







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
实战项目——医院销售数据分析(医院的销售利润率怎么算)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表本文利用pandas对医院销售数据进行分析,里面知识点繁多,未来可能还会经常复习。
一般的数据分析由如下的步骤组成:
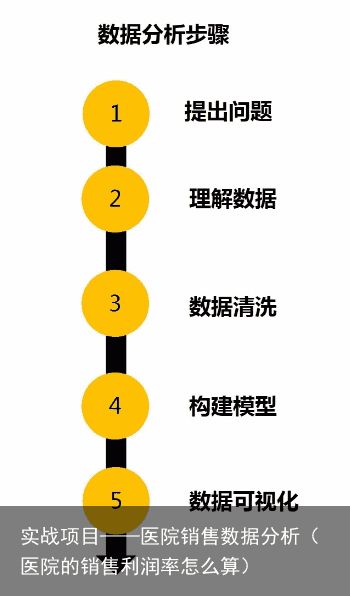
导入数据分析包:
import pandas as pd1.提出问题
从销售数据中分析出以下业务指标: 1)月均消费次数2)月均消费金额3)客单价4)消费趋势
2.理解数据
导入数据,dtype=‘object’按照字符串类型读取数据。
fileNameStr=J:\da\数据分析入门(Python)\第4关数据分析的基本过程\朝阳医院2018年销售数据.xlsx xls = pd.ExcelFile(fileNameStr,dtype=object) salesDf = xls.parse(Sheet1,dtype=object)查看数据前5行
salesDf.head()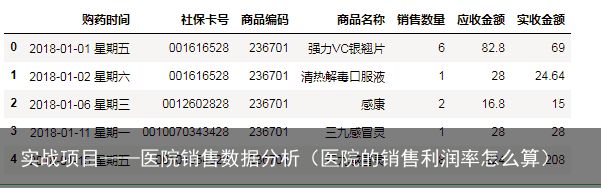
查看数据有多少行,多少列
salesDf.shape(6578, 7)
查看每一列数据类型
salesDf.dtypes购药时间 object
社保卡号 object
商品编码 object
商品名称 object
销售数量 object
应收金额 object
实收金额 object
dtype: object4.数据清洗
一个数据分析有大约60%的时间花在数据清洗过程。原始数据并不完全符合数据分析的需要,这时要对数据进行清洗,改成需要的样子。

a)选择子集,这里并不需要选择子集:
#注释掉 #subSalesDf=salesDf.loc[0:4,购药时间:销售数量]b)列名重命名:
colNameDict = {购药时间:销售时间} inplace=False,数据框本身不会变,而会创建一个改动后新的数据框, 默认的inplace是False inplace=True,数据框本身会改动 salesDf.rename(columns = colNameDict,inplace=True) salesDf.head()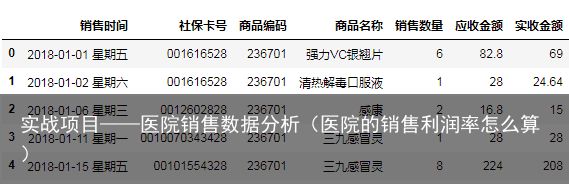
c)缺失数据处理:
#删除列(销售时间,社保卡号)中为空的行 #how=any 在给定的任何一列中有缺失值就删除 salesDf=salesDf.dropna(subset=[销售时间,社保卡号],how=any) print(删除缺失后大小,salesDf.shape)删除缺失后大小 (6575, 7)
d)数据类型转换:
把字符串转化为数值:
#字符串转换为数值(浮点型) salesDf[销售数量] = salesDf[销售数量].astype(float) salesDf[应收金额] = salesDf[应收金额].astype(float) salesDf[实收金额] = salesDf[实收金额].astype(float) print(转换后的数据类型:\n,salesDf.dtypes)
字符串转换为日期数据类型:
字符串分割:
testList=2018-06-03 星期五.split( )输出结果:
testList[2018-06-03, 星期五]
用函数将销售日期分割:
def splitSaletime(timeColSer): timeList=[] for value in timeColSer: #例如2018-01-01 星期五,分割后为:2018-01-01 dateStr=value.split( )[0] timeList.append(dateStr) #将列表转行为一维数据Series类型 timeSer=pd.Series(timeList) return timeSer #获取“销售时间”这一列 timeSer=salesDf.loc[:,销售时间] #对字符串进行分割,获取销售日期 dateSer=splitSaletime(timeSer)输出结果:
dateSer[0:3]0 2018-01-01
1 2018-01-02
2 2018-01-06
dtype: object导入数据中
salesDf.loc[:,销售时间]=dateSer salesDf.head() salesDf.dtypes
用to_datetime把销售时间转化为日期格式
salesDf.loc[:,销售时间]=pd.to_datetime(salesDf.loc[:,销售时间], format=%Y-%m-%d, errors=coerce) salesDf.dtypes
e)数据排序:
排序前:
salesDf.head()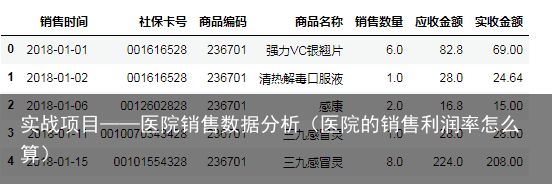 #按销售日期进行升序排列
salesDf=salesDf.sort_values(by=销售时间,
ascending=True)
print(排序后的数据集)
salesDf.head()
#按销售日期进行升序排列
salesDf=salesDf.sort_values(by=销售时间,
ascending=True)
print(排序后的数据集)
salesDf.head()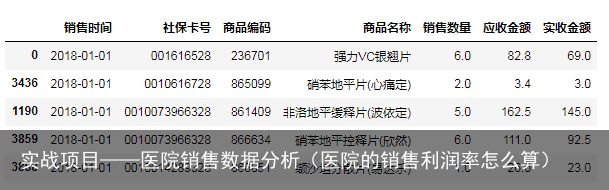
对行号重命名
salesDf=salesDf.reset_index(drop=True) salesDf.head()
f)异常值处理:
salesDf.describe()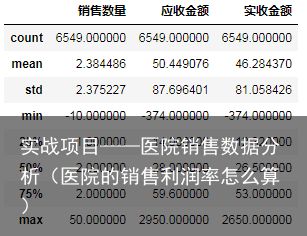 querySer=salesDf.loc[:,销售数量]>0
#应用查询条件
print(删除异常值前:,salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print(删除异常值后:,salesDf.shape)
querySer=salesDf.loc[:,销售数量]>0
#应用查询条件
print(删除异常值前:,salesDf.shape)
salesDf=salesDf.loc[querySer,:]
print(删除异常值后:,salesDf.shape)
5.构建模型
a)指标1:月均消费次数=总消费次数 / 月份数
总消费次数:同一天内,同一个人发生的所有消费算作一次;根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
kpi1_Df=salesDf.drop_duplicates( subset=[销售时间, 社保卡号] ) totalI=kpi1_Df.shape[0] print(总消费次数=,totalI)总消费次数= 5342
计算月份数
#第1步:按销售时间升序排序 kpi1_Df=kpi1_Df.sort_values(by=销售时间, ascending=True) #重命名行名(index) kpi1_Df=kpi1_Df.reset_index(drop=True) kpi1_Df.head() #最小时间值
startTime=kpi1_Df.loc[0,销售时间]
#最大时间值
endTime=kpi1_Df.loc[totalI-1,销售时间]
#第3步:计算月份数
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
print(月份数:,monthsI)
#最小时间值
startTime=kpi1_Df.loc[0,销售时间]
#最大时间值
endTime=kpi1_Df.loc[totalI-1,销售时间]
#第3步:计算月份数
#天数
daysI=(endTime-startTime).days
#月份数: 运算符“//”表示取整除
#返回商的整数部分,例如9//2 输出结果是4
monthsI=daysI//30
print(月份数:,monthsI)月份数: 6
kpi1_I=totalI // monthsI print(业务指标1:月均消费次数=,kpi1业务指标1:月均消费次数= 890
b)指标2:月均消费金额 = 总消费金额 / 月份数
totalMoneyF=salesDf.loc[:,实收金额].sum() #月均消费金额 monthMoneyF=totalMoneyF / monthsI print(业务指标2:月均消费金额=,monthMoneyF)业务指标2:月均消费金额= 50668.351666666305
c)指标3:客单价=总消费金额 / 总消费次数
pct=totalMoneyF / totalI print(客单价:,pct)客单价: 56.9094178210404
