,原来的次要问题会升至主要问题,这样一步一步把问题彻底解决干净。
由于报告是自动生成的,方便操作人员可以随时review自己的订单情况,早发现,早解决。
很多情况下,我们都是在凭感觉,常识在决策,但是通过数据分析有时你会发现事情原本比你想象的不一样,这也正是数据分析的有趣之处。此案例就是这个情况:)
现在开始在上节得到的数据基础上分析。
上节:
继续观察数据并清洗干净0 赞同 · 0 评论文章
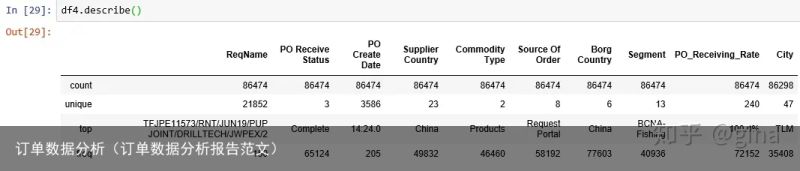
首先,用describe摸一下数据整体情况,由于数据都是文本类型的,描述中只出现了基数和频度的信息:
count是这列的行数,unique是唯一值得个数,top 是出现频率最高的内容, freq是出现频率最高的内容出现的频率(次数)
然后,你可以看出city这列存在数据缺失,数据共有86474行,显示城市的为86298行,缺失率约0.2%,比较小。
此次,通过segment可以看出下订单的部门一共13个,其中BCNA-Fishing这个部门最多在总条目86474行中就占了40936行。
再来看看订单收货率,全部收货的行数为72152,也就是说我们要解决的问题订单行数占比为16.6%。
这里的commodity type是购买产品的类型,products(产品)是最多的,占到52.6%
在这里我们可以做一个假设,按照常识既然订单最多的部门是BCNA-Fishing,那么这个部门也应该是问题订单行数最多的部门吧,TLM这个城市的订单最多,这样我们应该对TLM这个城市和BCNA-Fishing格外关注。
接下来, 我们看看事实上事情到底是不是这样呢?
首先选择问题订单为一个新子集: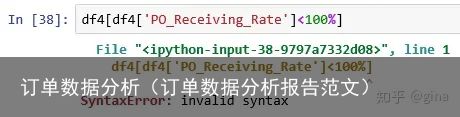
问题来了,直接选取出现了无效语法的问题,那么简化一些,看看问题出在哪里?
可见,选取这列是没有问题的,问题应该是dtype,我们需要把这series 从文本改成数字类型。
但是比较麻烦,我就把之前计算这列的代码做了如下修改:
df3[PO GR rate]=(df3[Received to Date Quantity]/df3[Quantity]).mul(100).round(1).astype(str)+% # before df3[PO_Receiving_Rate] =(df3[Received to Date Quantity]/df3[Quantity]).mul(100) # after之后选取就成功了:
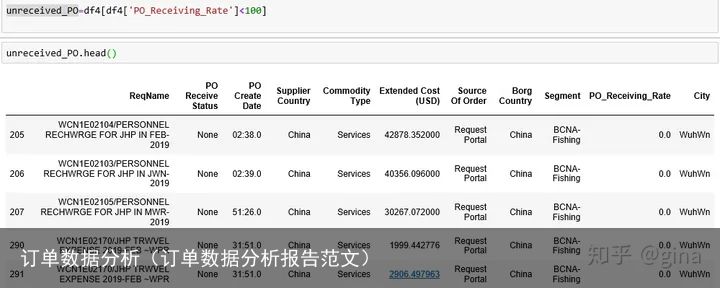
2. 分析问题子集
这里可以将选取好的问题子集用group by或者pivot按照不同的标准看看数据的集中程度:
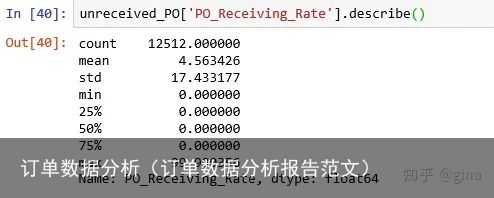
2.1 我们首先看看PO_Receiving_Rate这列数据的基本信息和分布:
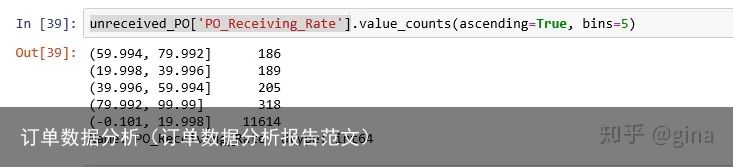
未收货订单的平均收货率为4.56%, 分位数都是0,说明部分收货的情况很少,未收货的大多数是全部未收的。
接着,我们按照收货率的不同,把数据分为5组,