







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
得到实验的数据后,该如何进行数据分析?(实验得到的数据最终将以什么形式展现出来)
 2023-05-16
2023-05-16 浏览次数:次
浏览次数:次 返回列表
返回列表社会科学的实验法最大的好处在于,不需要特别复杂的数据分析和有争议的假设,也不像案例研究那样难以追溯,实验法的数据和分析过程相对简单、透明。好的研究设计不需要事后复杂的数据分析就可以评估因果效应。
random allocation—chance imbalance—statistical techniques(comparing a treatment effect a with null of no effect,identifying a range of values within which the treatment effect falls at a particular confidence level.)
关注statistical power(在给定尺度下检测到因果效应的可能性,即拒绝零假设的可能性)。H0:没有因果效应。e.g.,0.9的power意味着,如果在给定尺度下出现了差异,同时实验进行了很多次,那么在这很多次实验中,有90%的实验可以在实验组和控制组之间发现显著的差异。一般推荐的power是0.8-0.9。同时样本大小会影响power。实验设计,比如所使用的随机分配的方法,也会影响power。
报告哪些数据?:①结果变量的均值和标准差,②估计的因果效应大小和置信区间,③比较不同组的均值,计算差异的显著性,从而检验某一理论。④generalization:从部分推及总体。
当我们的实验设计非常复杂(比如使用了block or cluster randomisation或者实验实施过程中出现问题),可以用哪些数据分析方法帮助我们解决问题呢?
一、
控制变量/协变量的使用。适用情况:①实验在随机分配的阶段出现了重大失误,导致在实验组和控制组中,除了X以外的变量存在重大的系统性偏误。②实验的随机分配是合理的,但仍有一些偶然性的偏差。这种情况使用协变量就要谨慎,需要明确协变量和因变量有无很强的关联。
二、
ANOVA(analysis of variance)。适用情况:估计factorial design的每个因素的影响如何,结合起来的因素影响又如何。column means(factor A),row means(factor B),ANOVA不产生系数,只是一种描述性统计。
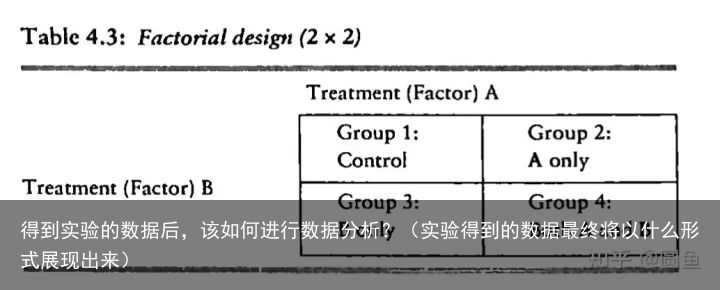
三、
multiple regression(将每一个因素编码为0和1)。适用于factorial design。问题:干预变量的回归系数是simple effect,而不是main effect,结果很可能和ANOVA的结果不匹配除非编码非常合理。使用该方法的时候要谨慎,出于理解而非习惯性的动作。
四、
subgroup analysis,计算组间(subgroup)的差异,把这种差异叫做异质性干预效果(heterogeneous treatment effect),同时我们会把某一个组的平均干预效应叫做有条件的平均干预效应(conditional average treatment effect)。
方法一:将数据分组,单独分析每个组。
方法二:分组变量(比如性别,男/女)、干预变量(干预/不干预),2*2的结构,类似于factorial experiment,用ANOVA或者哑变量回归估计交互效应(interaction effect)。关键在于,组间分析必须要有理论前提作为支撑,不要做“检测所有可能的情况然后报告显著性的那部分”这样的事情,这种做法很可能只是发现一些偶然性的东西而不是真正的因果关系。
