







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
如何执行探索性数据分析?
 2023-03-21
2023-03-21 浏览次数:次
浏览次数:次 返回列表
返回列表探索性数据分析(EDA)是了解数据集的关键步骤。在EDA中可以执行各种步骤,下文中会我会介绍 4 个主要步骤。其中数据集来自帕尔默群岛企鹅数据。

一、仔细检查数据
这一步的目的是找出数据集的变量和范围。它回答诸如"此数据集是否足够大?"或“它包含多少个特征或行?"等问题。加载数据集后,使用 head() 函数检查前五行将是了解数据集结构的良好开端,具体操作如下所示。
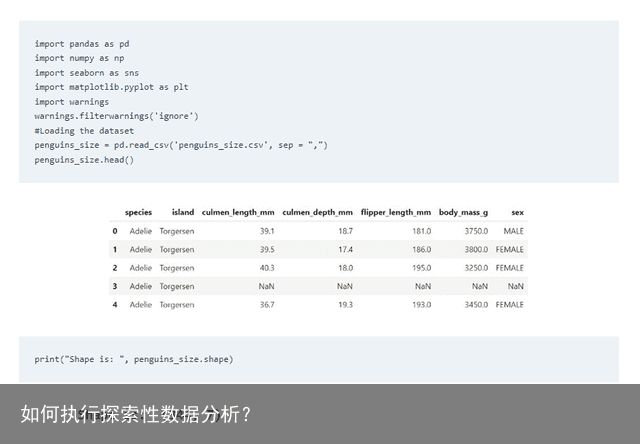
从这里得出数据集的范围为(344,7),这意味着存在7个特征和344行,这表示数据集不够大。为了可视化特征的数据类型,可以使用 info() 函数,如下所示。结果显示,物种、岛屿和性别是目标,其余特征是浮动变量。使用 dtypes 也是了解列的数据类型的一种替代方法。

二、数据清理
查找缺失值、删除重复项等是探索性数据分析的关键步骤。这些值可能会导致我们的模型最终得出错误的结论。仅调查 isnull()是不够的。例如,在包含心率特征的数据集中,该特征的值不能为 0。在这种情况下,0 也是一个缺失值,需要处理。
有多种方法可以处理数据的缺失值,例如删除包含缺失值的行(如果数据集足够大并且缺失值的数量不是太多,这是一个选项),插补方法(特征的平均值/中位数)等。
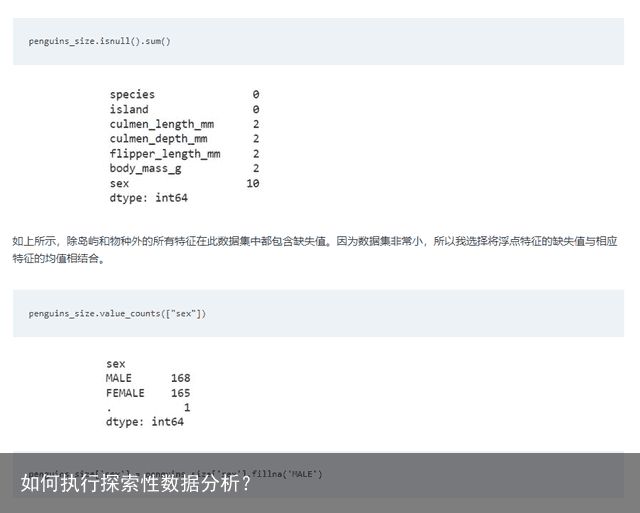
对于企鹅的性别,在检查了雌性和雄性值的计数后,将考虑最常见的值,在这种情况下,缺失值将用 "MALE" 进行估算。如上所示,另一个值为".",必须将其归因或丢弃。在所有缺失值被插补或删除后,我们再次使用 isna () 函数进行检查,确定没有遗漏值。
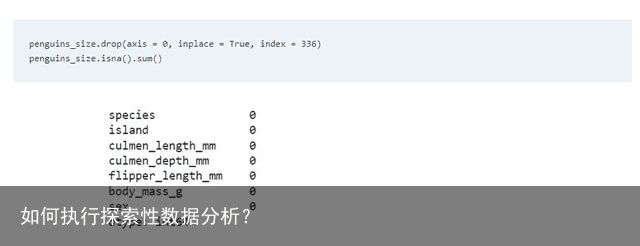
最后,对于这个部分,需要检查是否存在任何重复行。

三、统计洞察
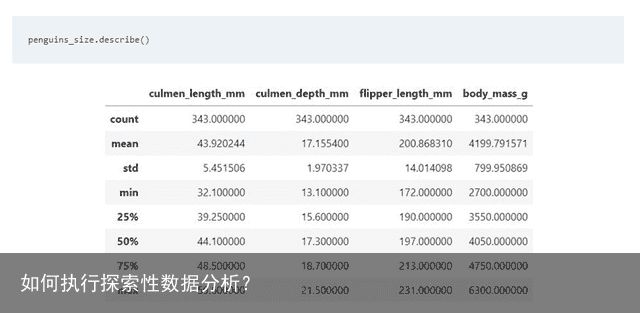
这也是理解数据的一部分。处理缺失值后,可以使用 describe() 函数来获取数据的平均值、最大值、最小值和标准偏差等信息。此方法还可用于检测缺失值,例如,如果特征值的最小值在不应为 0 的地方为 0,则 describe()函数有助于处理缺失值。
通过使用 value_counts() 函数,可以计算对象的唯一值。此外,每个物种的体重平均值可以通过使用 groupby()函数找到。 对于连续特征,此函数在分类和观察数据方面非常有用。

四、数据可视化
为了更好地可视化数据集,可以使用各种绘图技术,在下文中简单介绍几个。有些图在可视化分类数据方面效果更好,有些图则更适合数值数据的可视化。
箱形图
通过显示数据分布来检查异常值或理解分类特征与连续特征之间关系的好方法。
如下图所示,由于没有数据点分别高于或低于最大值和最小值,因此未检测到异常值。此外,可以很容易地找到数据点的中位数,因为通过框内的水平线代表的就是中位数。

直方图
直方图用于描述频率分布。

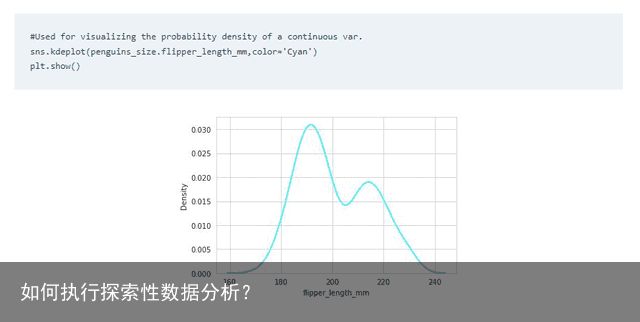
此外,kdeplot 是可视化数据分布的另一种方法。此图实际上类似于直方图,但不是将值放入条柱中,而是绘制一条曲线。
条形图
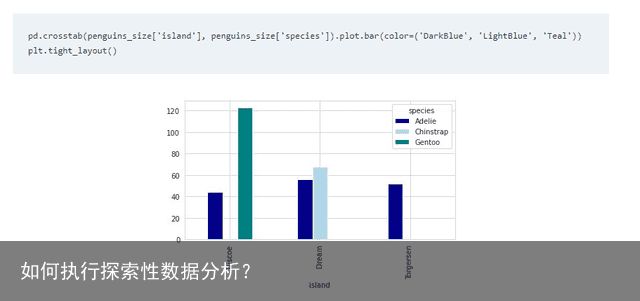
在条形图中,x 轴表示分类变量, y 轴表示数值变量。这就是为什么条形图描绘了这两个变量之间的关系。

通过使用 pandas 函数交叉表,可以分析两个或多个变量之间的关系。作为说明,下面的条形图强调了生活在特定岛屿中的特定物种的企鹅数量之间的关系。
小提琴图
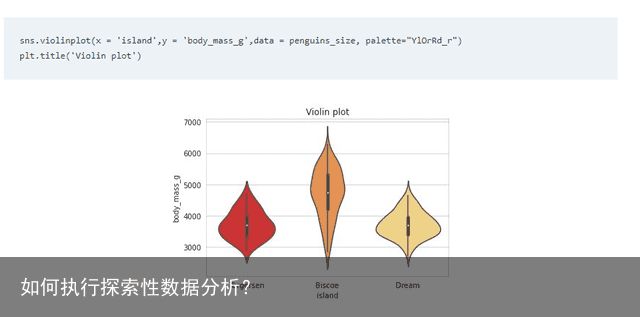
小提琴图描述的是数据集的概率密度。由于两个不同的类别可能具有相同的平均值,在这种情况下观察小提琴图会更有用。
在下面的小提琴图中,梦幻岛企鹅体重的平均值在3000到4000克之间,而在比斯科岛企鹅体重的平均值大约在4500到5500克之间。
想要完整代码的同学可以留言获取哦~
 举报/反馈
举报/反馈
