







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
构建数据科学工作流
 2023-03-21
2023-03-21 浏览次数:次
浏览次数:次 返回列表
返回列表1.入门
从外部看,数据科学似乎是一门庞大而模糊的学科。今天的数据科学专家并不是为了获得数据科学学位而上大学的(尽管现在许多大学都提供这些课程)。
第一代专业数据科学家来自数学、统计学、计算机科学和物理学科。
数据科学的“科学”部分是提出问题、生成假设、检验,以及形成解释证据的模型的工作。
这些技能是任何人都可以学习的,而且现在比以往任何时候都有更多的资源可以开始学习。
最好的资源之一是Kaggle。他们的数据科学竞赛对任何人来说都是一个机会,让他们能够去练习项目。围绕这些挑战形成的社区也是向他人学习的好地方。
案例研究
在本文中,我将使用经典挑战“泰坦尼克号”来解释如何处理数据科学问题并找到一个成功的解决方案:https://www.kaggle.com/c/titanic/overview 。
这项挑战的目的是建立一个模型,根据乘客名单中已知的乘客信息,预测乘客的存活率。这是基于历史数据,我们知道很多乘客的姓名、年龄、性别、船舱等级和家庭信息,以及他们是否在灾难中幸存下来。
Kaggle提供训练数据和测试数据。训练数据有生存的“真实”标签(是/否),但测试数据不包括基本真实标签。Kaggle保留这些标签,并使用它们为你的提交打分。测试数据预测取决于你的预测,预测的准确性将用于确定你在排行榜上的位置。

如何在泰坦尼克号挑战赛中获得满分
关于泰坦尼克号挑战赛的旁注:如果你看看排行榜,你会看到很多完美的分数。这自然会让你怀疑,“他们是怎么做到的?”。
答案令人沮丧——他们作弊了。如果你在网上搜索一段时间,你会发现可以在互联网上找到带有基本事实标签的完整测试数据。那些有完美分数的人只需提交真实的标签,而不是机器学习模型的预测……然后得到一个完美的分数。
但他们没有通过真正的挑战——挑战存在于掌握一门技术,而不是偷取高分。
工作环境
在开始数据科学项目之前,我建议设置你的工作环境,以便:
新建项目文件夹,其中包含用于存储数据的子文件夹;独立的虚拟环境,安装了标准的数据科学库。对于虚拟环境,我建议使用conda来管理Python环境。我最喜欢的数据科学库是numpy、pandas、matplotlib、seaborn和scikit-learn。根据问题的性质,其他库(如scipy)可能是相关的。深度学习的挑战包括安装Tensorflow或PyTorch。
最后我们加载数据。假设你已经将挑战的数据从Kaggle下载到你自己的机器上,并将其放入名为data的子文件夹中,并且你正在Jupyter Notebook中编写代码。
或者,你可以直接在Kaggle平台上创建一个数据科学Notebook。
importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdpd.set_option(display.max_rows,200)importseabornassns#应用默认主题sns.set()#假设你已经将数据下载到自己的机器上#它位于名为“data”的子文件夹中train_data=pd.read_csv(./data/train.csv)test_data=pd.read_csv(./data/test.csv)
2.探索性数据分析
不要跳过这第一步。
无论何时使用新数据,了解数据包含的内容、变量的含义、使用的单位和数据类型以及分布的外观都很重要。
这将有助于你对数据建立直觉,使其更容易产生假设,这也有望使解决方案更容易找到。
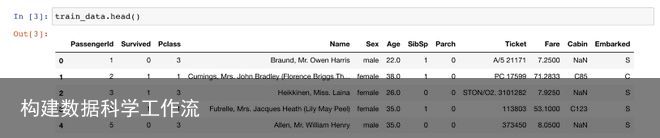
训练数据的前几行如下所示。“Survived”列表示生存,它是我们试图预测的目标变量。
challenge网站很好地解释了数据,并用表格解释了每个变量:

其中大多数都是不言而喻的,但是sibsp和parch需要更多的信息:
sibsp:数据集以这种方式定义家庭关系…
Sibling=兄弟姐妹
Spouse=丈夫、妻子
parch:数据集以这种方式定义家庭关系…
Parent=母亲,父亲
Child=女儿,儿子,继女,继子
有些孩子只和保姆一起旅行,因此对他们来说parch=0。
按年龄或性别分列的存活率
seaborn库擅长可视化,因此在本节中,我将以几种不同的方式检查数据。
我很想知道我们关于妇女和儿童存活率的假设是否成立,所以我设计了以下的图。
importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdimportseabornassns#应用默认主题sns.set()#加载训练数据train_data=pd.read_csv(./data/train.csv)sns.catplot(data=train_data,kind="swarm",x="Sex",y="Age",hue="Survived")
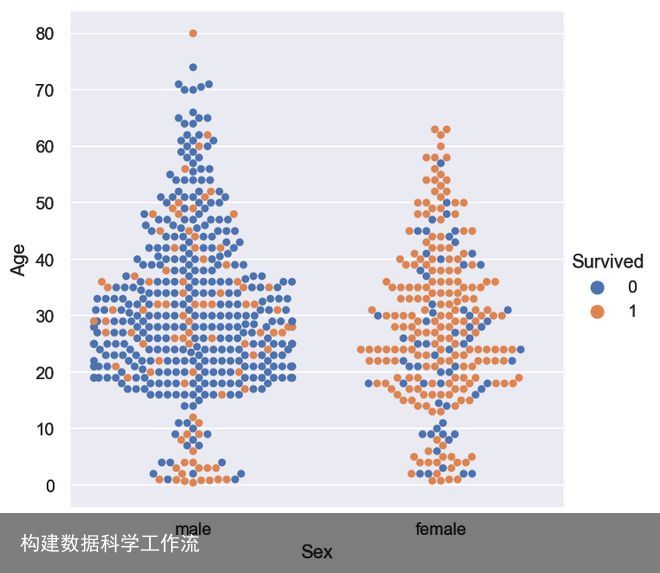
用seaborn创建的图显示了基于性别和年龄的乘客存活率。
我们的假设成立得相当好,但值得注意的是,相当多的儿童没有存活下来,相当多不同年龄的男性确实存活了下来。他们的生存可能与其他什么有关吗?
船舱等级
也许船舱等级是生存的预测。让我们再看一次数据,但这次是按船舱等级划分的。
importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdimportseabornassns#应用默认主题sns.set()#加载训练数据train_data=pd.read_csv(./data/train.csv)sns.catplot(data=train_data,kind="swarm",x="Sex",y="Age",col="Pclass",hue="Survived")
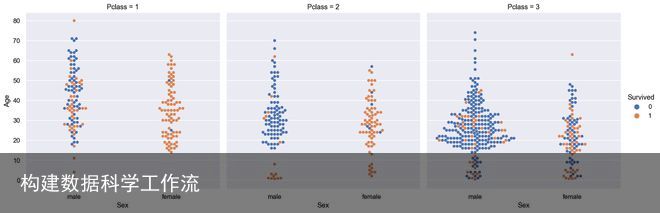
图中显示了基于年龄、性别和乘客对应船舱等级(1、2、3)的乘客存活率。
我们在这里看到了一些内容。在幸存的成年男性中,一等舱乘客存活率较高;在二等舱和三等舱乘客中也有成年男性生还者,但相对于每组乘客总人数而言没有一等舱那么多。
在没有幸存下来的女性中,大多数是三等舱乘客。
这告诉我们,性别、年龄和船舱等级都可能是生存率的预测因素,但在每一组中都有异常值。目前还不清楚这是随机的,还是由于更微妙的因素。
登船
最后,让我们快速看看这些乘客在哪里登船。
importnumpyasnpimportmatplotlib.pyplotaspltimportpandasaspdimportseabornassns#应用默认主题sns.set()#加载训练数据train_data=pd.read_csv(./data/train.csv)sns.catplot(data=train_data,kind="count",x="Survived",col="Embarked")
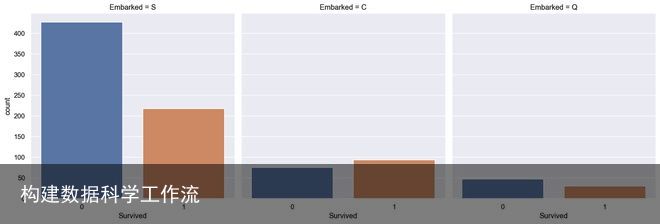
字母S、C和Q代表南安普顿、瑟堡和皇后镇。大多数乘客在南安普顿上船。在瑟堡上船的乘客从他们的同龄人中看来生存的机会稍好一些,但港口和生存之间似乎没有很强的相关性。
有了这些见解,我们已经开始形成关于数据的假设,我们将在稍后进行测试。如果没有可视化的数据,我们就不会有同样的直觉。
3.清理数据
即使在最好的情况下,数据也很少是“干净的”,这意味着数据中可能存在缺失值或错误。其他时候,数据将以需要转换、过滤或其他方式处理的单位记录,然后才能进行任何进一步的工作。
数据清理没有单一的方法。这取决于你的数据:
图像可能需要重新缩放、旋转、颜色校正、平滑、锐化;音频可能需要过滤、重新录制、去噪或标准化;自然语言数据(文本)可能需要更正大小写,删除停用词,并删除标点符号。如果我们仔细研究泰坦尼克号的数据,会发现一些问题:
X=train_datay=train_data[Survived]X.drop(columns=[Survived],inplace=True)forcolinX.columns:ifX[col].isna().any():print(Column"{}"ismissingdata..format(col))
此代码生成输出:
Column"Age"ismissingdata.Column"Cabin"ismissingdata.Column"Embarked"ismissingdata.
处理NAN
这里我使用pandas来用.isna()方法检查空值。缺少数据或空值将生成“NA”。如果需要数字数据,它会产生一个“NaN”,意思是“不是一个数字”。
泰坦尼克号的数据中有很多缺失的值。有时我们不知道一个人的年龄,或者他们住的是哪个舱室(如果有的话),或者他们的出发港是什么。
这给我们留下了几个选择:
删除所有缺少值的行找到合理的数值来填补每种方法都有其优点。在第一种情况下,我们对数据不做任何假设,只选择删除表中任何不完整的行。这样做的好处是,我们不会用我们的假设来偏袒未来的模型,而是以减少训练示例为代价。

在训练机器学习模型时,数据越多越好。如果你有很多干净的数据,扔掉任何不完整的样本可能是好的。但是如果表中的每一行都是宝贵的,那么最好找到值来填补。
泰坦尼克号的数据集不是很大。我们的训练设备里只有不到1000名乘客。我们可能需要进一步细分训练数据来验证模型,这样我们的训练例子就更少了。
重新映射类别数据
机器学习模型需要数值数据,但很多泰坦尼克号的数据是离散数据。我们需要把这些数据转换成数字。
“Sex”列只有两个值,女性和男性。我们可以把它们重新映射到0和1。
train_data.Sex=train_data.Sex.map({‘female’:0,‘male’:1})
下面将使用一种称为“one-hot”的技术来处理具有两种以上可能性的分类数据,例如出发港(有3个可能的值)。
填补缺失值
通过一些合理的假设,我们实际上可以很好地填补数据。
年龄
我们可以在这里使用几种策略,例如简单地用所有乘客的平均年龄填充缺失值。
但我们可以做得更好。
我的策略是观察每一个船舱等级的人的平均年龄。
forpclass,grpinX.groupby(Pclass):print(Class:,pclass,--MedianAge:,grp.Age.median())
结果是:
Class:1--MedianAge:37.0Class:2--MedianAge:29.0Class:3--MedianAge:24.0
当你进入二等舱和三等舱时,我发现头等舱的乘客往往年龄偏大,而且年龄有下降的趋势,对此我并不感到惊讶。
对于所有缺失的年龄值,我根据船舱等级给他们分配了中值。
defimpute_age(row):ifrow[Pclass]==1:age=37.0elifrow[Pclass]==2:age=29.0elifrow[Pclass]==3:age=24.0returnagemissing_ages=X.Age.isna()X.loc[missing_ages,Age]=X[missing_ages].apply(lambdarow:impute_age(row),axis=1)
你可以通过观察男女的平均年龄,然后根据这两个变量填写缺失的数据,从而进一步改进这项技术。
登船港
这里没有多少缺失的值。最常见的登船港是南汉普顿,所以在其他条件相同的情况下,乘客很可能在那里登船。所有级别的乘客都是这样。
missing_embarked=X.Embarked.isna()X.loc[missing_embarked,Embarked]=S
从船舱到甲板
我们表中的许多行都包含一个舱位号。最初还不清楚如何利用这些信息,但我们可以根据船舱号来确定甲板。例如,“C22”在甲板C上。
客舱大多在B到F甲板上。关于船舶布局的一些信息可以在这里找到。同一页还显示了一等舱、二等舱和三等舱的位置。
对于已知舱位号的乘客,我用它来推断甲板。
对于没有舱位号的乘客,我用他们的船舱等级来推断他们最有可能占用的舱位。
我在我的数据框中创建了一个名为“Deck”的新列,并在其中写入所有推断的Deck信息。“客舱(Cabin)”栏现在可以删除了。
definfer_deck(row):iftype(row[Cabin])==str:deck=str(row[Cabin])[0]else:deck=UnknownreturndeckX[Deck]=X.apply(lambdarow:infer_deck(row),axis=1)forpc,grpinX.groupby(Pclass):print(\nClass:,pc)print(grp[Deck].value_counts())#对于每个类,根据从中推断出的甲板布局来计算缺失的甲板#https://www.dummies.com/education/history/titanic-facts-the-layout-of-the-ship/#Pclass1:C#Pclass2:E#Pcasss3:Fdefinfer_deck_v2(row):ifrow[Pclass]==1:deck=Celifrow[Pclass]==2:deck=Eelse:deck=Freturndeckunknown_decks=X[Deck]==UnknownX.loc[unknown_decks,Deck]=X[unknown_decks].apply(lambdarow:infer_deck_v2(row),axis=1)X.drop([Cabin],axis=1,inplace=True)
输出为:
Class:1C59B47Unknown40D29E25A15T1Name:Deck,dtype:int64Class:2Unknown168F8D4E4Name:Deck,dtype:int64Class:3Unknown479F5G4E3Name:Deck,dtype:int64
我在这里的策略是查看甲板布局,看看大部分一等舱、二等舱和三等舱的位置。它似乎分别是C、E和F甲板,尽管我可能错了。
对于所有未知舱位的乘客,我根据乘客船舱等级将他们分配到一个舱位。

解释车票号码
我花了大量时间研究可以从罚单列中的值中收集到哪些信息。
你会注意到有些票有一个前缀,比如“S.C./PARIS”,后面跟着一个数字。前缀和数字都能告诉我们一些东西。我猜前缀是指售票员。从车票号码本身我们有时可以推断出一群人一起旅行。
我对前缀数据做了一系列深入的清理和消除歧义,但最后,我还是放弃了它,因为它似乎没有带来任何结果。
在Kaggle论坛上有一个关于这个话题的很好的讨论: https://www.kaggle.com/c/titanic/discussion/11127 。
4.假设检验
既然我们已经清理了数据,我们可以尝试一些简单的测试。我们可以分离出测试集。对于这个分离出来的测试数据,我们知道基本的真实标签,所以可以测量我们预测的准确性。
fromsklearn.preprocessingimportStandardScalerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.linear_modelimportLogisticRegressionfromsklearn.metricsimportaccuracy_scoreXX=X[[Age,Sex]]std_scaler=StandardScaler()XX=std_scaler.fit_transform(XX)X_train,X_test,y_train,y_test=train_test_split(XX,y,test_size=0.25,random_state=42)
年龄和性别
我们知道泰坦尼克号的幸存者乘救生艇逃离,而这些救生艇(我们假设)将优先装满妇女和儿童。我们能从这两个变量中准确预测生存率吗?
我们将使用logistic回归进行测试:
clf=LogisticRegression()clf.fit(X_train,y_train)y_pred=clf.predict(X_test)print(accuracy_score(y_pred,y_test))
准确度:
78%的准确率相当不错!显然,这两个变量是高度重要的,正如预期的那样。
船舱等级
接下来,我们可以假设头等舱的乘客,因为他们的身份或者他们的舱室靠近上层甲板,可能更可能是幸存者,所以让我们来看看是否只有舱位是一个很好的预测因素。然后我们再看看结合年龄和性别是否能改善之前的结果。
clf=LogisticRegression()#需要将Pclass拆分为3个单独的二元列X=pd.concat([X,pd.get_dummies(X[Pclass],prefix=Pclass)],axis=1)X.drop([Pclass],axis=1,inplace=True)#只保留该些列XX=X[[Pclass_1,Pclass_2,Pclass_3]]std_scaler=StandardScaler()XX=std_scaler.fit_transform(XX)X_train,X_test,y_train,y_test=train_test_split(XX,y,test_size=0.25,random_state=42)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)print(UsingPclassasthesolepredictor,ouraccuracy:)print(accuracy_score(y_pred,y_test))XX=X[[Age,Sex,Pclass_1,Pclass_2,Pclass_3]]std_scaler=StandardScaler()XX=std_scaler.fit_transform(XX)X_train,X_test,y_train,y_test=train_test_split(XX,y,test_size=0.25,random_state=42)clf.fit(X_train,y_train)y_pred=clf.predict(X_test)print(\nUsingPclass,age,andsexaspredictors,ouraccuracy:)print(accuracy_score(y_pred,y_test))
我不得不对Pclass变量进行one-hot编码。我解释一下下面的one-hot编码是什么,为什么它很重要。从这些测试中,我得到的结果是:
UsingPclassasthesolepredictor,ouraccuracy:0.6995515695067265UsingPclass,age,andsexaspredictors,ouraccuracy:0.7937219730941704
因此,使用船舱等级作为唯一的预测因子,我们的logistic分类器的准确率接近70%。结合年龄和性别,我们在之前的结果上略有改善:79%比78%。这种差别不大,可能是噪音。
前几项实验告诉我们的是,生存在很大程度上取决于年龄、性别和社会经济地位。单凭这三个因素,我们就有可能对生存率有一个相当好的预测。
但要想弥补最后几个百分点的准确性,还需要一些特征工程。

