![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
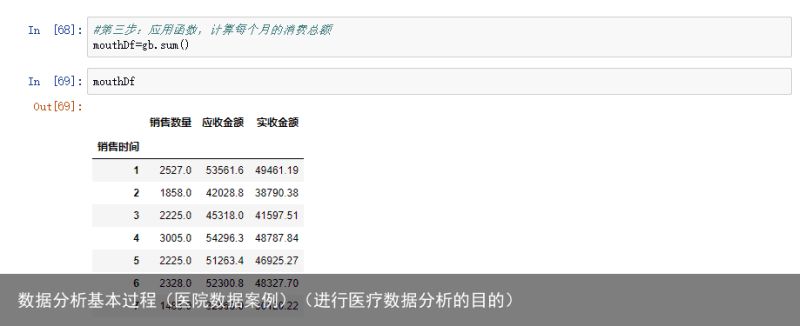
数据分析基本过程(医院数据案例)(进行医疗数据分析的目的)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表数据分析案例
数据分析的基本步骤包括:
提出问题理解数据数据清洗构建模型数据可视化这次以某医院数据为案例来分析整个数据过程。
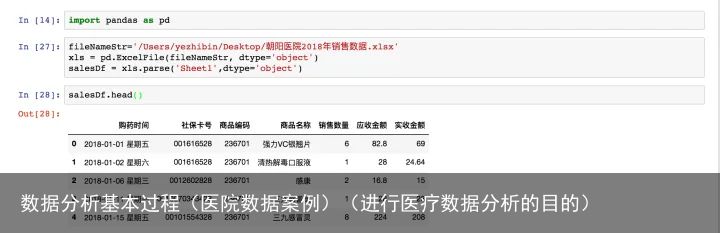
1、提出问题
要从销售数据中分析以下业务指标:
1)月均消费次数;
2)月均消费金额;
3)客单价;
4)消费趋势
遇到的问题:在执行这段代码的时候,出现一个问题,那就是一直提示我:
ImportError: No module named xlrd这时候我通过搜索,分别执行了以下几个命令
pip install xlrd pip3 install xlrd conda install xlrd但是依然报错,在终端也已经提示
Requirement already satisfied: xlrd in /anaconda3/lib/python3.6/site-packages但是我的MAC上一直报错。最后通过谷歌找到了解决方案,链接为:
Python: "ImportError: no module named xlrd" after installing xlrd using pipstackoverflow.com/questions/44181328/python-importerror-no-module-named-xlrd-after-installing-xlrd-using-pip
我执行了这里面的这段代码
import pip package_name=xlrd pip.main([install, package_name])2、数据清洗
选择子集列名重命名缺失数据处理数据类型处理数据类型转换数据排序异常值处理1)选择子集(只选取需要进行分析的数据,本例中不需要)
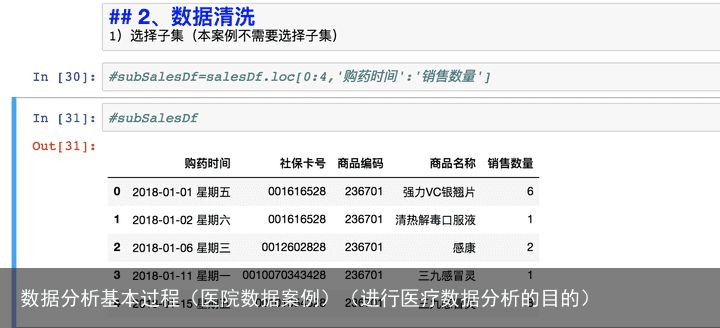
2)列名重命名
先定义一个字典表明旧列名和新列名的对应关系
inplace=False,数据框本身不会变,而会创建一个改动后新的数据框,默认的inplace是False,inplace=True,数据框本身会改动3)缺失值处理
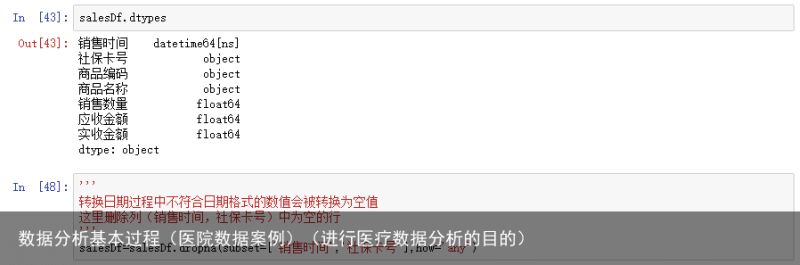
缺失值的处理可以用dropna参数的subset做处理,移除指定列为空的数据,其how=any即在给定的任何一列有缺失值就删除。具体的用法可以参见:
pandas.DataFrame.dropna - pandas 0.22.0 documentationpandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.dropna.html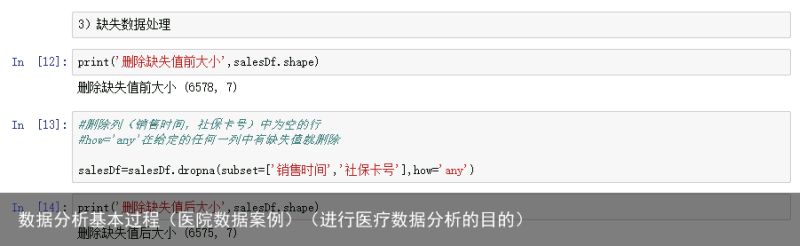
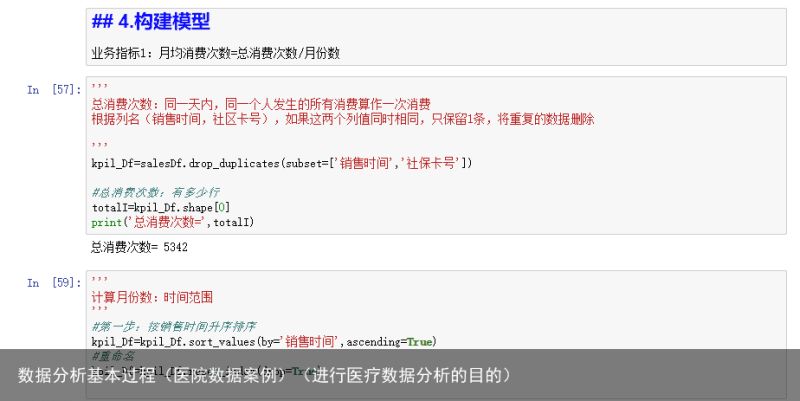
在删除前,数据是6578条,删除后,数据是6575条,说明3条数据有缺失销售时间或者社保卡号。
4)数据类型转换
字符串转换为数值(浮点型)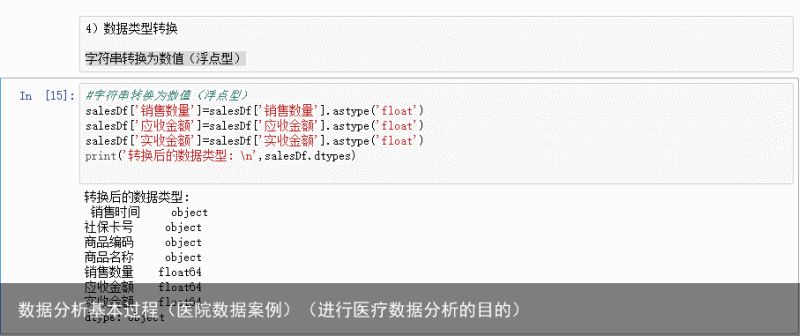 字符串转换为日期数据类型
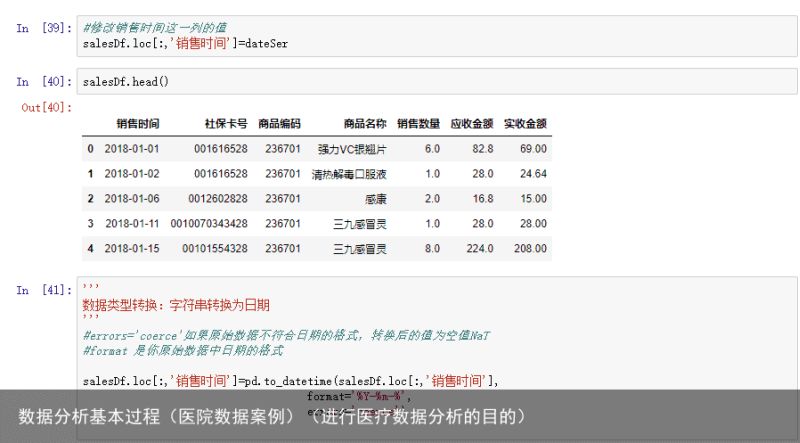
字符串转换为日期数据类型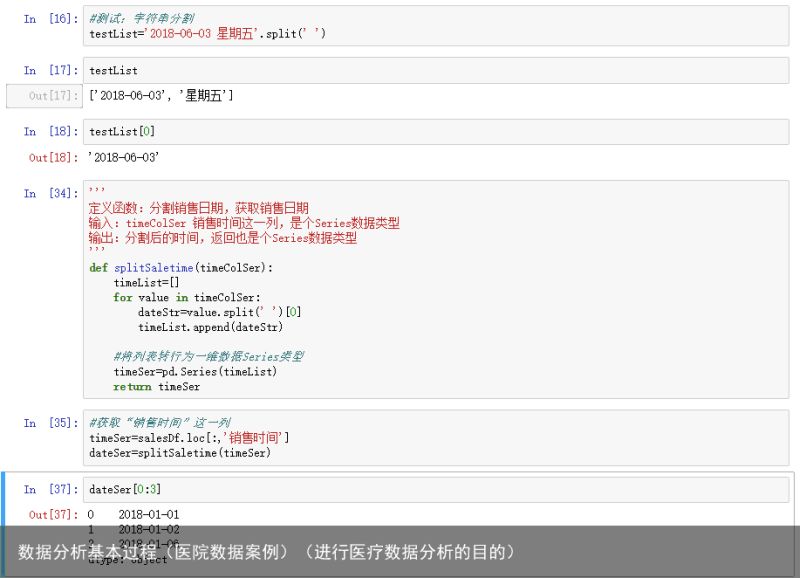
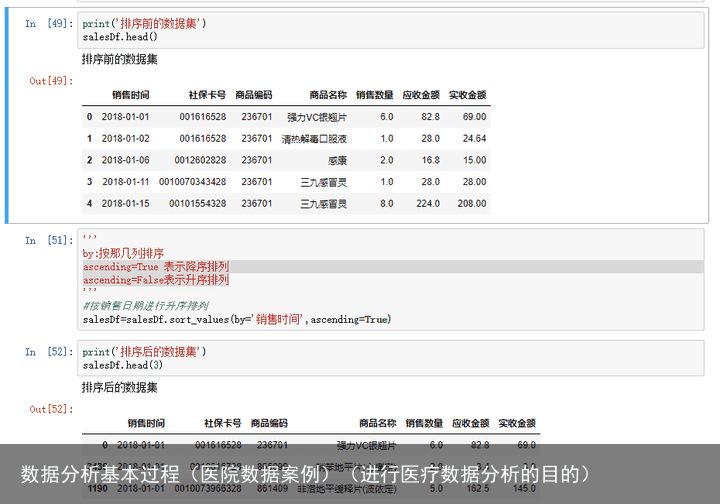
5) 数据排序
ascending=True 表示降序排列;ascending=False表示升序排列。
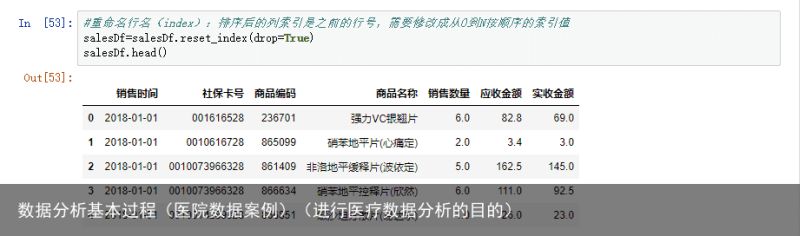
排序后需要重命名行名,使用reset_index,可以将行号修改成从0到n顺序排列的索引值,其中drop = True选项会丢弃原来的索引而设置新的从0开始的索引。
6)异常值处理
通过describe方法获取所有这些列的描述统计信息,排除那些金额数量为0的负数,经过筛选将那些异常值删除。

4、构建模型
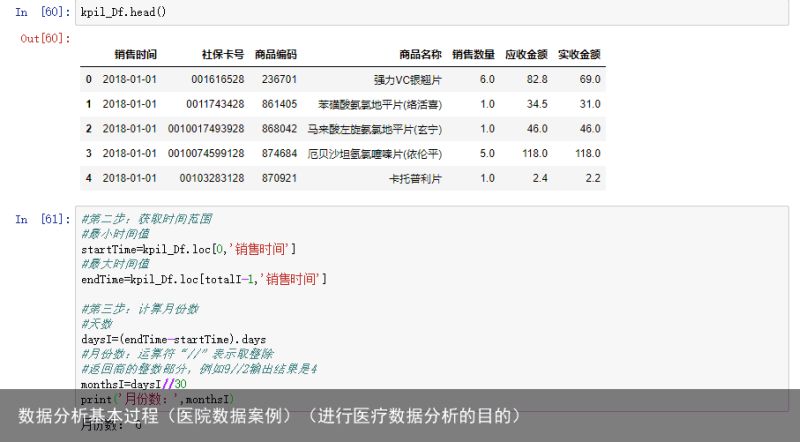
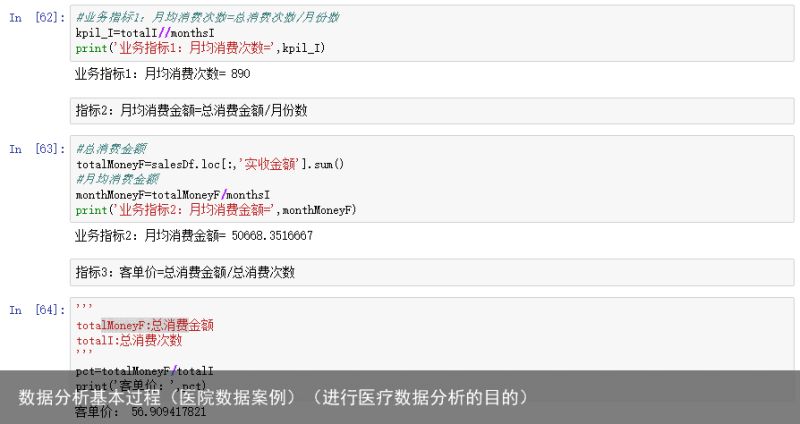
业务指标1:月均消费次数=总消费次数/月份数
指标2:月均消费金额=总消费金额/月份数
指标3:客单价=总消费金额/总消费次数
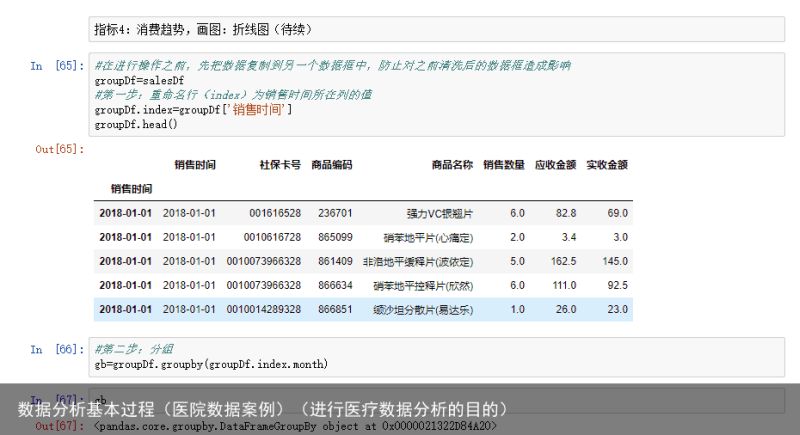
指标4:消费趋势,画图:折线图(待续)