







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
五步利用Excel进行数据分析
 2023-03-11
2023-03-11 浏览次数:次
浏览次数:次 返回列表
返回列表话说数据分析听起来挺高大上的,这回我们看看如何用Excel来进行一次数据分析之旅~
数据分析简单讲分为下面五步:
1. 提出问题(你想通过数据得出什么结论?清晰准确的问题是做好任务的前提)
2. 理解数据(首先要将数据拿到手里,行话叫做数据抓取,也叫爬虫,然后进行基本的数据描述)
3. 数据清洗(就像我们去海边钓到的各种海鲜一样,在吃之前总要清晰干净吧,数据清洗就是讲数据整理一下,格式统一,缺失的补上,重复的删掉,类似这样的操作。)
4. 构建模型(其实就是分析的过程啦~)
5. 数据可视化(一堆密密麻麻的数据看着头疼?没错,老板可没有耐心看原始数据,各种图表这时候就派上用场了,这时候颜值就很重要了。)
(以数据分析师招聘的数据为例)
一、提出问题
要解决的问题:
1、在哪些城市找到数据分师工作的机会比较大?
2、数据分师的薪水如何?
3、根据工作经验的不同,薪酬是怎样变化的?
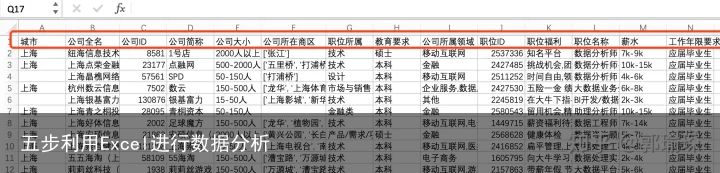
二、理解数据
对数据有一个基本的认识,了解各个字段。
三、数据清洗
选择子集(提取需要用到的列进行分析,注意通过隐藏字段功能)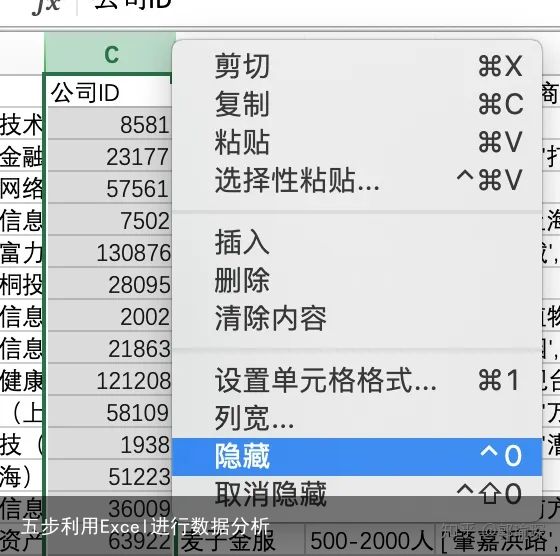
选中列,右键进行隐藏。
2. 列名重命名
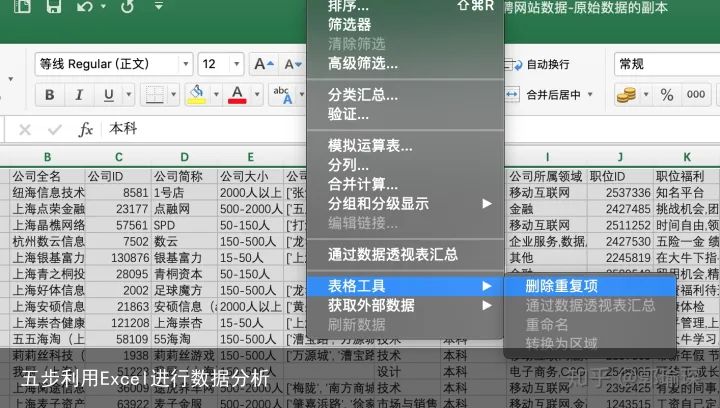
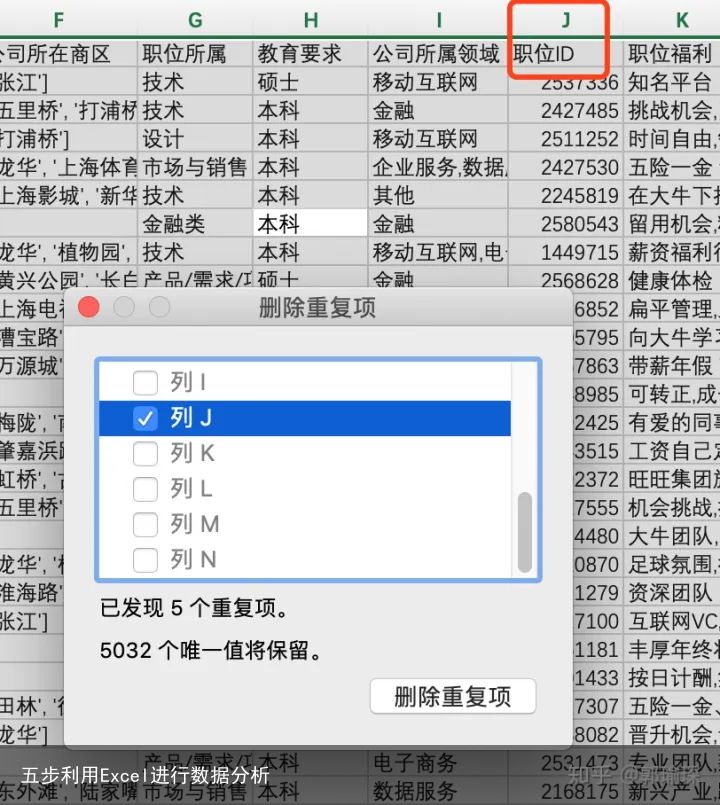
3. 删除重复值
4. 缺失值处理
因为数据量较大,在数据采集过程中,有些数值没有采集到。通常我们可以采用一下三种方法:
删除:删除数据缺失的记录;
均值:使用当前列的均值;
高频:使用当前列出现频率最高的数据。
5. 一致化处理
首先,可以看到公司所属领域有多个描述,用逗号隔开,下面通过分列功能进行拆分
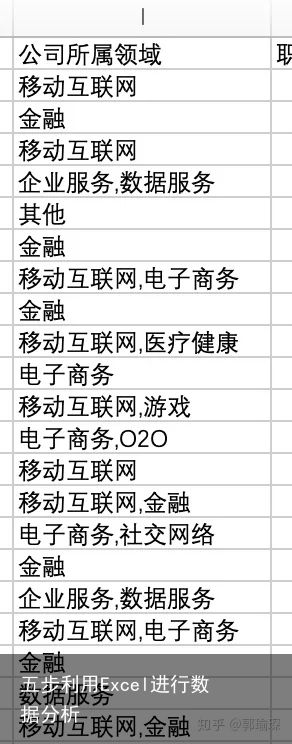
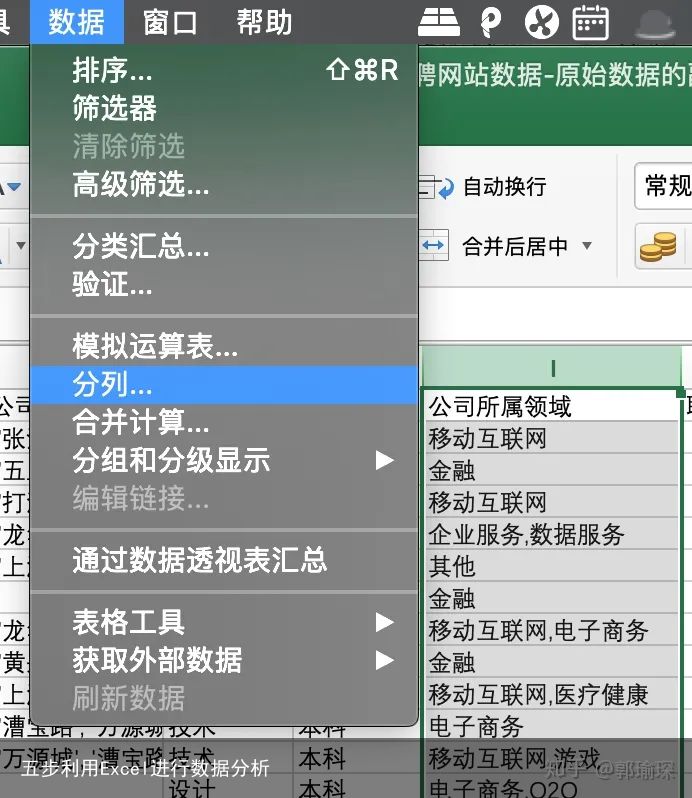

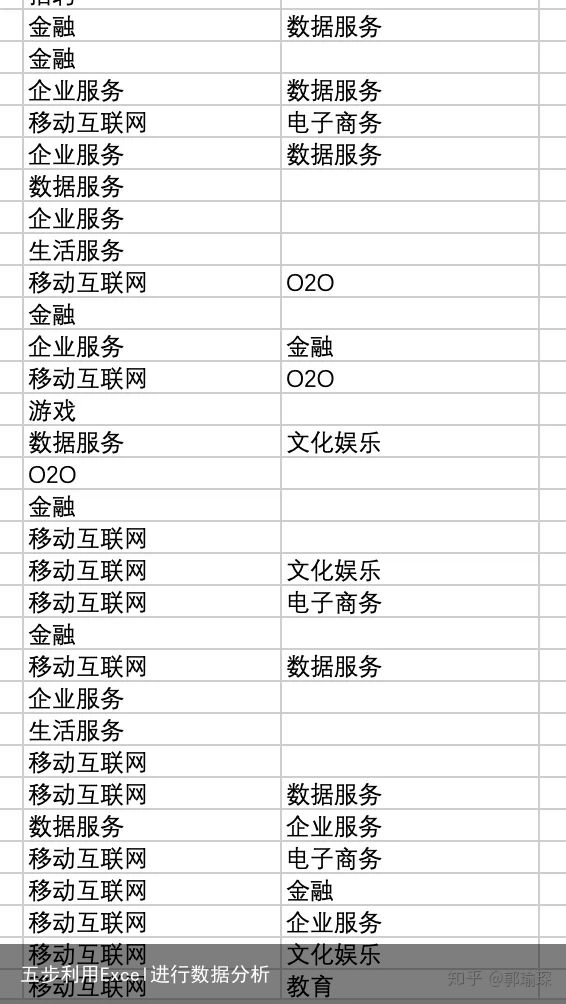
下面是分列后的效果:
接下来处理薪水,当前显示的是类似7k-9k这样的格式,为了后面可以进行数学计算,需要将这个字段的字符串转换成数字,拆成最低薪水和最高薪水两列。这里用到下面的这几个函数:
FIND函数:函数 FIND 用于在第二个文本串中定位第一个文本串,并返回第一个文本串的起始位置的值,该值从第二个文本串的第一个字符算起。
语法:FIND(find_text, within_text, [start_num])
find_text 必需。 要查找的文本。within_text 必需。 包含要查找文本的文本。start_num 可选。 指定开始进行查找的字符。 within_text 中的首字符是编号为 1 的字符。 如果省略 start_num,则假定其值为 1。示例:
FIND("M",A2) 单元格 A2 中第一个“M”的位置
FIND("M",A2,3) 从单元格 A2 的第三个字符开始查找第一个“M”的位置
LEFT函数:从文本字符串的第一个字符开始返回指定个数的字符。
语法:LEFT(text, [num_chars])
Text 必需。 包含要提取的字符的文本字符串。num_chars 可选。 指定要由 LEFT 提取的字符的数量。
Num_chars 必须大于或等于零。如果 num_chars 大于文本长度,则 LEFT 返回全部文本。如果省略 num_chars,则假定其值为 1。LEFT(A2,4) 第一个字符串中的前四个字符
LEFT(A3) 第二个字符串中的第一个字符
RIGHT函数:根据所指定的字符数返回文本字符串中最后一个或多个字符。
语法:RIGHT(text,[num_chars])
文本 必需。 包含要提取字符的文本字符串。num_chars 可选。 指定希望 RIGHT 提取的字符数。RIGHT(A2,5) 第一个字符串的最后 5 个字符
RIGHT(A3) 第二个字符串的最后一个字符
MID函数:返回文本字符串中从指定位置开始的特定数目的字符,该数目由用户指定。
语法:MID(text, start_num, num_chars)
文本 必需。 包含要提取字符的文本字符串。start_num 必需。 文本中要提取的第一个字符的位置。 文本中第一个字符的 start_num 为 1,以此类推。num_chars 必需。 指定希望 MID 从文本中返回字符的个数。MID(A2,1,5) 从 A2 内字符串中第 1 个字符开始,返回 5 个字符。
 FIND("k",N2) 找到 “k” 在N2中出现的位置:2,减去1,再使用LEFT函数,最终得到7
FIND("k",N2) 找到 “k” 在N2中出现的位置:2,减去1,再使用LEFT函数,最终得到7 FIND("-",N2)+1 为开始位置,LEN(N2)-FIND("-",N2)-1 得到截取长度
FIND("-",N2)+1 为开始位置,LEN(N2)-FIND("-",N2)-1 得到截取长度下面将最低和最高薪水列的数据格式转为数字:
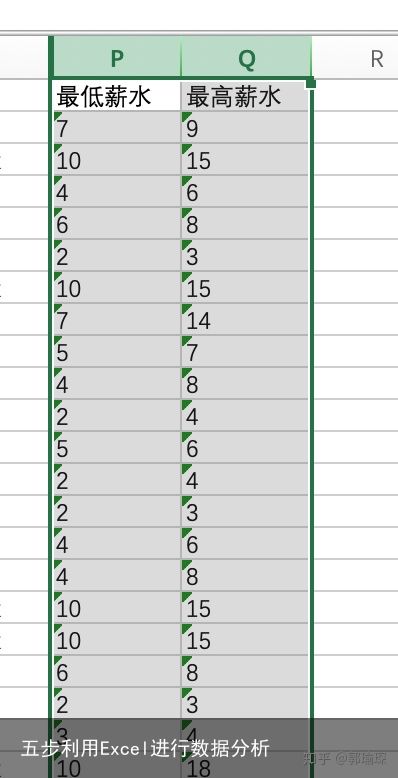
原来的位置进行复制,右键:选择性粘贴(只有值),然后进行分列:

6. 数据排序
首先添加平均薪水列:
我们可以对平均薪水进行降序排序:
7. 异常值处理
通过构建新的一列:是否为数据分析师从而使用IF函数来过滤掉非数据分析职位:
四、构建模型
数据透视表是计算、汇总和分析数据的强大工具,可助你了解数据中的对比情况、模式和趋势。
创建数据透视表
如果你在使用数据透视表方面没有什么经验或不确定如何开始,“推荐的数据透视表”会是一个不错的选择。使用此功能时,Excel 将通过在数据透视表中使数据与最合适的区域相匹配来确定有意义的布局。这可以为你进行其他实验提供一个起点。在创建建议的数据透视表后,你可以尝试不同的方向,并重新排列字段以达到特定结果。
你也可以下载交互式制作第一个数据透视表教程。
如何创建数据透视表数据分析师工作机会较大的城市:结论:按照岗位需求:北京>上海>深圳>广州>杭州
2、数据分师的薪水状况?
结论:深圳的平均薪资最高,为15k。
3、根据工作经验的不同,薪酬是怎样变化的?
补充 VLOOKUP 函数:
如果需要在表格或区域中按行查找内容,可使用 VLOOKUP,它是一个查找和引用函数。 例如,按部件号查找汽车部件的价格。
在这一最简单的形式中,VLOOKUP 函数表示:
=VLOOKUP(要查找的值、要在其中查找值的区域、区域中包含返回值的列号、精确匹配或近似匹配 – 指定为 0/FALSE 或 1/TRUE)。
VLOOKUP 语法:
要查找的值,也被称为查阅值。
查阅值所在的区域。 请记住,查阅值应该始终位于所在区域的第一列,这样 VLOOKUP 才能正常工作。 例如,如果查阅值位于单元格 C2 内,那么您的区域应该以 C 开头。
区域中包含返回值的列号。 例如,如果指定 B2:D11 作为区域,那么应该将 B 算作第一列,C 作为第二列,以此类推。
(可选)如果需要返回值的近似匹配,可以指定 TRUE;如果需要返回值的精确匹配,则指定 FALSE。 如果没有指定任何内容,默认值将始终为 TRUE 或近似匹配。现在将上述所有内容集中在一起,如下所示:
=VLOOKUP(查阅值、包含查阅值的区域、区域中包含返回值的列号以及(可选)为近似匹配指定 TRUE 或者为精确匹配指定 FALSE)。
示例
下面是 VLOOKUP 的一些示例:
