







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
医院销售数据分析(医院销售额)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表1、基础知识
1)一维数据分析
Numpy-Array:# 定义 import numpy as np a = np.array([2, 3, 4, 5]) # 查询元素 a[0] # 切片访问 a[1:3] # 循环访问 for i in a: # 数据类型 dtype # 统计功能(比列表优秀的地方) mean()/std() # 向量化计算:向量相加/乘以标量 # 参数axis=0/1,分别针对列/行进行操作Pandas-Series:# 定义 import pandas as pd stockS = pd.Series([54.74, 190.9, 173.14, 1050.3, 181.86, 1139.49], index = [腾讯, 阿里巴巴, 苹果, 谷歌, Facebook, 亚马逊,]) # 描述统计 stockS.describe() # 删除缺失值 dropna() # 填充缺失值 s1 = pd.Series([1, 2, 3, 4], index = [a, b, c, d]) s2 = pd.Series([10, 20, 30, 40], index = [a, b, e, f]) s3 = s1.add(s2, fill_value = 0)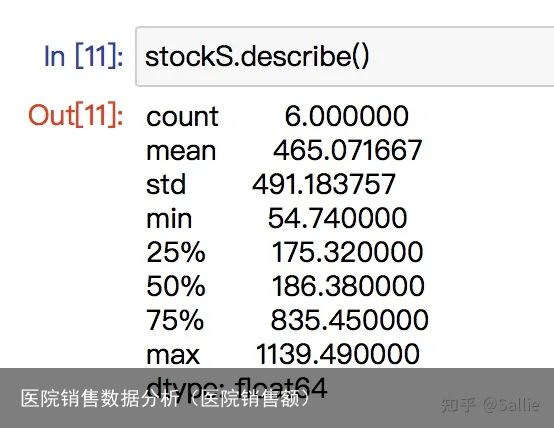 图1 描述统计结果
图1 描述统计结果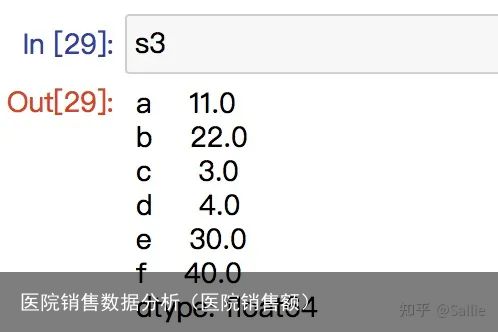 图2 填充缺失值
图2 填充缺失值2)二维数据分析
Numpy-Array:# 定义 a = np.array([1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]) # 查询元素 a[0, 2] # 获取某一行 a[0, :] # 获取某一列 a[:, 0] # 参数axis=0/1,分别针对列/行进行操作Pandas-DataFrame:针对每列数据类型不一样的情况# 定义:先建立字典,再将字典放进数据框中 salesDict = {购药时间 : [2018-01-01 星期五, 2018-01-02 星期六, 2018-01-06 星期三], 社保卡号 : [001616528, 001616528, 0012602828], 商品编号 : [236701, 236701, 236701], 商品名称 : [强力VC银翘片, 清热解毒口服液, 感康], 销售数量 : [6, 1, 2], 应收金额 : [82.8, 28, 16.8], 实收金额 : [69, 24.64, 15]} from collections import OrderedDict salesOrderedDict = OrderedDict(salesDict) salesDf = pd.DataFrame(salesOrderedDict) # iloc根据位置查询 salesDf.loc[0,1]/salesDf.loc[0, :]/salesDf.loc[:, 0] # loc根据索引值查询 salesDf.loc[0, 商品名称]/salesDf.loc[0, :]/salesDf.loc[:, 商品名称] # 查询某几列 salesDf[商品名称, 销售数量] # 切片功能:指定范围 salessDf.loc[0:2, 商品名称:销售数量] # 通过条件判断筛选 querySer = salesDf.loc[销售时间]>1 salesDf.loc[querySer, :] # 描述统计分析 salesDf.describe() # 有多少行,多少列 salesDf.shape2、销售数据分析案例
1)明确问题
月均消费次数月均消费金额客单价2)理解数据
导入数据import pandas as pd salesDf = pd.read_excel(/Users/zsj/Desktop/医院销售数据.xlsx, dtype=str)数据集字段 图3 数据集信息
图3 数据集信息共包含7个字段,分别为:
购药时间:购买药品的时间
社保卡号:顾客社保卡号,为顾客唯一标识
商品编码:药品的唯一编码
商品名称:药品名称
销售数量:顾客单次购买药品数量
应收金额:药品售价
实收金额:最终成交金额
描述统计分析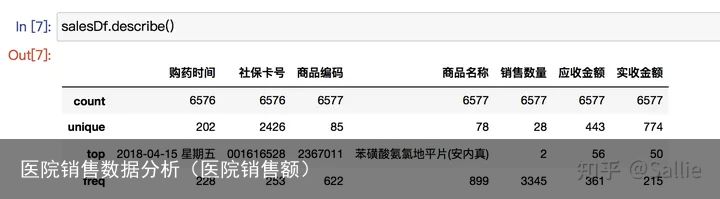 图4 数据集描述统计分析
图4 数据集描述统计分析3)清洗数据
列名重命名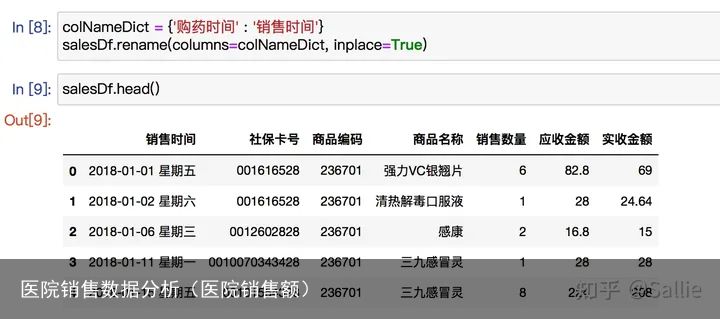 图5 列名重命名处理缺失值
图5 列名重命名处理缺失值 数据类型转换# 将字符串转为数值
salesDf[销售数量] = salesDf[销售数量].astype(float)
salesDf[应收金额] = salesDf[应收金额].astype(float)
salesDf[实收金额] = salesDf[实收金额].astype(float)
print(转换后的数据类型: \n, salesDf.dtype)
# 将销售时间拆分
def splitSaletime(timeColSer):
timeList[]
for value in timeColSer:
dateSer = value.split()[0]
timeList.append(dateStr)
timeStr = pd.Series(timeList)
return timeStr
timeSer = salesDf.loc[:, 销售时间]
dateSer=splitSaletime(timeSer)
salesDf.loc[:,销售时间]=dateSer.values
# 将字符串转换为日期
salesDf.loc[:, 销售时间] = pd.to_datetime(salesDf.loc[:, 销售时间], format = %Y-%m-%d, errors = coerce)
数据类型转换# 将字符串转为数值
salesDf[销售数量] = salesDf[销售数量].astype(float)
salesDf[应收金额] = salesDf[应收金额].astype(float)
salesDf[实收金额] = salesDf[实收金额].astype(float)
print(转换后的数据类型: \n, salesDf.dtype)
# 将销售时间拆分
def splitSaletime(timeColSer):
timeList[]
for value in timeColSer:
dateSer = value.split()[0]
timeList.append(dateStr)
timeStr = pd.Series(timeList)
return timeStr
timeSer = salesDf.loc[:, 销售时间]
dateSer=splitSaletime(timeSer)
salesDf.loc[:,销售时间]=dateSer.values
# 将字符串转换为日期
salesDf.loc[:, 销售时间] = pd.to_datetime(salesDf.loc[:, 销售时间], format = %Y-%m-%d, errors = coerce) 图6 将销售时间拆分数据排序# 根据销售时间对数据集进行排序
salesDf = salesDf.sort_values(by = 销售时间, ascending = True, na_position = first)
print(排序后的数据)
salesDf.head()
# 将行号重新排列
salesDf = salesDf.reset_index(drop = True)
salesDf.head()
图6 将销售时间拆分数据排序# 根据销售时间对数据集进行排序
salesDf = salesDf.sort_values(by = 销售时间, ascending = True, na_position = first)
print(排序后的数据)
salesDf.head()
# 将行号重新排列
salesDf = salesDf.reset_index(drop = True)
salesDf.head()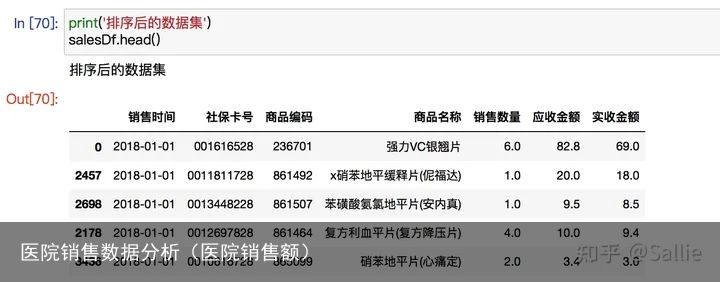 图7 排序后的数据集
图7 排序后的数据集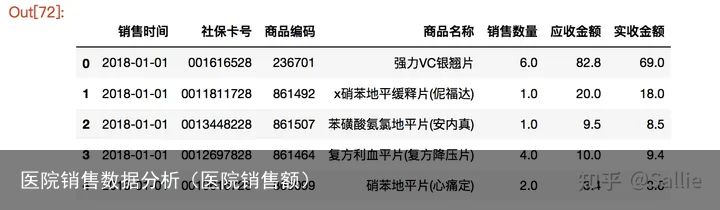 图8 行号重新排列处理异常值# 确认异常值情况
salesDf.describe()
# 利用查询条件删除异常值
querySer = salesDf.loc[:, 销售数量]>0
print(删除异常值前:,salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print(删除异常值后:,salesDf.shape)
图8 行号重新排列处理异常值# 确认异常值情况
salesDf.describe()
# 利用查询条件删除异常值
querySer = salesDf.loc[:, 销售数量]>0
print(删除异常值前:,salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print(删除异常值后:,salesDf.shape)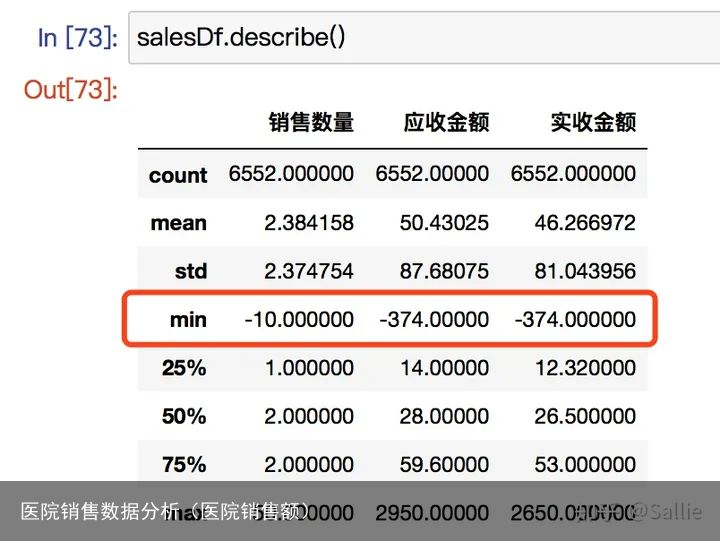 图9 利用描述统计分析确认异常值
图9 利用描述统计分析确认异常值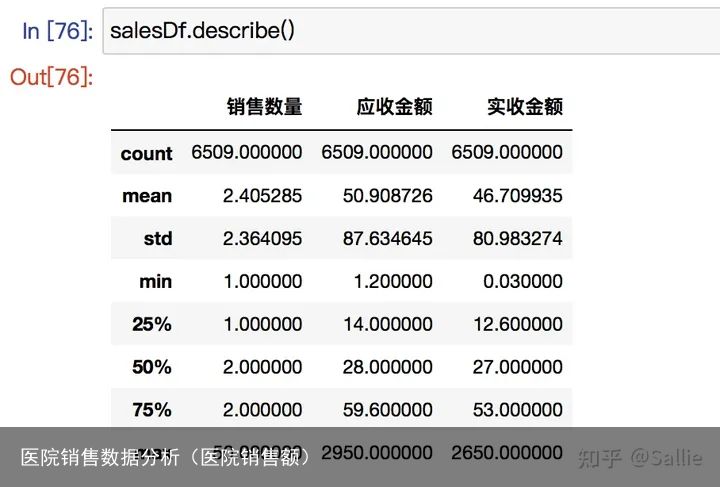 图10 删除异常值后的描述统计分析
图10 删除异常值后的描述统计分析4)数据分析
月均消费次数=总消费次数/月份数# 同一人同一天多次购买均记为一次,所以先根据销售时间、社保卡号进行去重 kpi1_Df = salesDf.drop_duplicates(subset = [销售时间, 社保卡号]) # 去重后的行数值即为总消费次数 totalT = kpi1_Df.shape[0] print(总消费次数, totalT) # 将新数据框排序并将行号重新排列 kpi1_Df=kpi1_Df.sort_values(by=销售时间, ascending=True) kpi1_Df=kpi1_Df.reset_index(drop=True) # 获取最小时间值 startTime=kpi1_Df.loc[0,销售时间] # 获取最大时间值 endTime=kpi1_Df.loc[totalT-1,销售时间] # 计算月份数 daysT=(endTime-startTime).days daysT=(endTime-startTime).days month_number = daysT//30 print(月份数, month_number) # 指标计算:月均消费次数 kpi1_T = totalT/month_number print(业务指标1:月均消费次数=, kpi1_T) 图11 总消费次数
图11 总消费次数 图12 月份数
图12 月份数 图13 月均消费次数月均消费金额=总消费金额/月份数# 总消费金额
totalS = salesDf.loc[:, 实收金额].sum()
# 指标计算:月均消费金额
kpi2_S = totalS/month_number
print(业务指标2:月均消费金额=,kpi2_S)
图13 月均消费次数月均消费金额=总消费金额/月份数# 总消费金额
totalS = salesDf.loc[:, 实收金额].sum()
# 指标计算:月均消费金额
kpi2_S = totalS/month_number
print(业务指标2:月均消费金额=,kpi2_S)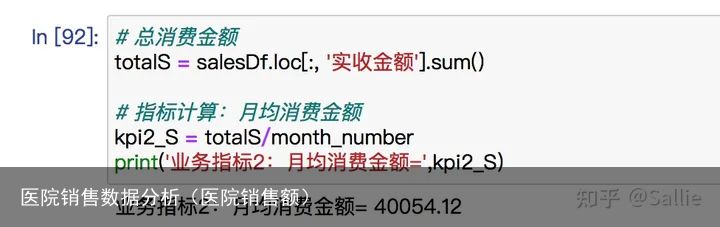 图14 月均消费金额客单价=总消费金额/总消费次数# 指标计算:客单价
kpi3 = totalS/totalT
print(业务指标3:客单价=,kpi3)
图14 月均消费金额客单价=总消费金额/总消费次数# 指标计算:客单价
kpi3 = totalS/totalT
print(业务指标3:客单价=,kpi3)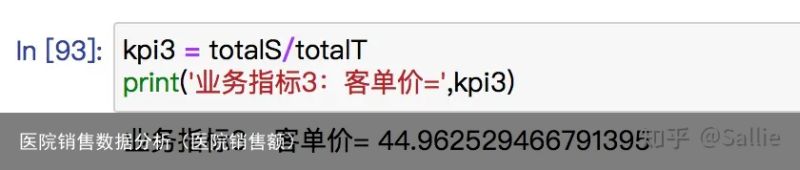 图15 客单价
图15 客单价
