







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
数据分析实战项目:用户消费行为分析(用户的消费特征分析是什么)
 2023-05-21
2023-05-21 浏览次数:次
浏览次数:次 返回列表
返回列表项目背景:为了平台创造出更多利润,并且能够合理的投放广告,使用网站18个月销售数据进行分析,根据复购率,回购率,高额消费用户等指标以及消费模型进行针对性的客户管理与维护。
数据来源:
user_id:用户idorder_dt:购买日期order_products:购买数量order_amount:购买金额分析思路如下:
数据读取及观察:导入numpy、pandas、matplotlib库,读取并检查数据;数据处理:缺失值的处理,数据类型转换;按月数据数据分析:每月的消费总金额、每月的消费次数、每月的产品购买量、每月的购买人数;用户个体消费数据分析:用户消费金额和消费次数的描述统计,用户消费金额和消费次数的散点图、用户消费金额的分布图(二八法则)、用户消费次数的分布图、用户累计消费金额的占比;用户消费行为分析:用户第一次消费时间、用户最后一次消费时间、新老客消费比、用户分层、用户购买周期、用户生命周期。一、数据准备及数据清洗
import numpy as np import pandas as pd from matplotlib import pyplot as plt import datatime #内嵌视图,且可视化时不需要plt.show(). #负数坐表正常显示 %matplotlib inline plt.rcParams[axes.unicode_minus]=False columns = [user_id,order_dt,order_products,order_amount] df1 = pd.read_table("D:\\CDNOW_master.txt",names = columns,sep = \s+) df1.head() df1.info()查看前五行数据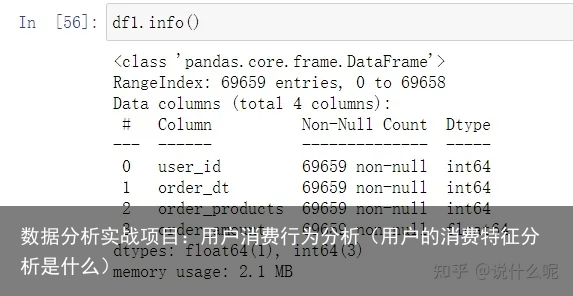 数据概括
数据概括可以看出,数据无缺失值,但是order_dt的数据类型是int,需要先转换成datetime格式
#转换成是datetime格式 df1[order_dt] = pd.to_datetime(df1.order_dt,format = %Y%m%d) #后面要按月分析,添加一个month字段,来表示订单日期所在的月份,格式为对应月份的第一天 df1[month]=df1.order_dt.values.astype(datetime64[M]) df1.describe() df1.head()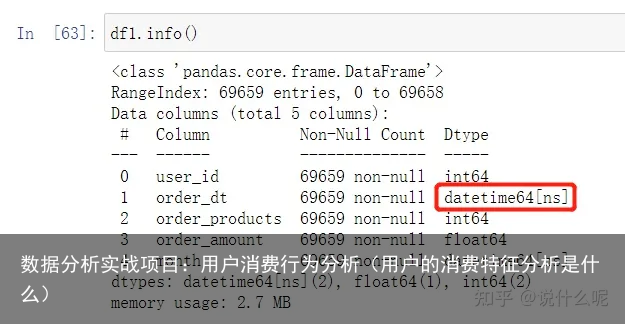 查看更改后的时间格式
查看更改后的时间格式 查看数据前五行# 通过对用户ID分组,并进行求和,再进行描述性统计
df1.groupby(user_id).sum().describe()
查看数据前五行# 通过对用户ID分组,并进行求和,再进行描述性统计
df1.groupby(user_id).sum().describe()
观察数据,从用户ID看,每位用户平均购买7张CD,最多的用户购买了1033张,属于狂热用户了(观察异常值)。用户的平均消费金额(客单价)106元,标准差是240,结合分位数和最大值看,平均值略大于第三分位数,肯定存在小部分的高额消费用户。
第一部分总结:在这一部分,我们了解项目背景,明确目的,整理分析思路,接着对数据进行观察,进行数据清洗,代码方面没什么难点。
二、按月数据分析
#对数据按月份分组 grouped_month = df1.groupby(month) #制定可视化图分析不同维度用户消费趋势 fig = plt.figure(figsize = (8,12)) ax1 = fig.add_subplot(4,1,1) ax2 = fig.add_subplot(4,1,2) ax3 = fig.add_subplot(4,1,3) ax4 = fig.add_subplot(4,1,4) # 按月金额数(图1) ax1.plot(grouped_month.order_amount.sum(),c=blue) ax1.set_title(每月消费总金额变化趋势) ax2.plot(grouped_month.user_id.count(),c=blue) ax2.set_title(每月订单数变化趋势) ax3.plot(grouped_month.order_products.sum(),c=blue) ax3.set_title(每月消费产品购买量) ax4.plot(grouped_month.user_id.apply(lambda x:len(x.drop_duplicates())),c=blue) ax4.set_title(每月用户数变化趋势)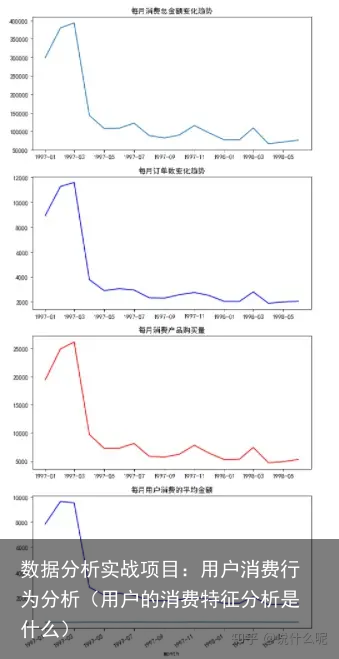
图一: 消费金额在前三个月达最高峰,后期消费金额较为平稳,有轻微下降趋势
图二: 前三个月订单数在10000笔左右,后续月份的订单数在2500左右
图三: 产品购买量 呈现早期购买量多 后期下降趋势
图四: 每月消费人数小小于每月的消费次数(订单数),但是区别不大,前三个月每月的消费人数在8000-10000之间,后续月份平均2000左右,一样是前期消费人数多,后期平稳下降趋势
出现这种状况,假设问题是出现在用户身上,早期时间段的用户有异常值,或者由于各类促销营销,由于只有消费数据,无法进一步进行判断
#每月用户消费的平均金额(图5) ((grouped_month.order_amount.sum())/(grouped_month.user_id.apply(lambda x: len(x.drop_duplicates())))).plot() plt.title(每月用户消费的平均金额) #每月用户消费的平均次数(图6) ((grouped_month.user_id.count())/(grouped_month.user_id.apply(lambda x : len(x.drop_duplicates())))).plot() plt.title(每月用户消费的平均次数)
图五:前三个月用户平均消费在40元左右,后续月份用户平均消费金额相比前三个月有一些提高,用户平均消费金额在区间[45,57.5]之间
#每月用户消费的平均次数(图6) ((grouped_month.user_id.count())/(grouped_month.user_id.apply(lambda x : len(x.drop_duplicates())))).plot() plt.title(每月用户消费的平均次数)
图六:前三个月用户消费的平均次数逐渐增加,后续月份用户的平均消费次数在1.35次左右
#数据透视查看,按月分别对用户购买金额求和,订单数求和,用户人数计数 df1.pivot_table(index=month, values = [order_products,order_amount,user_id], aggfunc = {order_products:sum, order_amount:sum, user_id:count}).head()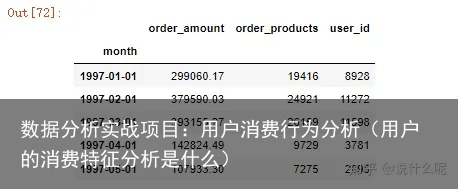
第二部门总结:通过按月数据分析,我们简单了解了消费趋势,主要是用了groupby 分组函数。商品在刚上市的效果还是不错的,前三个月是达到了顶峰,说明初期的广告投放以及营销是有效果的,后面下降比较明显,可以重点关注促活方面。
三、用户个体数据分析
用户消费金额,消费次数描述统计grouped_user = df.groupby(user_id) grouped_user.sum().describe()
用户平均购买量7张CD,标准差17,波动比较大,但是中位值只有3,说明小部分用户购买了大量的CD
用户平均消费为106元,中位值为43,也有极值干扰
用户消费金额和消费次数散点图df1.plot.scatter(x =order_amount,y=order_products,title = 订单散点图)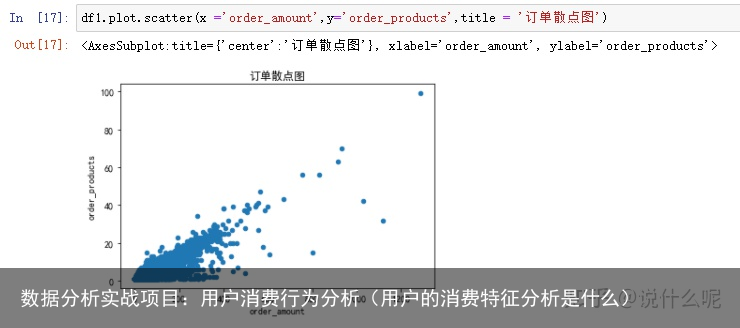
观察用户消费金额和消费次数的散点图,可以直观的看到订单金额和数量的分布情况,大部分订单在订单金额在0-400,订单数量在0-40的,极值极少,只有几个订单只有几个。
#每位用户的消费金额与消费商品数散点图,并用query过滤掉订单金额大于4000的订单,减小极值干扰 group_userid.sum().query(order_amount < 4000).plot.scatter(x=order_amount,y=order_products)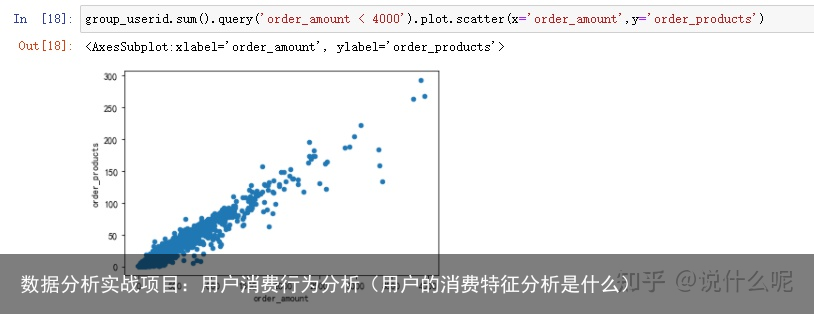
绘制用户的散点图,用户也比较健康,而且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。消费能力特别强的用户有,但是数量不多
group_userid.sum().order_amount.plot.hist(bins=20)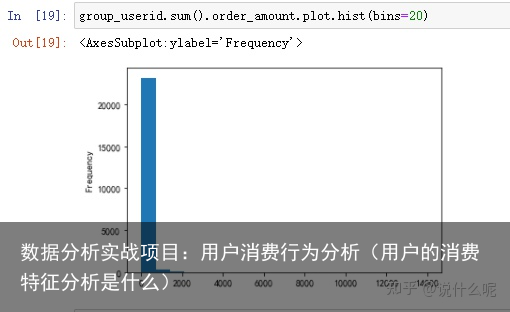
从直方图上看,绝大部分用户消费能力都不高,绝大部分呈现集中在很低的消费档次。高消费用户几乎看不到,这符合消费规律,即“二八法则”
group_userid.sum().query(order_products<100).order_amount.hist(bins=40) plt.title(消费金额分布图) 减少极值后的消费金额分布
减少极值后的消费金额分布消除极值影响后,数据就显得更加直观。
group_userid.sum().query(order_products<100).describe()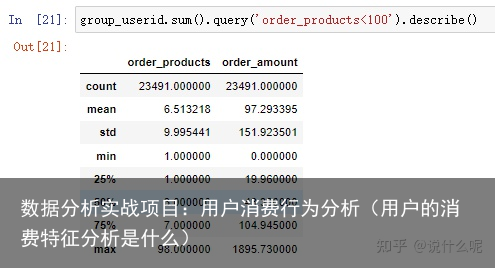 消除极值后的描述统计# 用户消费分布图
plt.figure(figsize=(12,5))
group_userid.count().query(order_products<100).order_amount.hist(bins=40)
plt.title(消费次数分布图)
消除极值后的描述统计# 用户消费分布图
plt.figure(figsize=(12,5))
group_userid.count().query(order_products<100).order_amount.hist(bins=40)
plt.title(消费次数分布图)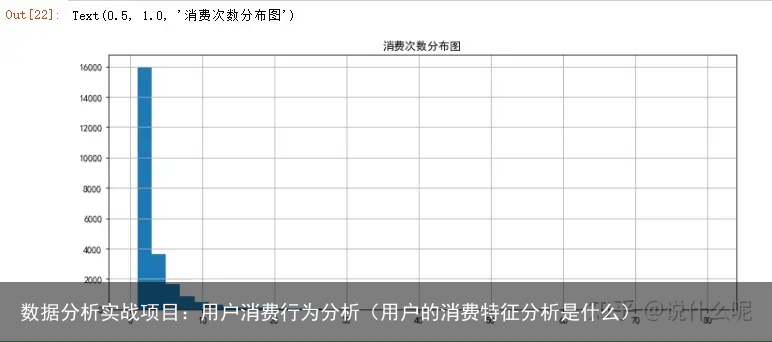
从直方图上,消费次数和金额差不多,满足“二八法则”
用户累计消费金额占比#按ID分组,并求和,再对订单金额进行排序(默认从小到大),最后通过匿名函数对每一行进行累计求和占比 user_cumsum=group_userid.sum().sort_values(order_amount).apply(lambda x: x.cumsum()/x.sum()) plt.subplot(211) user_cumsum.reset_index().order_amount.plot(figsize=(8,8)) plt.title(消费金额累计百分比) plt.subplot(212) user_cumsum.reset_index().order_products.plot() plt.title(消费商品数累计百分比)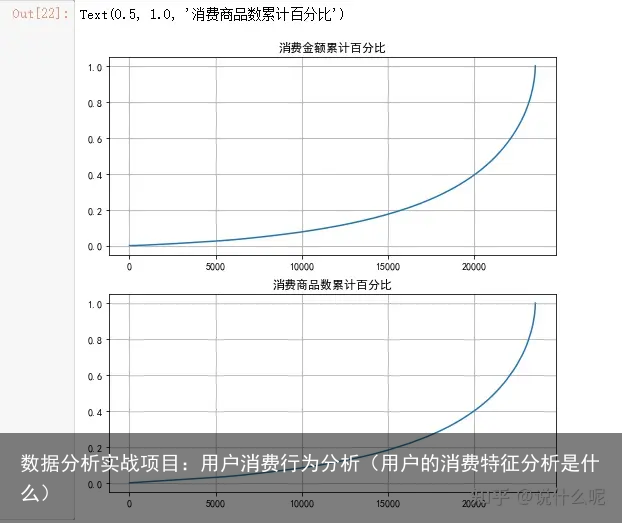
可以看出有一半的用户只贡献了15%的销售额度,而排名较高的前5000名用户就贡献了60%的销售额,说明我们维护好这5000用户就能达到一半以上的销售额,这是大客户
首次购买时间分布# 计算第一次购买时间分布 df1[order_dt].groupby(df1[user_id]).min().value_counts().plot(figsize=(12,5)) #等同于grouped_user.min().order_dt.value_counts().plot(figsize=(12,5))可以看到2月份新增用户明显减少,可能是投放方式进行了改变
#按月统计购买次数 group_userid.min().month.value_counts() group_userid.max().month.value_counts().plot() plt.title(最后一次消费时间分布)观察用户的最后一次消费时间。用户最后一次消费比第一次消费分布广,大部分最后一次消费集中在前三个月,说明很多客户购买一次就不再进行购买。随着时间的增长,最后一次购买数也在递增,消费呈现流失上升的情况,用户忠诚度在慢慢下降。
# 计算只消费了一次的用户人数(结果为:11908) one_consumed=group_userid.count().query(order_dt==1).order_dt.count() # 计算总的消费人数(结果为:23570) all_consumed=group_userid.count().order_dt.count() #计算多少用户只消费一次 one_consumed/all_consumed超过一半的用户只消费了一次
grouped_month_user=df1.groupby([month,user_id]) # 用当月用户订单日期最小值与用户订单日期最小值联结 tmp=grouped_month_user.order_dt.agg([min]).join(group_userid.order_dt.min()) # 判断用户当月订单日期最小值是否与用户订单日期最小值相等,新建字段new,new代表老客户 tmp[new]=(tmp[min]==tmp.order_dt) # 重置索引列,并按月分组,作新客占比折线图 tmp.reset_index().groupby(month).new.apply(lambda x: x.sum()/x.count()).plot() plt.title(新客占比百分比)可以看出,只有前三个月的新客占比不为零,后续月份新客占比百分比为零,这说明只有前三个月有新用户的增加,后续月份都是老顾客在消费。
用户分层
RFM模型
R:消费最后一次消费时间的度量,数值越小越好F:消费的总商品数,数值越大越好M:消费的总金额,数值越大越好# RFM rfm = df1.pivot_table(index = user_id, values = [order_products,order_amount,order_dt], aggfunc = {order_dt:max, order_amount:sum, order_products:sum}) rfm.head()# /np.timedelta64(1,D) 消除单位 进行重命名 rfm[R] = -(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1,D) rfm.rename(columns = {order_products:F,order_amount:M},inplace=True) rfm.head() #应用匿名函数,判断每一行值与平均值大小关系 rfm[[R,F,M]].apply(lambda x:x-x.mean()).head()# 客户层次的定义,RFM得分可根据业务定义打分,也可以通过K-means聚类模型,得出不同相似程度的数据集,并且根据每一个数据集的特点进行客户定义 def rfm_func(x): level = x.apply(lambda x:1 if x>= 0 else 0) # 字符串拼接 # 111,R>0,是距离平均消费时间要久,R越大 说明没有消费时间越久 ,F >0 M>0,消费次数和金额也是较高的,重要价值客户,依次类推 label = level.R + level.F + level.M d = { 111:重要价值客户, 011:重要保持客户, 101:重要挽留客户, 001:重要发展客户, 110:一般价值客户, 010:一般保持客户, 100:一般挽留客户, 000:一般发展客户 } result = d[label] return result rfm[label] = rfm[[R,F,M]].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1) rfm.head()rfm.groupby(label).sum()可以看出,重要保持客户对于消费总金额的占比远大于其他客户的占比,这说明绝大部分收益是由重要保持客户贡献的,只要能保证这部分客户不流失和增加,那么公司收益将得到有力保障
rfm.groupby(label).count()use_c = rfm.groupby(label).count() plt.axis(equal) labels = [一般价值客户,一般保持客户,一般发展客户,一般挽留客户,重要价值客户,重要保持客户,重要发展客户,重要挽留客户] plt.pie(use_c[M], autopct=%3.1f%%, labels = labels, pctdistance=0.9, labeldistance = 1.2, radius=3, startangle = 15)从RFM分层可知,大部分用户为重要保持客户,但是这是由于极值的影响,所以RFM的划分应该以业务微赚
尽量用小部分的用户覆盖大部分的额度不要为了数据好看划分等级极值会拉均值根据数据可以和业务相结合,如何提升一些重要的指标用户状态分层
将用户状态分为unreg(未注册)、new(新客)、active(活跃用户)return(回流用户)和unactive(不活跃用户)
pivoted_counts = df1.pivot_table(index = user_id, columns = month, values = order_dt, aggfunc = count).fillna(0) # pivoted_counts.head() pivoted_counts.head() # 按月份进行对比,1月份哪些是购买的,再去对比二月份哪些是购买的# 消费过的为1 ,没消费过的为0
若本月没有消费若之前是未注册,则依旧为未注册若之前有消费,则为流失/不活跃其他情况,为未注册若本月有消费若是第一次消费,则为新用户若之前有过消费,则上个月为不活跃,则为回流若上个月为未注册,则为新用户除此之外,为活跃data_purchase = pivoted_counts.applymap(lambda x: 1 if x > 0 else 0) # 用户状态分层 def active_status(data): status = [] for i in range(18): #若本月没有消费 if data[i] == 0: if len(status) > 0: if status[i-1] == unreg: status.append(unreg) else: status.append(unactive) else: status.append(unreg) #若本月消费 else: if len(status) == 0: status.append(new) else: if status[i-1] == unactive: status.append(return) elif status[i-1] == unreg: status.append(new) else: status.append(active) return pd.Series(status, index = pivoted_counts.columns) purchase_stats = data_purchase.apply(active_status,axis=1) purchase_stats.head() # 处理未参与人 purchase_status_ct = purchase_stats.replace(unreg,np.NaN).apply(lambda x : pd.value_counts(x)) purchase_status_ct #将上面透视表转置 purchase_status_ct.fillna(0).T.head()#作用户状态分层面积图 purchase_stats_ct=purchase_status_ct.fillna(0).T purchase_stats_ct.plot.area(figsize=(12,5)) plt.title(用户分层)由上可知不同客户活跃状态,根据业务需求采取不同的运营策略,如拉新,引流,促活,召回等
四、用户复购率和回购率分析
用户购买周期
#计算用户相邻订单日期的差值,其中shift()函数是指将数据进行移动,默认axis=0 order_diff=group_userid.apply(lambda x: x.order_dt-x.order_dt.shift()) order_diff.head(10)order_diff.describe()#作用户消费周期分布: (order_diff/np.timedelta64(1,D)).hist(bins=20) plt.title(用户消费周期分布)用户的生命周期受只购买一次的用户影响比较厉害(可以排除)用户均消费134天,中位数仅0天,明显受到只购买一次用户的影响明显#usertime_diff代表用户消费首次订单与最后一次订单间隔时间 usertime_diff=df1[order_dt].groupby(df1[user_id]).max()-df1[order_dt].groupby(df1[user_id]).min() usertime_diff=usertime_diff.reset_index() usertime_diff=usertime_diff[order_dt]/np.timedelta64(1,D) usertime_diff[usertime_diff>0].hist(bins=40) plt.title(用户生命周期分布)这是双峰趋势图。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了
复购率和回购率数据分析
复购率:自然月内,购买多次的用户占比
回购率:曾今购买过的用户在某一时期内的再次购买占比
注:指标的定义和标准是根据不同公司的业务形态而变化
# 作透视表,计算客户每个月的消费次数 pivoted_counts=df1.pivot_table(index=user_id, columns=month, values=order_dt, aggfunc=count).fillna(0) pivoted_counts.head()# 购买大于1次的 赋值为1 ,然后小于等于1 的 如果是购买次数是0,则赋值为空,否则 就是购买一次,赋值为0 purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0) purchase_r.head()(purchase_r.sum()/purchase_r.count()).plot(figsize=(10,4)) plt.title(复购率)复购率稳定在20%左右,前三个月因为有大量新用户涌入,而这些用户只购买了一次,所以导致复购率降低,后续月份用户数量比较稳定,所以复购率也稳定在21%左右,即后续月份每月有大概21%的用户会在一个月内消费两次以上回购率
data_purchase.head()def purchase_back(data): status = [] for i in range(17): if data[i] == 1: # 本月进行过消费 if data[i+1] == 1: # 下一月是否进行消费 status.append(1) #消费为1 回购了 if data[i+1] == 0: status.append(0) # 未消费则为0 没有回购 else: status.append(np.NaN) # 之前没消费则不计 status.append(np.NaN) # 最后一个月没有判断需要补上 return pd.Series(status,data_purchase.columns) #对透视表应用函数purchase_back: purchase_b = data_purchase.apply(purchase_back, axis =1) purchase_b.head()计算回购率
0 表示上个月购买了,下个月没有进行消费,则是没有回购 ,1代表当月消费过次月依旧消费,表示回购了NAN表示当月没有消费(不进行计算)(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4)) plt.title(回购率)前三个月因为有大量的新用户涌入,但是超过一半的人只消费了一次,所以前三个月回购率比较低,后续月份用户人数比较稳定,回购率也比较稳定,稳定在30%左右,即当月消费人数中有30%左右的用户会在下一个月再次消费
