







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
关于大数据与数据分析的浅谈(关于大数据与数据分析的浅谈论文摘要)
 2023-05-29
2023-05-29 浏览次数:次
浏览次数:次 返回列表
返回列表首先,数据分析的大虾们就不用整篇去看了,这里我只做一些简单的背景介绍,适合一些想在数据分析行业发展零基础的人。这里的内容来源于Dr. Anil Maheshwari的Data analytics Made Accessible,也是我最早接触的关于大数据背景的一本书。里面有详细的关于数据库,数据挖掘及分析的一些理论知识,但是没有详细的去逐一解说。因此,书并不深奥,非常适合初学者去了解大数据分析的一个概况。

首先,那么大数据是如何产生的?
在一般的商业活动中,人们经常需要规避风险。未来市场是不确定的。因此,公司的决策目标是降低风险并做出有效的经营决定。有效的决策是建立在众多的事实与商业感官上。可靠的信息知识可以帮助人们更好的做出决定,规避风险。
由于网络发展的速度超乎想象,借助手机等各种通信设备允许人们在任何地方任何时段都可以进行有效的决策。因此,收集及分析信息的速度也将影响企业的未来发展。
目前处理数据最多的简易分析工具,举例:Microsoft Excel,像Pivot table可以帮助我们做一些what if 的分析。
BI商务智能最早就是1996年提出的,主要是将企业中现有的数据进行有效的整合,列如大数据的ETL过程,Extract提取数据,Transfer转换数据,Load加载数据的平台。而这就是最初的大数据概念,简单来说就是通过各类应用软件将大量的数据存储及高效处理的过程。
数据的处理流程是什么?
处理数据,我们首先有大量的源数据。

如上图所示,Data Base与Data Warehouse的区别在与数据库是存储大量数据的地方,也就是未经处理的原始数据。当我们将大量数据清洗到可呈现分析状态时,数据仓库就是我们要存储这类数据的地方。
什么是数据挖掘?
书里有一句话:Data mining is the art and science of discovering knowledge, insights and patterns in data.
诚然,数据挖掘是科学,也是一门艺术。
在做挖掘之前,数据清洗(data cleansing)过程是非常重要的,数据的质量与之后的分析结果可以说是息息相关。所以在前期的清洗过程中需要严格把控数据的质量提高整个Statistical power,因此来规避一类与二类错误。
那么什么样的数据是需要清洗的?
缺失的数据拥有outlier的数据字段不统一的组合连续变量重复的数据
如上图所示,False Negative也就是统计中我们常说的Type one error,一类错误,当null的原始假设是正确的时候,我们却拒绝了它。False Positive也是Type two error,二类错误,当原始假设是错误的时候,我们却接受了交换假设,即无法拒绝null。这两类错误所造成的后果我们都是不愿意看到的,因此,如何降低这两类错误取决于我们数据的统计效应(Statistical Power)。
如何去增加统计效应在数据清洗中是我们必须要考虑的因素,在这里我就不做过多的展开了。不然的话再啰嗦个几千字都有可能。
有哪些常用的数据分析方法?
Decision Tree (决策树)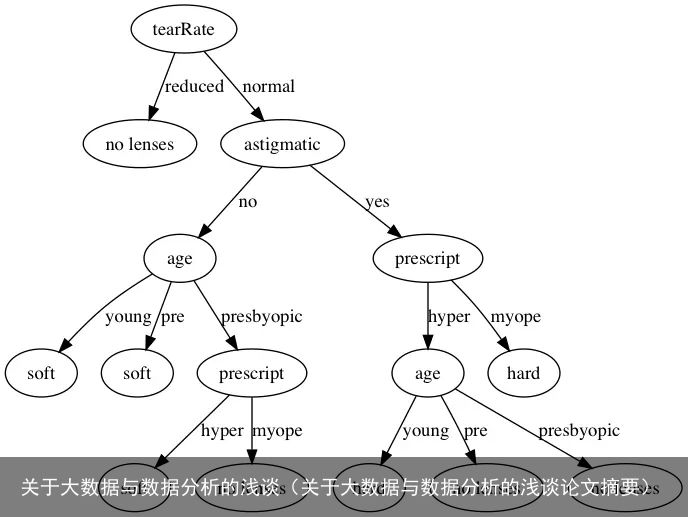
决策树的数学理论是选择最小的因变量,因此,从所有的因变量开始分析,选择最合适最有用的因变量至关重要。在数据量小的情况下,使用decision tree还是不错的选择。
其特点是在实际的操作过程中,整个逻辑会因为因变量的增多而显著的提高预测的准确度,但是也会使整个逻辑变得非常复杂,且结论通常是不对称的,也就是说有一段的结果导会因为实际情况而变得非常长。显然在大数据的情况下,花费大量的时间与人力去理解当中的过程是不值得的。
2. Regression (回归分析)也是目前最常见的
好处:
在统计学的基础理论上非常容易理解。线性回归方程能给出简单易于使用的数学方程回归方程能够测算因变量是否适合预测的结论更为强势因变量可以根据实际情况而变多,当因变量越多,精确度通常来说也会越高更具说服力坏处:
回归方程不能解决数据质量不高的问题,若是前期的数据质量不高,模型的精确度将会大大下降回归方程不能解决因变量之间的共性问题不能够自行选择多个共性的因变量,若其中一个因变量的数字大于其他的因变量,整个模型也会变得不可靠线性回归不能解决非线性的问题3. ANN (Artificial Neural Networks) (人工神经网络)
人工神经网络经常被使用在非常复杂的方程上,并能够处理大量的数据,其模型能够根据每次的分析结果和用户反馈进行自我学习,演化改进系统,最终达到最精确的结果。
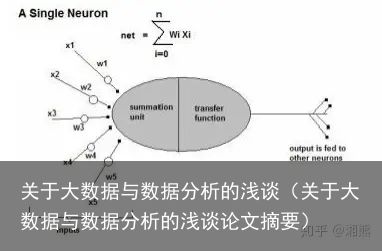
如上图所示,类似与人脑收集信息与处理信息的过程,权重w1,w2,w3,w4,w5分别为外部的接触信息,中间的为处理信息的模型架构,随后转移所得信息输出所得结果。
好处:
ANN可以不需要借助太多分析工作就可以解决非线性的关系,尤其是非常复杂的关系能够自行根据导入的案列进行分析,不需要太多编程方便的语言可以解决不同的问题类型,例如分类,聚类,联合要求对数据的质量问题不是那么的高可以解决数字式或者其他各种不同类型的因变量效率比其他任何分析方法都高通常可以得出最精确的分析结论坏处:
ANN时常被定义为“黑匣子式”的解决方案,缺乏解释的定义。(因为这里你可以理解为输入一个inputs的时候,会进入一个匣子,随后变成output出来,中间缺乏一个完整的分析过程)完美的ANN系统架构仍然是一门艺术,需要极高的技术水平和经验有时候难以处理较大数字的因变量需要非常的数据集合来处理4. Cluster Analysis (聚类分析)
聚类分析法也是常见的一种,简单来说,是自然的去分辨各种事物的组合,将类似的数据归类的一个集合的分析方法。
但是,聚类分析是不可监控的方法,也就是说没有任何的因变量去判断测试每一个类别的内容是否正确,一个数据库应该有多少个类别,以及每个类别的定义也是无法确定的。
5. Association rules (关联规则法)
关联规则分析是最常见是在商业领域,商家可以使用此方法去鉴别购物中心每个商品的角色。比如,沃尔玛的“啤酒与尿布”,啤酒为何会和尿布放在一起。理论上,这两种商品是毫无关联的,但是实际情况却是买尿布的多为男性,而男性在买尿布的同时30-40%的概率会同时选择自己心仪的啤酒。
以上就是五种我们常见的数据分析方法。总的来说,大数据就是将杂乱无章的大量复杂数据整合成可分析利用的数据工具。2000年时,全世界的数据总量已达到800,000 Petabytes。2020年时,将会达到可观的35 Zettabytes(对单位没概念的人请看下文)。
数据存储单位:
8 bit = 1 Byte (一字节)
1024 B = 1 KB (Kilobyte)千字节
1024 KB = 1 MB (Megabyte)兆字节
1024 MB = 1 GB (GigaByte)吉字节
1024 GB = 1 TB (Terabyte)太字节
1024 TB = 1 PB(Petabyte)拍字节
1024 PB = 1EB (Exabyte)艾字节
1024 EB = 1ZB (Zetabyte)皆字节
可想而知,大数据在今后的整个行业有多么重要,数据量大的时候,单纯的使用Excel已经无法承担了。当你的Excel仅仅达到20MB的时候,可能就需要10分钟乃至更久的时间去打开它,更别说进行运算复杂的分析过程了。
大数据的系统必须具有三个特点,从很多其他的渠道我看到会用5个V去形容大数据的特点。其实我个人觉得三个V就足够了:
VolumeVelocityVarietyValue和Veracity不必多说,当我们拥有大数据的时候,价值与真实性是妥妥的同时兼备的。这里就是我所概括的一些大数据概念的背景,其中每一个分析方法都是非常专业的,需要大量的时间与精力去深层学习。初期的大数据平台架构,更多的是IT方面的专业水平,中后期的数据清洗,挖掘与分析需要统计与数学的相关知识。因此,这不是一个人就可以做的事情。通常来说,将由一个团队来共同完成。
PS. 封面为自拍的西藏圣山南迦巴瓦峰,愿看到的人生活工作学习顺顺利利,吉祥如意。
(未经许可不得转载)
