







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
Python医疗数据分析(python与医药大数据处理)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表Python 作为一个有效数据处理工具,能大大延展我们挖掘数据价值的能力。本文以一个医院数据的案例,来展示Python医疗数据分析的过程。
数据分析的基本步骤
数据分析基本思路和步骤如下:
提出问题理解数据数据清洗构建模型数据可视化一、提出问题
要分析的数据源如下:
朝阳医院2018年销售数据.xlsx262.1K · 百度网盘我们要从这个样本数据里面分析出,月均消费次数,月均消费金额是多少,每次消费的客单价等关键指标。
二、理解数据
原表格中总共有六个字段,6578条记录,表格截图如下:
购药时间:药品销售时间,格式是日期格式。
社保卡号:购买药品的社保卡号,文件中数字是以文本形式存储的,所以左上角有一个绿色小图标,全部转换成数字格式之后,绿色小图标消失,数字靠右显示。
商品编码:药品编码,数字格式存储。
商品名称:药品名称,文本或者字符串的格式
销售数量、应收金额、实收金额,三个栏目都是数字格式。
三、数据清洗
1、使用pandas类对Excel进行数据处理,将Excel数据导入pandas二维数据结构dataframe中。
import pandas as pd from datetime import datetime # 读取Excel数据,导入pandas的数据框hospitalDf中 fileNameStr=E:\数据分析\朝阳医院2018年销售数据.xlsx hospitalxls=pd.ExcelFile(fileNameStr) hospitalDf=hospitalxls.parse(Sheet1)2、为方便数据分析,我们筛选出销售数量大于0的数据子集进行分析,暂不考虑退货及销售错误的因素。
querySer=hospitalDf.loc[:,销售数量]>0 # 筛选出销量大于0的子集 subDf=hospitalDf.loc[querySer,:]3、删除“购药时间”和“社保卡号”两列中的空值,筛选出的子集按照购药时间进行升序排列,由于重新排序,将列的序号也重置,使之能够从小到大排列。把经过上述数据清洗后的表格存在一张新的Excel表中,并重新命名。至此,数据清洗步骤完成。
# 删除购药时间和社保卡号两列中的空值 newDf=subDf.dropna(subset=[购药时间,社保卡号],how=any) newDf = newDf.sort_values(by=购药时间,ascending=True) # 按照购药时间进行升序排列 newDf = newDf.reset_index(drop=True) # 列表序号重置 newDf.to_excel(E:\数据分析\朝阳医院新数据.xlsx)我们打印出经过上面数据清洗后,数据表的行列值,可以看到原表6578条记录变为6532条记录。
print (newDf.shape)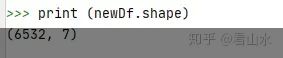
新的数据表如下:
朝阳医院新数据.xlsx256K · 百度网盘四、构建模型
1、月均消费次数 = 总消费次数 /月份数
这里总消费次数为表格中的行数,每一行代表一次消费记录。月份数我们可以根据购药时间跨度先算出收尾跨度天数,如果天数在4年之内,直接除以30天取整就可以(对于年数相隔比较少的,采用这种算法就可以,相隔比较大的年数,需要精确计算)。
# 总消费次数等于总消费记录,有多少条消费记录消费就有多少次 totalcount = newDf.shape[0]#总消费次数 print (totalcount)消费次数返回结果:
 # 购药时间最后一条记录和第一条记录的时间相减,结果除以30取整,得到月份数
startdate = newDf.loc[0,购药时间]
enddate = newDf.loc[totalcount-1,购药时间]
startdt = startdate.split()
enddt = enddate.split()
startdtime = datetime.strptime(startdt[0], "%Y-%m-%d")
enddtime = datetime.strptime(enddt[0], "%Y-%m-%d")
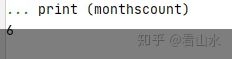
monthscount = (enddtime-startdtime).days//30 #月份数
print (monthscount)
# 购药时间最后一条记录和第一条记录的时间相减,结果除以30取整,得到月份数
startdate = newDf.loc[0,购药时间]
enddate = newDf.loc[totalcount-1,购药时间]
startdt = startdate.split()
enddt = enddate.split()
startdtime = datetime.strptime(startdt[0], "%Y-%m-%d")
enddtime = datetime.strptime(enddt[0], "%Y-%m-%d")
monthscount = (enddtime-startdtime).days//30 #月份数
print (monthscount)
月份数返回结果:
 #月均消费次数 = 总消费次数/月份数
avgcount = totalcount/monthscount
print (avgcount)
#月均消费次数 = 总消费次数/月份数
avgcount = totalcount/monthscount
print (avgcount)
月均消费次数返回结果:

得到月均消费次数约为1088.67次。
2、月均消费金额 = 消费总金额/月份数
消费总金额可以将表格中所有记录的实收金额求和,月份数可以复用上面指标计算的代码。
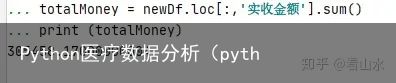
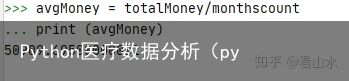
#月均消费金额 #总消费金额/月份数 #计算总消费金额 totalMoney = newDf.loc[:,实收金额].sum() print (totalMoney) avgMoney = totalMoney/monthscount print (avgMoney)实收金额求和结果:
月均消费金额计算的结果:
3、客单价 = 总消费金额/总消费次数
每一次消费的平均价格为客单价,可用上面指标中求出的总消费金额除以总的消费次数计算出来。复用上面计算出的指标值,进行简单的除法计算得到结果。
#客单价 #总消费金额/总消费次数 avgprice = totalMoney/totalcount print (avgprice)客单价计算返回结果:

总结:经过上面分析,我们根据数据表计算出了几个主要业务指标,也学会了一些简单的Python处理Excel数据表以及数据分析的基本方法。后续涉及Python的数据可视化,我们在后面讨论。
