







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
趣数据分析(趣 待遇)
 2024-01-18
2024-01-18 浏览次数:次
浏览次数:次 返回列表
返回列表目标:通过分析趣平台的创作者数据,总结出可以批量操作的项目。
1.首先抓取用户数据,这里指创作者。
趣的数据比较简单,userid直接暴露在外面,单纯的递归就可以了。
新注册一个账户就能看到最新的userid是多少,这里我们选取100w到235w之间的数据抓取,(100w之前数据量很少)。
2.这里我们先从视频数据开始分析(文章暂不考虑)。
找到获取视频的接口,简单看下得到的数据。
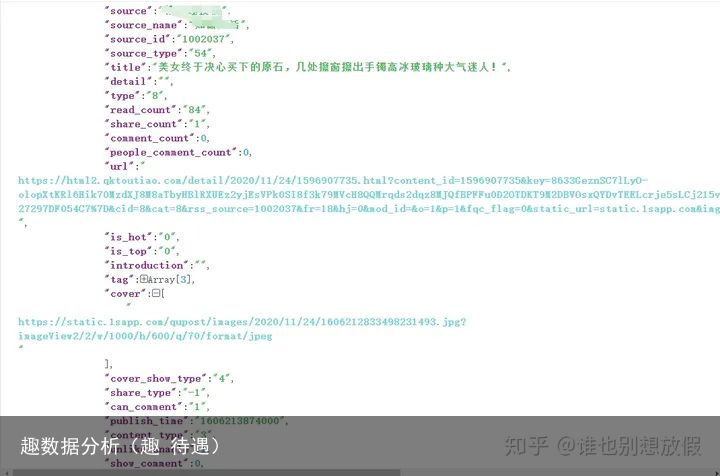
除了标题 作者 播放这些常规数据之外,我们重点关注一下publish_time这个参数,这里是时间戳,我们需要转换为常规时间然后保存。因为100w创作者我们需要大幅度的过滤,而最简单的过滤就是活跃度,你抓取他视频,看最新发布的是一年前,两年前发布的,这种账号还需要分析么,有价值么?自媒体的更新速度,都明白的。
于是 我们抓取到一系列数据,如下

约17w条数据,前面是作者id,后面是最新一期的发布时间。
3.然后继续过滤
根据获取到的日期过滤掉,
with open(video.txt) as file: data=file.readlines() print(len(data)) f=open(2020_11_video.txt,w+) for article in data: userId=article.split(----)[0] print(正在解析用户:%s%userId) date=article.split(----)[1] year=date.split(-)[0] month=date.split(-)[1] day=date.split(-)[2] if int(year)==2020 and int(month)==11: f.write(article) f.close()这里我们直接过滤掉率掉2020年11月之前的,得到了大概1w7的数据
4.批量
前面说过,我们需要找的是能批量操作的项目,所以,像那种一天只发布一条的,或者几天发布一条的显然不符合我们的要求。(当然,这里其实是另一种思路,每天发布一条,但是视频质量比较高,播放也就高的,这里后面再单独分析)
所以我们继续过滤,我们设置另一个条件,昨天发布视频数+今天发布视频数>10的(这里根据需求更改)。
于是,我们很容易就找到了这样的数据。
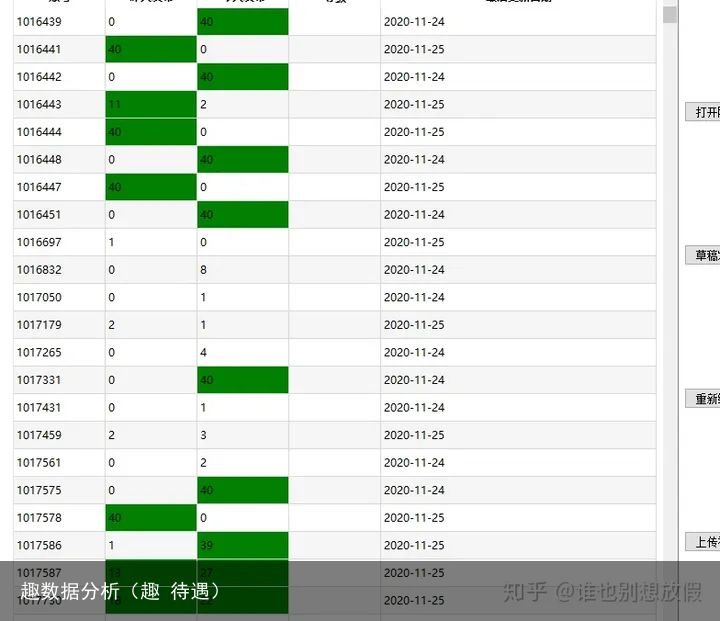
每天发布几十条,显然是批量操作的账号,我们看下具体的内容。
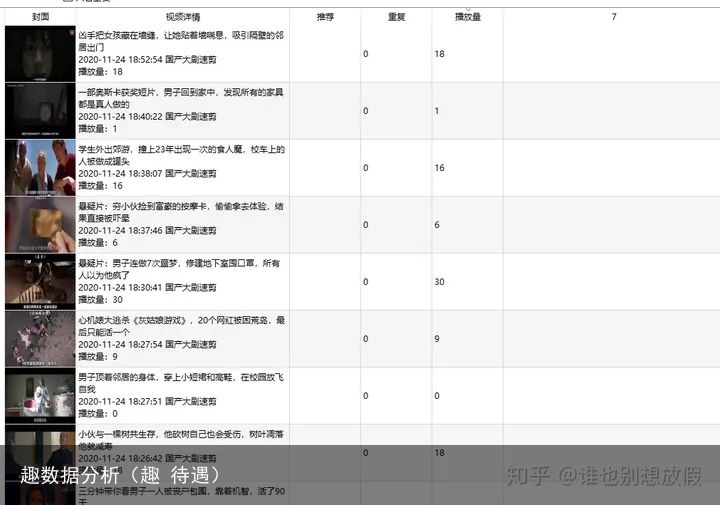
显然还是影视类的剪辑比较多。原因也比较明显,操作简单不说,部分是简单的切条,更多的应该是直接搬运的。但更明显的是,播放量是不尽如人意的。所以我们接下来需要做的就是,在这些每天发布几十条的账号中,找到播放量还高的套路。
例如:
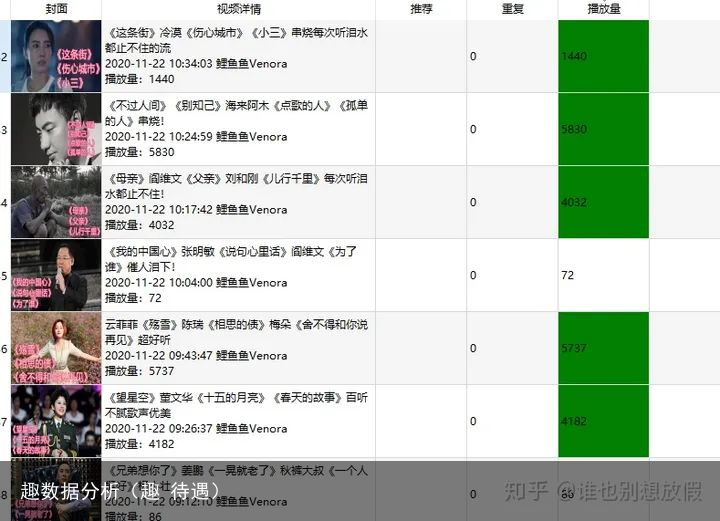
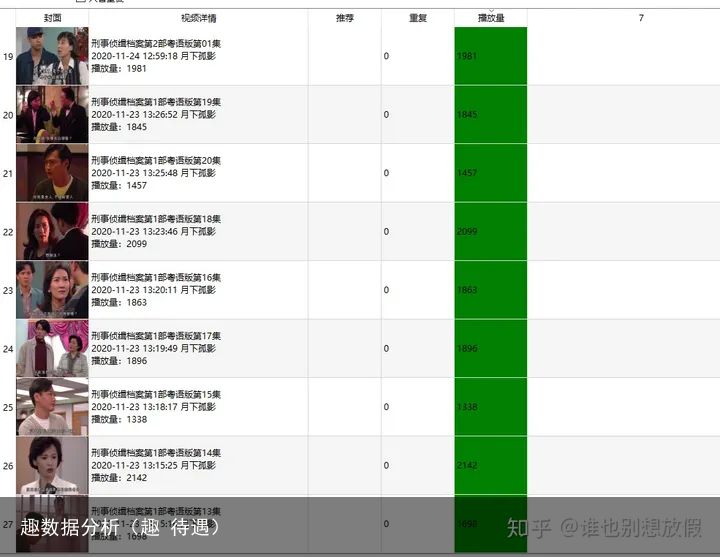
一是音乐mv的串烧mv,二是经典老片。流量都可以而且可以批量。再这些账号中,多找一些这种套路。
