







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
numpy/pandas医院销售数据分析(医院业务数据分析)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表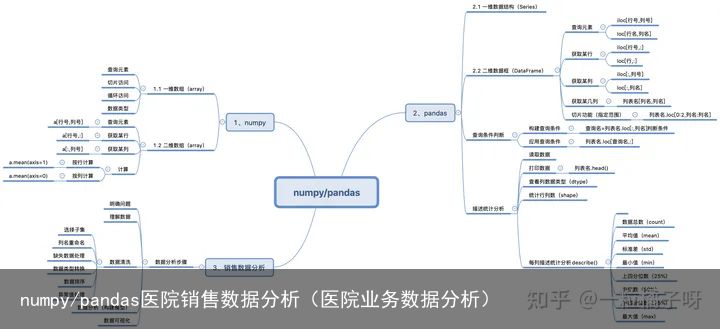
一、一维数据分析
numpy和pandas这两个包都有表示一维数据的数据结构。在numpy是array数组,pandas是series。pandas的series是建立在numpy基础上的。因此我们先来了解numpy的array,再了解pandas的series。
1. 一维数据分析numpy
1)numpy的一维数组其实和python的列表类似,定义好一维数组后,我们可以通过位置序号来获取元素。
导入模块 :import numpy as np 定义一维数组:a=np.array([2,3,4,5]) 查询元素:a[0] >>>2 切片访问:a[1:3] >>>array([3, 4]) 循环访问:for i in a: 类型查询:a.dtype >>>dtype(int32)NumPy一维数组与列表的区别
a)NumPy一维数组具有统计功能;
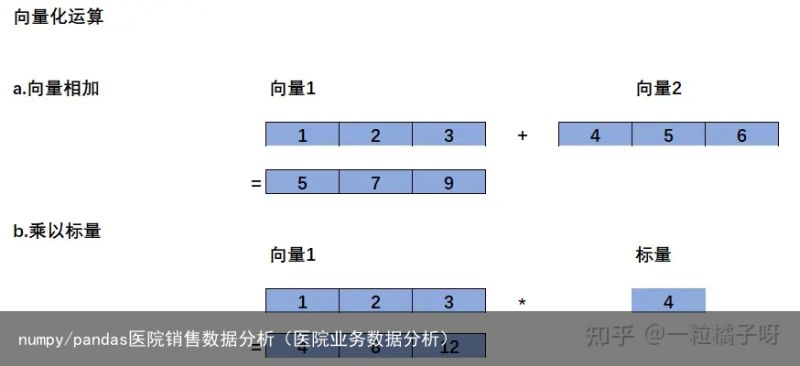
b)NumPy一维数组可以进行向量化计算;
c)NumPy一维数组中每个元素必须使用同一种数据类型,列表中的元素可以是不同的数据类型。
2.一维数据分析Pandas
现有以下数据,需要我们能通过iloc属性和loc属性在pandas中找到相应元素。
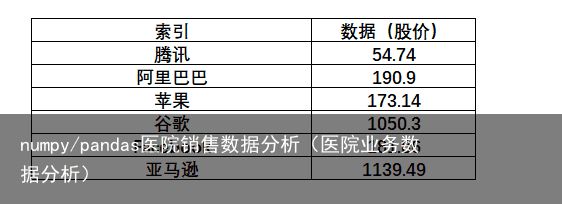
首先,先将数据存储到pandas的series中,然后再通过索引查找元素。
导入模块 :import pandas as pd 定义一维数组:s=pd.Series(data=[54.74,190.9,173.14,1050.3,181.86,1139.49], index=[腾讯,阿里巴巴,苹果,谷歌,Facebook,亚马逊]) 查询元素:s[0] >>>54.74 s[腾讯] >>>54.74 切片访问:s[1:3] >>> 阿里巴巴 190.90 苹果 173.14 dtype: float64 类型查询:s.dtype >>>dtype(float64)1)iloc属性:用于根据位置获取值,比如我们要查找stockS中的第一个元素54.74,那么可以通过输入它的位置‘0’:
2)loc属性:用于根据索引获取值,比如我们要查找stockS中的第一个元素54.74,那么可以通过第一个索引值‘腾讯’进行查找:
s.ioc[0] >>>54.74 s.loc[腾讯] >>>54.74在数据分析过程中,我们不希望结果中有空值的出现,所以就可以通过以下两种方法:一种是利用dropna()方法直接删除空值,另一种方法是利用add()方法对两个一维数组相加,并将参数传入fill_value,fill_value是指定缺失值用哪个值填充,在这里使用0来填充缺失值。
s1=pd.Series([1,2,3,4],index=[a,b,c,d]) s2=pd.Series([10,20,30,40],index=[a,b,e,f]) s3=s1+s2 s3 >>> a 11.0 b 22.0 c NaN d NaN e NaN f NaN dtype: float64 s3.dropna() #删除缺失值 >>> a 11.0 b 22.0 dtype: float64 s3=s1.add(s2,fill_value=0)#将缺失值进行填充 s3 >>> a 11.0 b 22.0 c 3.0 d 4.0 e 30.0 f 40.0 dtype: float64二、二维数据分析

二维数据结构有点类似excel表格中的二维表格,在numpy中通过Array创建二维表格,而pandas是通过DataFrame数据框来创建二维数组。
1. 二维数据分析numpy
1)numpy创建二维数组也是用Array,用大括号将数据括起,每一行都是一个列表代表一行,每一行都用一个逗号分隔开,代表每一行。
二维数组的行号和列号都是从0开始的。查询数组元素有三种情况:
a)查询元素:a[0,2]其中逗号前面是行号,逗号后面是列号。那么a[0,2]表示的就是查找第一行第三列的元素。
b)获取第一行元素:a[0,:]对应二维数组的第一行;
c)获取第一列元素:a[:,0],对应二维数组的第一列
定义二维数组:import numpy as np a=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]]) 查询元素:a[0,2] >>> 3 #返回第一行,第三列的数值 获取第一行:a[0,:] >>>array([1, 2, 3, 4]) 获取第一列:a[:,0] >>>array([1, 5, 9])2)numpy数轴参数:numpy的二维数组如果不指定数轴参数,就会计算所有数组的平均值、标准差,但有时候,我们需要考虑行和列,按行或者按列计算统计值。
a.mean(axis=1) >>>array([ 2.5, 6.5, 10.5]) #计算行平均值 a.mean(axis=0) >>>array([5., 6., 7., 8.]) #计算列平均值2. 二维数据分析pandas
1)numpy数组中的每个元素都属于同种类型,在数值计算、科学计算中很有用,但不利于表示像excel这样的内容,因为excel中每列的数据类型可能不一样,这时候就可以用pandas的DataFrame了。
2)pandas的二维数组相比于numpy的二维数组,pandas的二维数组有以下优点:
a)数据框每列可以是不同的数据类型,可以表示excel这样的内容。
b)有类似于pandas的series索引的功能,每一行都有一个索引值,每一列也都有一个索引值。
3)将以上excel的内容在pandas中展现出来:
import pandas as pd #定义一个字典 salesDict={购药时间:[2018-01-01 星期五,2018-01-02 星期六,2018-01-03 星期日], 社保卡号:[001616528,001616528,0012602828], 商品编号:[236701,236701,236701], 商品名称:[强力VC银翘片,清热解毒口服液,感康], 销售数量:[6,1,2], 应收金额:[82.8,28,16.8], 实收金额:[69,24.64,15]} #导入有序字典 from collections import OrderedDict #定义有序字典 salesOrderedDict=OrderedDict(salesDict) #定义数据框,参数传入字典 salesDf=pd.DataFrame(salesOrderedDict) salesDf >>>
4)计算平均值
salesDf.mean() >>> 社保卡号 5.388427e+24 商品编号 7.890041e+16 销售数量 3.000000e+00 应收金额 4.253333e+01 实收金额 3.621333e+01 dtype: float64 salesDf[应收金额].mean()>>>42.533333333333335)iloc属性根据位置查询值
salesDf.iloc[0,1] >>>001616528#获取第一行,第二列数据 salesDf.iloc[0,:] #获取第一行数据 >>> 购药时间 2018-01-01 星期五 社保卡号 001616528 商品编号 236701 商品名称 强力VC银翘片 销售数量 6 应收金额 82.8 实收金额 69 Name: 0, dtype: object salesDf.iloc[:,0] #获取第一列数据 >>> 0 2018-01-01 星期五 1 2018-01-02 星期六 2 2018-01-03 星期日 Name: 购药时间, dtype: object6)loc属性根据索引值查询值。
salesDf.loc[0,商品编号] >>>236701 #获取第一行,商品编号列数据 salesDf.loc[0,:] #获取第一行数据 salesDf.loc[:,商品名称] #获取商品名称列数据 >> 0 强力VC银翘片 1 清热解毒口服液 2 感康 Name: 商品名称, dtype: object3.数据查询
1)我们通过传入的列表来查询数据,也可以通过切片功能:指定范围来获取数据。
salesDf.loc[0:2,商品编号:销售数量] #和字符串切片不一样 >>> 商品编号 商品名称 销售数量 0 236701 强力VC银翘片 6 1 236701 清热解毒口服液 1 2 236701 感康 2 salesDf[[商品编号,销售数量]]#查询某几列 >>> 商品编号 销售数量 0 236701 6 1 236701 1 2 236701 22)通过条件判断筛选:
a)构建查询条件并应用
querySer=salesDf.loc[:,销售数量]>1 #构建查询条件 salesDf.loc[querySer,:] #应用查询条件 购药时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 星期五 001616528 236701 强力VC银翘片 6 82.8 69.0 2 2018-01-03 星期日 0012602828 236701 感康 2 16.8 15.03)在pandas中导入数据,读取数据及数据集的描述性统计分析。
#查看部分数据 tyfilename=E:\juzi\猴子数据分析学院\高级\第3关:Python数据分析\医院销售数据.xlsx salesDf=pd.read_excel(filename,sheet_name=Sheet1) salesDf.head() >>> 购药时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 星期五 1.616528e+06 236701.0 强力VC银翘片 6.0 82.8 69.00 1 2018-01-02 星期六 1.616528e+06 236701.0 清热解毒口服液 1.0 28.0 24.64 2 2018-01-06 星期三 1.260283e+07 236701.0 感康 2.0 16.8 15.00 3 2018-01-11 星期一 1.007034e+10 236701.0 三九感冒灵 1.0 28.0 28.00 4 2018-01-15 星期五 1.015543e+08 236701.0 三九感冒灵 8.0 224.0 208.00 #查看列的数据类型 salesDf.loc[:,销售数量].dtype >>>>dtype(float64) #查看总行、总列 salesDf.shape >>>(6578, 7) # 数据共有6578行,7列 #对每一列进行描述统计分析 salesDf.describe() >>> 社保卡号 商品编号 销售数量 应收金额 实收金额 count 6.576000e+03 6.577000e+03 6577.000000 6577.000000 6577.000000 mean 6.091254e+09 1.015869e+06 2.386194 50.473803 46.317510 std 4.889284e+09 5.131153e+05 2.375202 87.595925 80.976702 min 1.616528e+06 2.367010e+05 -10.000000 -374.000000 -374.000000 25% 1.014234e+08 8.614560e+05 1.000000 14.000000 12.320000 50% 1.001650e+10 8.615070e+05 2.000000 28.000000 26.600000 75% 1.004882e+10 8.690690e+05 2.000000 59.600000 53.000000 max 1.283612e+10 2.367012e+06 50.000000 2950.000000 2650.000000三、医院销售数据分析
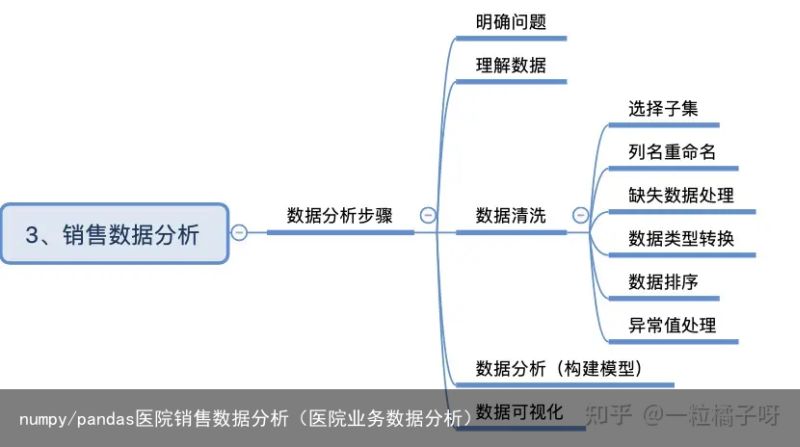
1.明确问题
数据分析的目标是为了解决实际生活中遇到的问题,因此数据分析的第一步就是明确问题,只有明确了问题,才能围绕问题展开分析。通过沟通,我们知道需要解决的问题是:如何得到月均消费次数、月均消费金额、客单价等指标以及消费趋势。
2.理解数据
在真正解决问题前,我们需要先看一下数据集的基本信息,从整体上理解数据。
先使用pandas的read_excel将数据读取到数据框中,在读取数据的过程我们加入了dtype=str的参数,这样做的目的是为了按照字符串类型统一读取数据,使得数据在读取过程中被正确读取。然后为了检查数据是否正常导入,查看前三行数据以及、总行、总列还有所有列的数据类型:
filename=E:\juzi\猴子数据分析学院\高级\第3关:Python数据分析\医院销售数据.xlsx salesDf=pd.read_excel(filename,sheet_name=Sheet1,dtype=str) salesDf.head(3) #查看前3行数据 salesDf.shape #查看总行、总列 salesDf.dtypes #查看所有列的数据类型 >>> 购药时间 object 社保卡号 float64 商品编号 float64 商品名称 object 销售数量 float64 应收金额 float64 实收金额 float64 dtype: object3.数据清洗
1)选择子集
本案例不需要选择子集,但是为了以后需要时,能参考,因此这里就给出了一个代码作为示范:
snew=salesDf.loc[0:2,商品编号:销售数量] #本例不需要,仅演示 snew #本例不需要,仅演示2)列名重命名
默认的inplace是False,inplace = False,表明数据框本身不会变,而会创建一个改动后新的数据框;inplace = True,说明数据框本身会改动。这里我们需要将原始数据集中的“购药时间”改为我们常用的指标“销售时间”:
salesDf.rename(columns={购药时间:销售时间},inplace=True) #inplace=True 数据框本身会改变,而inplace=False 会创建一个改动后新的数据框。 salesDf.head(3) >>> 销售时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 星期五 1616528.0 236701.0 强力VC银翘片 6.0 82.8 69.00 1 2018-01-02 星期六 1616528.0 236701.0 清热解毒口服液 1.0 28.0 24.64 2 2018-01-06 星期三 12602828.0 236701.0 感康 2.0 16.8 15.003)缺失值处理
原始数据经常因为记录缺失失误导致缺失值的存在,这时候可以采用两种方法处理:
一种是直接删除缺失数据,第二种是若缺失值太多,可以建立模型进行插值的办法补全缺失值。
salesDf.shape >>>(6578, 7) salesDf=salesDf.dropna(subset=[销售时间,社保卡号],how=any) #删除两列中有缺失值的行;salesDf.dropna()删除所有有空值的所有行;salesDf.dropna(axis=1)删除所有有空值的列 salesDf.shape >>>(6575, 7)4)数据类型转换
a)因为我们开始导入数据时,将所有列都导成字符串类型,但销售数量、应收金额和实收金额这三列应该是数字类型。所以用astype将数据类型进行转换。而销售时间是日期+空格+星期的组合方式,实际我们只需要日期这可以了。
#字符串转换为字符 salesDf[销售数量]=salesDf[销售数量].astype(float) salesDf[应收金额]=salesDf[应收金额].astype(float) salesDf[实收金额]=salesDf[实收金额].astype(float) salesDf.dtypes >>> 销售时间 object 社保卡号 float64 商品编号 float64 商品名称 object 销售数量 float64 应收金额 float64 实收金额 float64 dtype: object 字符串分割 testList=2018-06-03 星期五.split( )[0] >>>2018-06-03 #分隔符为空格 整列字符串分割 def splitSaletime(timeColSer): timeList=[] for value in timeColSer: dateStr=value.split( )[0] timeList.append(dateStr) timeSer=pd.Series(timeList) return timeSer timeSer=salesDf[销售时间] timeSer[0:3] dateSer=splitSaletime(timeSer) salesDf[销售时间]=dateSer.values salesDf.head(3) >>> 销售时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 1616528.0 236701.0 强力VC银翘片 6.0 82.8 69.00 1 2018-01-02 1616528.0 236701.0 清热解毒口服液 1.0 28.0 24.64 2 2018-01-06 12602828.0 236701.0 感康 2.0 16.8 15.00b)需要将销售时间的类型从字符串转换成日期:
字符串转换日期 salesDf[销售时间]=pd.to_datetime(salesDf[销售时间],format=%Y-%m-%d,errors=coerce) salesDf.dtypes >>> 销售时间 datetime64[ns] 社保卡号 float64 商品编号 float64 商品名称 object 销售数量 float64 应收金额 float64 实收金额 float64 dtype: object5)数据排序
by:按哪几列排序
ascending = True 表示升序排列
ascending = False 表示降序排列
将销售时间按升序进行排列:
salesDf=salesDf.sort_values(by=销售时间,ascending=True) #ascending=True表示升序 #ascending=False表示降序 >>> 销售时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 1616528.0 236701.0 强力VC银翘片 6.0 82.8 69.0 893 2018-01-01 11743428.0 861405.0 苯磺酸氨氯地平片(络活喜) 1.0 34.5 31.0 2177 2018-01-01 103283128.0 861464.0 复方利血平片(复方降压片) 1.0 2.5 2.2对销售时间进行升序排序后,行号就不是从0,1,2开始升序排列了,这时候还需要对行号重命名。
行名重命名 salesDf=salesDf.reset_index(drop=True) >>> 销售时间 社保卡号 商品编号 商品名称 销售数量 应收金额 实收金额 0 2018-01-01 1616528.0 236701.0 强力VC银翘片 6.0 82.8 69.0 1 2018-01-01 11743428.0 861405.0 苯磺酸氨氯地平片(络活喜) 1.0 34.5 31.0 2 2018-01-01 103283128.0 861464.0 复方利血平片(复方降压片) 1.0 2.5 2.26)异常值处理
通过描述性统计分析结果,我们从整体知道数据集。从这里我们看到:销售数量、应收金额和实收金额的最小值都为负数,这都是因为销售数据小于0造成的。通过常识我们知道销售数量应该是大于0的,这可能是销售过程中记录错误导致的异常值。
querySer=salesDf[销售数量]>0 salesDf.shape >>>(6575, 7) salesDf=salesDf.loc[querySer,:] salesDf.shape >>>(6532, 7)7)查找重复值
查找重复值sd=salesDf[salesDf.duplicated()] sd >>> 发现无重复值 如果有重复值 salesDf=salesDf.drop_duplicates()4.数据分析或构建模型
指标1:月均消费次数=总消费次数/月份数
kpil_Df=salesDf.drop_duplicates(subset=[销售时间,社保卡号]) totalI=kpil_Df.shape[0] print(总消费次数=,totalI) >>> 总消费次数= 5363 max_time=salesDf[销售时间].max() min_time=salesDf[销售时间].min() dayI=(max_time-min_time).days mouthsI=dayI//30 mouthsI >>> 6 kpil_I=round(totalI/mouthsI,2) #或者kpil_I=%.2f % (totalI/mouthsI)或者kpil_I=format(float(totalI)/float(mouthsI),.2f) print(业务指标1:月均消费次数,kpil_I) >>> 业务指标1:月均消费次数 893.83指标2:月均消费金额=总消费金额/月份数
totalMoneyF=salesDf[实收金额].sum() print(业务指标2:月均消费金额,(%.2f%(totalMoneyF/mouthsI))) >>> 业务指标2:月均消费金额 50909.69指标3:客单价=总消费金额/总消费次数
print(业务指标3:客单价+str(format (totalMoneyF/totalI,.2f))) >>> 业务指标3:客单价56.96