







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
电商平台零售数据分析
 2023-03-02
2023-03-02 浏览次数:次
浏览次数:次 返回列表
返回列表目录:
项目背景分析目标分析过程小结一、项目背景
CDNow曾经是一家在线音乐零售平台,后被德国波泰尔斯曼娱乐集团公司出资收购,其资产总价值在最辉煌时曾超过10亿美元。
二、分析目的
本文主要通过CDNow网站的用户消费记录,分析用户消费行为,建立RFM模型,分析复购率、回购率等关键指标,帮助运营人员更好了解当前用户现状,使运营部门在营销时更加具有针对性,从而节省成本,提升效率。整理分析框架如下:
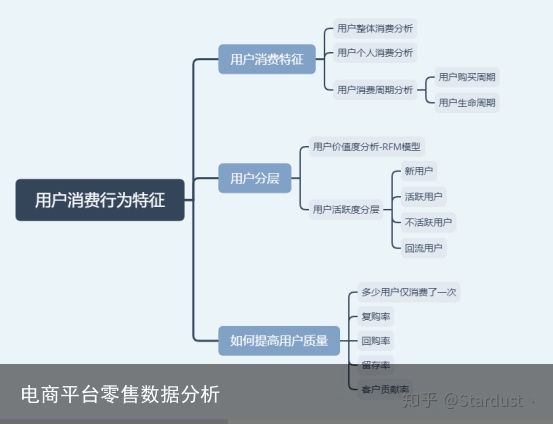 用户消费行为特征分析
用户消费行为特征分析三、分析过程
1、准备工作:数据集观察理解、数据清洗;
2、用户整体消费趋势分析(按月):每月的消费金额、消费次数、产品购买量、消费人数、用平均消费金额、用户平均消费次数;
3、用户个体消费分析(按用户):每个用户的消费金额、产品购买量情况,消费金额和产品购买量之间的关系,用户累计消费金额占比;
4、用户消费行为分析:用户首购时间分布,最后一次消费时间分布,新老用户占比,用户分层RFM模型、各类用户(新用户、活跃用户、不活跃用户、回流用户)的数量和占比,用户购买周期,用户生命周期;
5、用户复购率和回购率分析。
四、小结
1. 准备工作:数据集观察理解、数据清洗
1.1导入常用的包
import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline plt.style.use("ggplot") import warnings warnings.filterwarnings("ignore") plt.rcParams["font.sans-serif"]=["Microsoft YaHei"] plt.rcParams["axes.unicode_minus"]=False from datetime import datetime1.2导入数据集
columns=["user_id","order_dt","order_products","order_amount"] data=pd.read_table("./CDNOW.txt",names=columns,sep="\s+") data.head()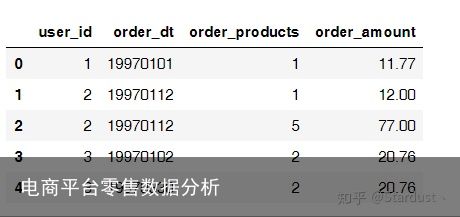
1.3数据预览:查看数据字段、数据类型、是否有缺失值、异常值等等
order_dt的数据类型应转换为日期型数据集字段理解:
user_id:用户IDorder_dt:购买日期order_product:订单数量order_amount:订单金额数据类型的更正:
data["order_dt"]=pd.to_datetime(data.order_dt,format="%Y%m%d") data["month"]=data.order_dt.values.astype("datetime64[M]") data.info()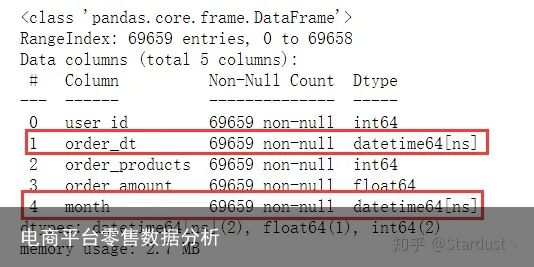
1.4数据的描述性统计:大部分订单只消费了少量商品(平均值为2.4),有一定的极值干扰,用户的消费金额比较稳定,平均消费35元,中位数25元,有一定极值的干扰。
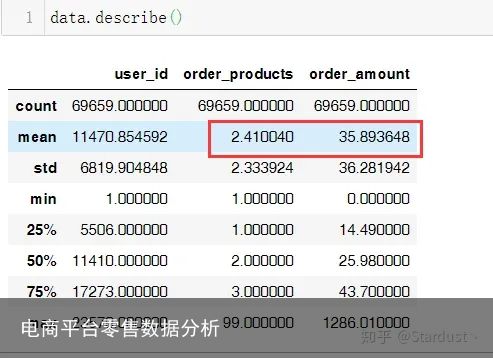 数据概览
数据概览2. 用户整体消费趋势分析(按月)
2.1每月消费总金额:由下图可知,消费金额在前三个月达到最高峰,后续消费较为稳定,有轻微下降趋势。
group_month=data.groupby("month") group_month_amount=group_month.order_amount.sum() group_month_amount.head()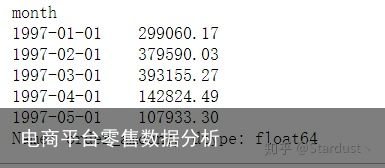 每月的消费总金额
每月的消费总金额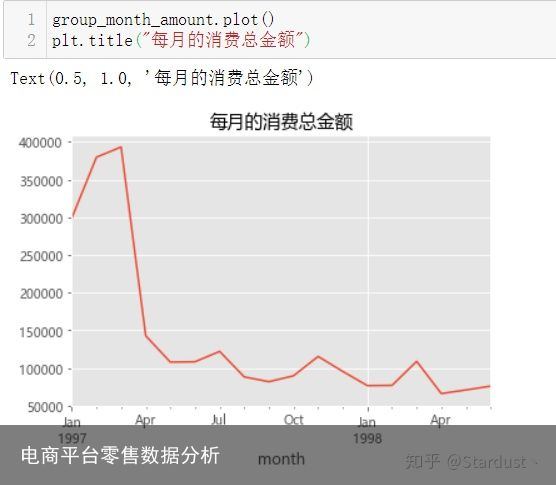
2.2每月的消费次数:由下图可知,前三个月消费订单数在10000笔左右,后续月份的消费订单数则在2500笔左右
group_month_order=group_month.order_dt.count() print(group_month_order.head()) group_month_order.plot() plt.title("每月的消费订单数")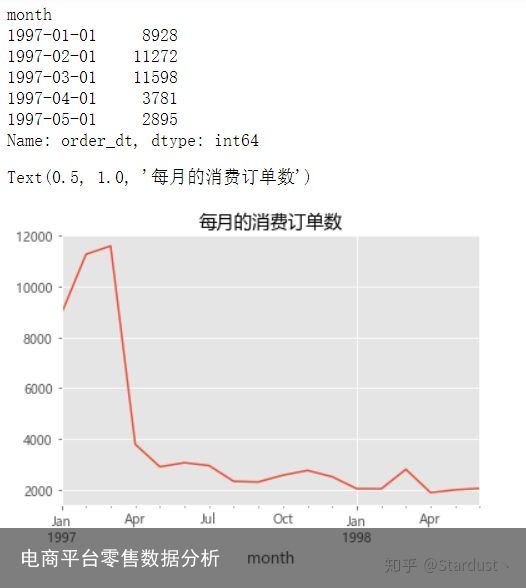
2.3每月的产品购买量:每月的产品购买量和订单数的趋势类似,早期购买量多,后期平稳下降,为什么会出现这种情况,这里可以做一下数据探索。结合业务的实际情况进一步分析探究。
group_month_order_products=group_month.order_products.sum() print(group_month_order_products.head()) group_month_order_products.plot() plt.title("每月的产品购买量")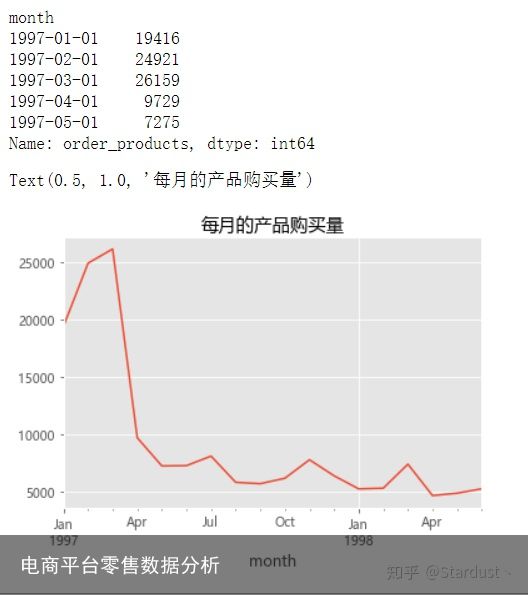
2.4每月的消费人数:前三个月每月的消费人数在8000-10000之间,后续月份,平均消费人数在2000左右。细心一点可以发现,每月的消费订单数略高于消费人数,这里也可以看出每月有小量的复购人群。
group_month_user=group_month.user_id.nunique() print(group_month_user.head()) group_month_user.plot() plt.title("每月的消费人数")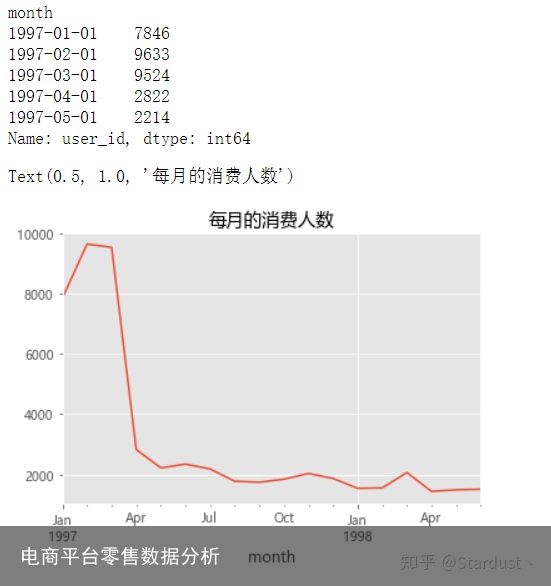
2.5每月用户平均消费金额:每月的用户平均消费金额在37.5元以上,1997年1月份最低,1998年11月最高,最高值约为57元。
avg_amount=group_month_amount/group_month_user avg_amount.head() avg_amount.plot() plt.title("每月用户平均消费金额")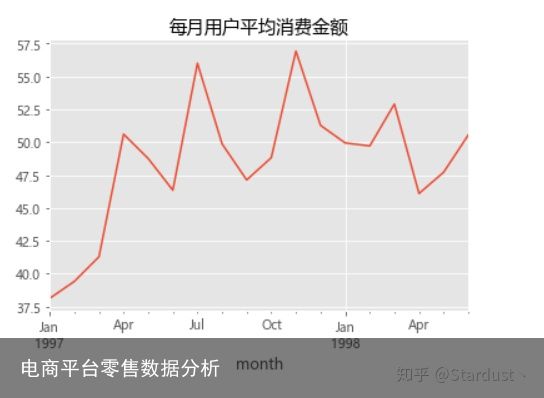
2.6每月用户平均消费次数:每月用户平均消费次数都在1次以上,1997年1月份最低,1998年10月最高,最高值约为1.4次。
avg_time=group_month_order/group_month_user avg_time.head() avg_time.plot() plt.title("每月用户平均消费次数")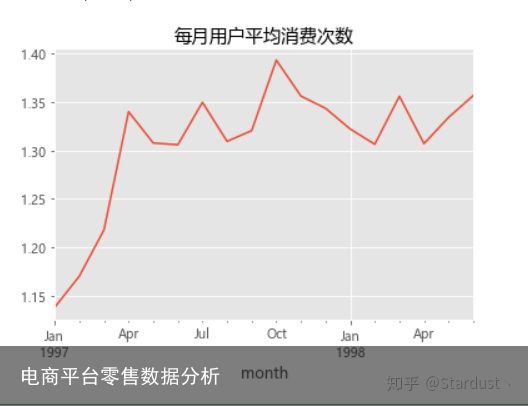
3. 用户个体消费分析(按用户)
3.1用户消费金额、产品购买量的描述性统计:
用户平均购买了7张CD,但是中位数只有3,说明小部分用户购买了大量的CD。用户平均消费106元,中位数只有43元,说明小部分用户的是高额消费。结合消费相关的数据可以此份数据符合二八法则,即小部分用户占了消费的大头。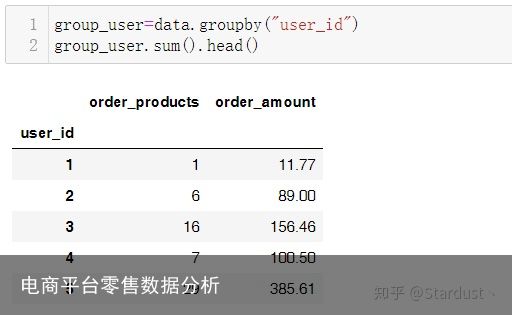 用户的消费金额
用户的消费金额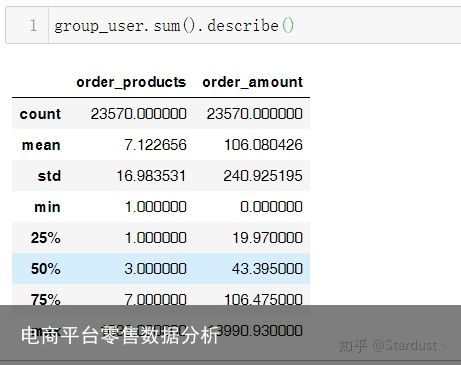 用户的消费金额的描述性统计
用户的消费金额的描述性统计3.2用户消费金额和产品购买量的散点图
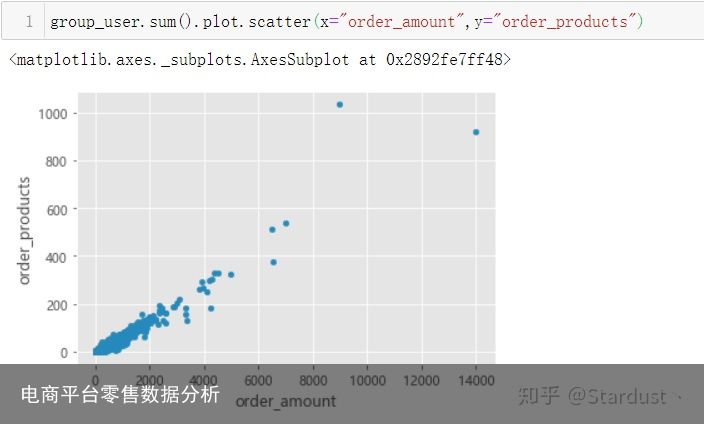
绝大部分数据集中分布,小部分极值对分析有一定的干扰,可以结合分布过滤掉极值再进行分析
group_user.sum().query("order_amount<4000").plot.scatter(x="order_amount",y="order_products")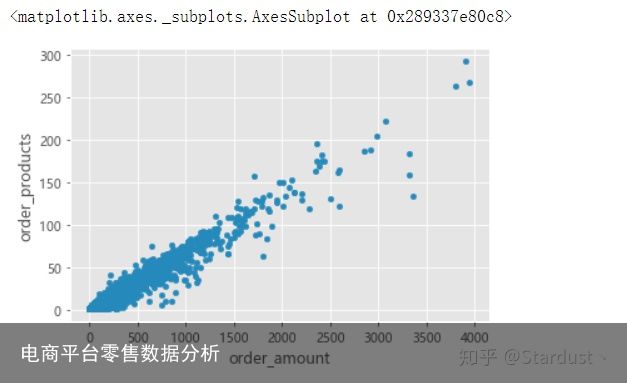 单纯从上面的散点图可以看出,用户的消费金额和产品购买量几乎成线性关系,购买的商品越过,消费金额越大,但是要考虑到产品单调性的影响。
单纯从上面的散点图可以看出,用户的消费金额和产品购买量几乎成线性关系,购买的商品越过,消费金额越大,但是要考虑到产品单调性的影响。3.3用户消费金额的分布图
和上面一样,数据过于集中,小部分的异常值会干扰我们的判断,所以要先过滤再来分析
可以明显地观察到,用户消费金额集中在0-100元,大约有17000名用户。3.4用户产品购买量的分布图
可以明显观察到,用户购买量集中在0-5张,大约有16000名用户。过滤条件"order_products<100"是借助了切比雪夫定理,所有数据中至少有96%的数据位于平均数5个标准差之内,剩下的4%的极值就可以过滤掉。3.5用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
user_cumsum=group_user.sum().sort_values("order_amount").apply(lambda x : x.cumsum()/x.sum()) print(user_cumsum.tail()) user_cumsum.reset_index().order_amount.plot() plt.xlabel("累计用户数") plt.ylabel("累计消费金额占比") plt.title("用户累计消费金额占比")由上图可以看出,约50%的用户仅贡献15%的消费金额,约70%的用户仅贡献20%的消费额度。而排名前5000的用户就贡献了约60%的消费额,也就是说当我们把这5000名用户维护好了,消费额就可能达到60%及以上。4. 用户消费行为
4.1用户首次购买的时间分布
首购是很多行业的一个重要维度,它和渠道息息相关,新客从哪里来,什么时候来可以拓展出很多运营方式。
用户第一次购买分布集中在前三个月,其中2月9日到2月25日之间有剧烈的波动,这里也可以拿出来做数据探索。4.2用户最后一次消费的时间分布
上图出现断崖式下跌,虽然前三个月用户数量迅猛增长,但是流失的也很多,后期相对比较稳定。大部分最后一次购买的时间集中在前三个月,刚好首购也是集中在这三个月,是否说明很多用户购买了一次之后就不再购买了,要进一步分析此流失用户是否是新用户。用户最后一次购买的时间分布比第一次购买的时间分布广,说明前面的客户有一部是慢慢流失的。随着时间的递增,最后一次购买的用户数量也在递增,消费呈现流失上升的状况,要跟运营反馈看看是不是用户维护或者我们自身的产品出现问题了。4.3多少用户仅消费一次
超过一半的用户只消费了一次,要进一步分析为啥用户只消费了一次,是产品问题还是价格问题还是服务问题等等。4.4用户分层
4.4.1RFM模型:
R:最近一次消费距今数(这里的距今数是用数据来源的最大天数来替代)F:消费频次(这里是用下单次数来表示)M:消费金额(这里是用下单总金额来表示)rfm=data.pivot_table(index="user_id" ,values=["order_dt","order_products","order_amount"] ,aggfunc={"order_dt":"max","order_products":"count","order_amount":"sum"}) rfm.head() def rfm_func(x): level=x.apply(lambda x :"1" if x>0 else "0") label=level.R+level.F+level.M d={ "111":"重要价值客户", "011":"重要保持客户", "101":"重要发展客户", "001":"重要挽留客户", "110":"一般价值客户", "010":"一般保持客户", "100":"一般发展客户", "000":"一般挽留客户" } result=d[label] return result rfm["label"]=rfm[["R","F","M"]].apply(lambda x :x-x.mean()).apply(rfm_func,axis=1) rfm.head()绿色部分是重要价值客户群,消费金额高,但是最近一次消费时间距“今”太远了,这部分客户要重点做好唤醒工作。8类客户中,重要保持客户的消费频次和消费金额最高,这类客户群要做好用户维护工作。8类客户中,一般发展客户的人数最多,这类客户的特点是消费频次少和消费金额低,但是最近一次消费时间很近,可以从客户的消费特点来针对性提高消费频次和消费金额,使其往重要保持客户方向靠近。RFM模型的划分重点是在于划分的标准,可以与业务沟通不断优化划分标准,划分后针对不同类型的客户群进行精细化运营,提升运营效率,提高消费金额,提升用户体验。4.4.2新用户、活跃用户、不活跃用户、回流用户
(return:回流,new:新客 ,unreg:未注册 ,active:活跃,unactive:不活跃)
pivot_counts=data.pivot_table(index="user_id" ,columns="month" ,values="order_dt" ,aggfunc="count").fillna(0) pivot_counts.head()def active_status(data): status=[] for i in range(18): if data[i]>0: if len(status)==0: status.append("new") else: if status[i-1]=="unreg": status.append("new") elif status[i-1]=="unactive": status.append("return") else: status.append("active") else: if len(status)==0: status.append("unreg") else: if status[i-1]=="unreg": status.append("unreg") else: status.append("unactive") return pd.Series(status) purchase=pivot_counts.apply(active_status,axis=1) purchase.columns=pivot_counts.columns purchase.head()purchase_count=purchase.replace("unreg",np.NaN).apply(lambda x :pd.value_counts(x)) purchase_count由上图可知:
蓝色是新用户,前三个月有大量的新用户涌入,后续新用户的增量都很小。与竞对、行业的新用户占比分析,看看是市场容量还是自身渠道或产品结构问题。红色是活跃用户,前三个月比较多,后续逐渐减少。用户的维护工作探究。紫色是回流用户,三个月后数据趋于稳定,加大回流用户占比,探究更好的唤醒方案。灰色是流失/不活跃用户,数量很大,基本上每月在都是20000以上,减少流失用户,对流失用户进一步分析(比如流失用户的最后步骤是什么,看看都是哪些地方的造成用户流失,及时发现问题)4.5用户购买周期
4.5.1用户购买周期的描述性统计:
用户购买周期:用户相邻两个订单的时间间隔用户的平均购买周期是68天,最小值0,最大值533天,看看此购买周期是否合理,如何缩小购买周期。4.5.2用户购买周期分布
订单周期呈指数分布绝大部分用户的购买周期都低于100天,如何将购买周期为50-100天的用户缩减到购买周期为0-50天。4.6用户生命周期描述性统计和用户生命周期分布
用户平均生命周期134天,但中位数仅0天。用户的生命周期分布受只购买一次的用户影响比较严重,可以过滤后再进行分析user_life_d=(user_life["max"]-user_life["min"]).reset_index()[0]/np.timedelta64(1,"D") print(user_life_d[user_life_d>0].head()) user_life_d[user_life_d>0].describe()排除了只购买一次的用户(生命周期为0天)的影响后得到,用户平均生命周期276天,中位数302天。此数据的衡量要与竞对和行业大盘的数据比较分析。5. 复购率和回购率分析
5.1复购率:时间窗口为月,自然月内,购买多次的用户占总购买人数之比。
purchase_duplicate=pivot_counts.applymap(lambda x : 1 if x>1 else 0 if x==1 else np.NaN) purchase_duplicate.head(10)前3个月因为有大量新用户涌入,而且这批用户只购买了一次,所以前三个月的复购率较低后期复购率稳定在20%左右,此数据的衡量要与竞对和行业大盘的数据比较分析。5.2回购率:时间窗口为月,本月消费了在下月还消费的用户数占本月消费用户数之比。
def purchase_back(data): status=[] for i in range(17): if data[i]==0: status.append(np.NaN) else: if data[i+1]==1: status.append(1) else: status.append(0) status.append(np.NaN) return pd.Series(status,index=pivot_back.columns) pivot_back=pivot_counts.applymap(lambda x : 1 if x>0 else 0) purchase_back=pivot_back.apply(purchase_back,axis=1) purchase_back.head(10)前3个月因为有大量新用户涌入,而且这批用户只购买了一次,所以前三个月的回购率较低后期复购率稳定在30%左右,此数据的衡量要与竞对和行业大盘的数据比较分析。四、小结
1、用户消费趋势:前三个月有大量的新用户涌入,消费金额、订单数、产品购买量均达到高峰,后续趋于稳定。总结新用户涌入的机会点,创造更多的此类契机。前三个月消费订单数都在10000笔左右,后续的订单数平均为2500笔;前三个月产品的购买量达到20000以上,后续的购买量平均为7000,前三个月消费人数在8000-10000之间,后续的消费人数平均为2000.
2、用户个体消费方面:小部分用户购买了大量的产品,产生了大额消费,拉高了平均消费金额。用户消费金额集中在0-100元的大约有17000名用户;用户购买量集中在0-5张的大约有16000名用户。运营可以“0-100元”和“0-5张”这两部分数据做相应的营销活动,比如满150减30元或者买6赠1之类的活动。50%的用户仅贡献了15%的消费额,15%的用户贡献了60%的消费额,大致符合二八法则。
3、用户消费行为方面:首购时间和最后一次购买时间,集中在前三个月,可以初步推出很多用户购买了一次后就不再进行购买,针对此类型用户的购买行为进一步分析,找出用户仅消费一次的原因,进一步解决问题。
4、根据RFM模型划分的8类型客户进行针对性的精细化运营。像重要保持客户的消费频次和消费金额最高,但是人数却比较少,而一般发展客户的消费频次和消费金额比较低,但是人数却是最多的,所以我们要通过精细化运营,将一般发展客户更多的发展成为重要保持客户。
5、从用户分层来看:新用户从第4月份以后很少新增;活跃用户下降,流失和不活跃用户增多,这些问题都要针对性去解决。比如新用户更多的是关注渠道来源、转化,活跃用户在于用户的运营,流失和不活跃在于用户的运营。
6、用户的购买周期、生命周期:平均购买周期是68天,平均生命周期是276天,针对此数据要做相应的运营方案来减少购买周期和生命周期。
7、复购率和回购率:复购率稳定在20%,回购率稳定在30%,要与竞对和行业大盘的数据比较分析。如果我们的复购率比竞对的低,进一步分析用户行为日记看看是什么原因导致的复购低。
