







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据分析—KNN分类算法(数据分析—用户行为分析)
 2023-08-22
2023-08-22 浏览次数:次
浏览次数:次 返回列表
返回列表笔记内容来源:拉勾教育数据分析实战训练营
我是一名工作四年的数据分析小白,虽然工作四年,但在数据分析的职业中依然无法突破自己。在面试中,往往因为技术不够、业务能力不强而无法能够进入自己心仪的公司。在一次偶然的机会,我看到了拉勾教育数据分析这门课程,通过和不同机构的课程设置对比,最终下定决心通过拉勾系统地学习一遍数据分析内容。
简单地介绍一下拉勾数据分析课程:
拉勾数据分析课程共分成10个阶段:从数据分析思维与业务流程—>MySQL—>BI可视化—>Hive—>Python—>统计学—>数据分析项目实战—>数据挖掘算法—>一线互联网数据分析综合实战—>面试就业指导。各个阶段层层递进,课程紧凑,逻辑性强,技术+业务结合,有很多项目实战案例,能够让初中级数据分析时有很好地提升。课程师资配置:讲师+导师+班主任。讲师讲授课程内容,都是比较专业的数据分析大佬,能够将复杂的知识清晰简单地传输给我们。导师负责答疑、批改作业,班主任负责监督学习、制定学习计划。课程形式:录播+直播。主体课程主要是录播视频,方便大家在业务时间和节假日学习,每个阶段都会有几次直播课程,主要讲解一些新的项目案例、讲解作业、解答疑问。课程项目案例丰富,有教育行业、电商行业、新媒体行业、房产行业等的数据案例讲解。以下是我学习KNN算法的学习笔记。
KNN/K近邻算法原理
KNN/K近邻算法属于分类算法,是一种有监督学习算法。
算法原理
KNN的本质是通过距离判断待测样本和已知样本是否相似。待测样本找到与已知样本中与其距离最近的K个样本,对这k个样本,它们大多数属于哪一类别,就把待测样本归为哪一类别。
实现过程
假设X_test为待标记的数据样本,X_train为已标记的数据集。
(1)计算X_test与所有X_train的距离,并把距离保存在Distinct数组中。
(2)对Distinct数组进行排序,取距离最近的k个点,记为X_knn。
(3)在X_knn中统计每个类别的个数,即class0在X_knn中有几个样本,class1在X_knn中有几个样本等。
(4)X_knn中样本个数最多的那个类别就是X_test的类别。
下图中, XuX_u 为待标记样本, XuX_u 计算与每个类别样本的距离,选取最近的5个点(k=5),则 XuX_u 属于 ω1\omega_1 。
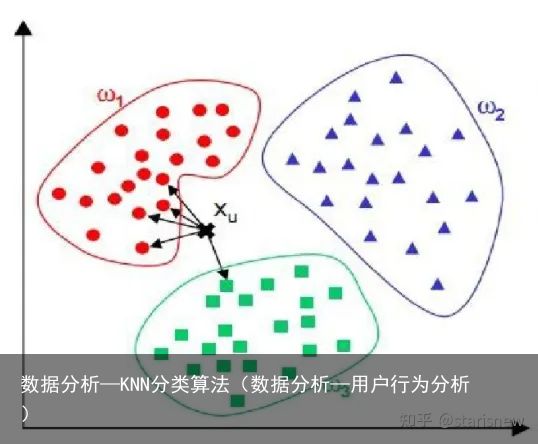
距离的确定
常用的距离有很多,可以使用欧式距离。

若样本数据有n个特征,则两点A和B的坐标可表示为:
A(x1A,x2A,x3A,...,xnA),B(x1B,x2B,x3B,...,xnB)A(x_{1A},x_{2A},x_{3A},...,x_{nA}),B(x_{1B},x_{2B},x_{3B},...,x_{nB})
则A和B两点之间的欧式距离公式如下:
d(A,B)=(x1A−x1B)2+(x2A−x2B)2+...+(xnA−xnB)2=∑i=1n(xiA−xiB)2d(A,B)=\sqrt{(x_{1A}-x_{1B})^2+(x_{2A}-x_{2B})^2+...+(x_{nA}-x_{nB})^2}=\sqrt{\sum^n_{i=1}(x_{iA}-x_{iB})^2}
算法的优缺点
算法参数是k,参数选择需要根据数据来决定。
K值越大,模型的偏差越大,对噪声数据越不敏感。K值很大时,可能造成模型欠拟合。K值越小,模型的方差就会越大。K值太小,容易过拟合。用Python实现KNN算法
在Python中使用scikit-learn包可以调用KNN算法。scikit-learn,简称sklearn,支持包括分类、回归、降维和聚类四大机器学习算法,以及特征提取、数据预处理和模型评估三大模块。
导入数据
通过威斯康辛乳腺癌数据集来理解KNN算法。
此数据集是sklearn.datasets中的内置数据集,包含了威斯康辛州569个病人的乳腺癌恶性/良性(1/0)类别型数据和与之对应的30个维度的生理指标数据。
代码:
#导入乳腺癌数据 from sklearn.datasets import load_breast_cancer import pandas as pd import numpy as np data = load_breast_cancer() x = data.data y = data.target name = [平均半径,平均纹理,平均周长,平均面积,平均光滑度, 平均紧凑度,平均凹度,平均凹点,平均对称,平均分形维数, 半径误差,纹理误差,周长误差,面积误差,平滑度误差, 紧凑度误差,凹度误差,凹点误差,对称误差,分形维数误差, 最差半径,最差纹理,最差的边界,最差的区域,最差的平滑度, 最差的紧凑性,最差的凹陷,最差的凹点,最差的对称性,最差的分形维数, 患病否] breast_cancer = pd.DataFrame(np.concatenate((x,y.reshape(-1,1)),axis=1),columns=name) breast_cancer.head()输出:
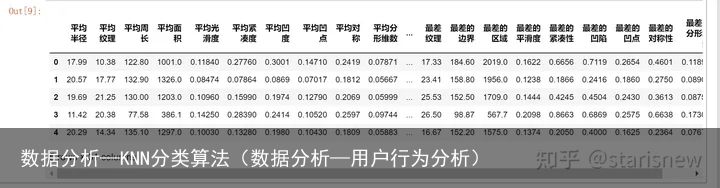
划分训练集和测试集
在实际业务中,我们往往是由已知的历史数据建模,但测试数据确是新的未知数据,我们希望模型在未知数据集上的效果也表现优秀。把陌生数据集上表现优秀的能力称为泛化能力。为了提高模型的泛化能力,在进行学习算法前,通常会将一个样本集分成训练集和测试集,其中训练集用于模型的学习或训练,测试集用于评估训练好的模型。一般训练集样本量占原数据的70%,测试集占30%。
通过sklearn.model_selection里的train_test_split()函数来随机划分样本数据为训练集和测试集。
模板:
from sklearn.model_selection import train_test_split train_X,test_X,train_y,test_y = train_test_split(train_data,train_target,test_size=0.3,random_state=5)参数解释:
train_data:待划分样本数据train_target:待划分样本数据的结果(标签)test_size:测试数据占样本数据的比例random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样代码:
#划分训练集和测试集 from sklearn.model_selection import train_test_split xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3,random_state=420)归一化
在机器学习中,特征数值会存在量纲不统一。在KNN中,如果某个特征的取值非常大,那么在计算距离就主要取决于这个特征,其他取值小的特征无法对距离大小产生影响,从而与实际情况相悖。
数据集中存在各特征量纲不同的情况时,在使用KNN分类器前需要对数据集进行归一化处理。
数据归一化:
x∗=x−min(x)max(x)−min(x)x^* = \frac{x-min(x)}{max(x)-min(x)}
注意在处理数据时,先划分训练集和测试集,再归一化。
导入包:
from sklearn.preprocessing import MinMaxScaler as mms代码:
#归一化 from sklearn.preprocessing import MinMaxScaler as mms mms_01 = mms().fit(xtrain) #求训练集最大/最小值 mms_02 = mms().fit(xtest) #求测试集最大/最小值 #转化 x_train = mms_01.transform(xtrain) x_test = mms_02.transform(xtest)建立模型
使用KNeighborsClassifier:
KNeighborsClassifier(n_neighbors=5, weights=uniform, algorithm=auto, leaf_size=30, p=2, metric=minkowski, metric_params=None, n_jobs=None, **kwargs)参数说明:
n_neighbors: 即K,近邻数,默认值为5。weight:预测的权函数,概率值。uniform:同一的权重,即每个邻域中的所有点都是平均加权的。distance:这种情况下,距离越近权重越大,反之,距离越远其权重越小。[callable]:用户定义的函数,它接受一个距离数组,并返回一个包含权重的相同形状的数组。algorithm:用于计算最近邻居的算法。有 {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}。默认为auto,自动选择合适的算法。leaf_size: 传递给‘ball_tree’或‘kd_tree’的叶子大小。metric: 用于树的距离度量。默认minkowski与P = 2(即欧氏度量)p:p=1表示使用曼哈顿距离,p=2使用欧氏距离。metric_params:度量函数的附加关键字参数,设置应为字典形式,默认None。n_jobs: 并行工作的数量,如果设为-1,则作业的数量被设置为CPU内核的数量。代码:
#导入包 from sklearn.neighbors import KNeighborsClassifier #建立模型 clf = KNeighborsClassifier(n_neighbors=6) #训练模型 clf = clf.fit(x_train,ytrain)模型预测
使用建好的模型进行预测,用predict方法。
代码:
#预测x_test clf.predict(x_test)输出:
array([1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1])模型评估
使用score可以返回测试数据与标签的平均准确度,即预测准确个数/总数。
代码:
#计算准确率 score = clf.score(x_test,ytest) score输出:
0.9707602339181286模型准确率较高。
选择最优K值
KNN中的K是一个超参数,所谓超参数,就是需要人为输入,算法不能通过直接计算得出的参数。那么,K值选择多少才能使得模型达到最优?
学习曲线
通过不同的k值来评估模型的准确率,绘制参数学习曲线,直观地展示不同k值下的score值是多少,进而选择模型表现最佳点的参数取值作为整个参数的取值。
代码:
#绘制学习曲线 from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt score = [] krange = range(1,20) for i in krange: clf = KNeighborsClassifier(n_neighbors=i) clf = clf.fit(x_train,ytrain) score.append(clf.score(x_test,ytest)) plt.plot(krange,score) plt.xlabel(k) plt.ylabel(score) plt.xticks(krange) plt.show()输出:

将k=8带入重新执行模型,代码如下:
clf = KNeighborsClassifier(n_neighbors=8) clf = clf.fit(x_train,ytrain) clf.score(x_test,ytest)输出:
0.9766081871345029模型预测准确率更高。
交叉验证
但有时,如果随机划分的数据集变化的话,得分最高的k值也会发生变化。
只有在众多不同的训练集和测试集上都表现优秀,模型才是一个稳定的模型。为此,提出了交叉验证。
最常用的交叉验证是k折交叉验证。将数据集分成n份,依次使用其中的一份作为测试集,其他的n-1份作为训练集,计算每次模型的精确度并求平均值。训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的均值,是对模型效果的一个更好的度量。
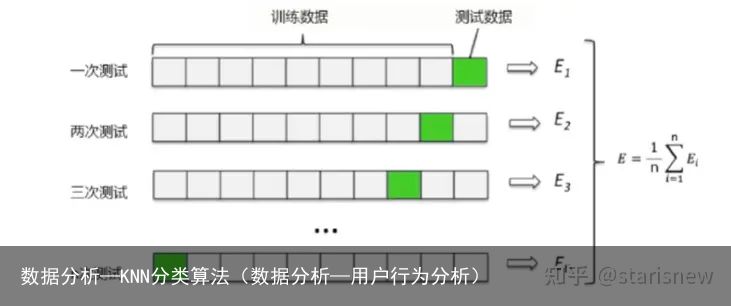
交叉验证的包使用sklearn.model_selection的cross_val_score:
sklearn.model_selection.cross_val_score(estimator, X, y, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’)参数说明:
estimator: 需要使用交叉验证的算法X:输入样本数据y:样本标签groups:将数据集分割为训练/测试集时使用的样本的组标签(一般用不到)scoring: 交叉验证最重要的就是他的验证方式,选择不同的评价方法,会产生不同的评价结果。带交叉验证的学习曲线:
#导入交叉验证包 from sklearn.model_selection import cross_val_score as cvs clf = KNeighborsClassifier(n_neighbors=8) cvresult = cvs(clf,x_train,ytrain,cv=5) #训练集对折5次,一共5个预测率输出 cvresult #每次交叉验证运行时估算器得分的数组输出:
array([0.9375 , 0.9875 , 0.975 , 0.94936709, 0.97468354])查看均值和方差:
#均值:查看模型的平均效果 t1 = cvresult.mean() #方差:查看模型是否稳定 t2 = cvresult.var() print(t1,t2)输出:
0.9648101265822785 0.0003400957378625225设置不同的k值:
#交叉验证 score = [] var = [] k = range(1,20) #设置不同的k for i in k: clf = KNeighborsClassifier(n_neighbors=i) cvresult = cvs(clf,x_train,ytrain,cv=5) score.append(cvresult.mean()) var.append(cvresult.var()) plt.plot(k,score) plt.xticks(k) plt.plot(k,np.array(score)+np.array(var),c=red,linestyle=--) plt.plot(k,np.array(score)-np.array(var),c=red,linestyle=--)输出:
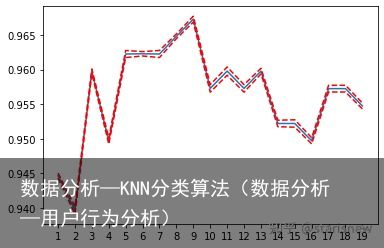
当n_neighbors取9时,精确度最高。
clf = KNeighborsClassifier(n_neighbors=9) clf = clf.fit(x_train,ytrain) clf.score(x_test,ytest)输出:
0.9766081871345029在做交叉验证时,折数不能过大或过小,折数过大会使运算效率变慢、预测率方差较大。
网格搜索
可以通过网格搜索寻找超参数最优值。
Grid Search:网格搜索,是一种调参手段,在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。
代码:
from sklearn.model_selection import GridSearchCV param_grid = [ { weights:[uniform], n_neighbors:[i for i in range(1,20)] }, { weights:[distance], n_neighbors:[i for i in range(1,20)], p:[i for i in range(1,6)] } ] clf = KNeighborsClassifier() grid_search = GridSearchCV(clf,param_grid,cv=5) grid_search.fit(x_train,ytrain)输出:
GridSearchCV(cv=5, error_score=raise-deprecating, estimator=KNeighborsClassifier(algorithm=auto, leaf_size=30, metric=minkowski, metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights=uniform), iid=warn, n_jobs=None, param_grid=[{n_neighbors: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19], weights: [uniform]}, {n_neighbors: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19], p: [1, 2, 3, 4, 5], weights: [distance]}], pre_dispatch=2*n_jobs, refit=True, return_train_score=False, scoring=None, verbose=0)调用 .best_estimator_ ,可以返回最佳的分类器
grid_search.best_estimator_输出:
KNeighborsClassifier(algorithm=auto, leaf_size=30, metric=minkowski, metric_params=None, n_jobs=None, n_neighbors=5, p=2, weights=uniform)调用 .best_score_ , 可以返回最佳分类器对应的准确度
grid_search.best_score_输出:
0.9723618090452262调用 .best_params_ ,可以返回最佳分类器对应的参数
grid_search.best_params_输出:
{n_neighbors: 5, weights: uniform}用网格搜索得出的参数进行建模:
clf = KNeighborsClassifier(n_neighbors=5,weights=uniform) clf = clf.fit(x_train,ytrain) clf.score(x_test,ytest)输出:
0.9766081871345029