







![[众诚云网科技]](/uploads/allimg/20190305/c4b08346cbe8b0efae6b132139c2d72a.png)

新闻中心 
玩转数据分析-探讨医院销售数据(全国医院数据)
 2023-08-02
2023-08-02 浏览次数:次
浏览次数:次 返回列表
返回列表数据分析的步骤:
提出问题→理解数据→数据清洗→构建模型→数据可视化
目标数据:2018年朝阳医院销售数据.xlsx
业务部门下发了一项业务分析目标,提出了业务指标问题,把数据发给我的时候就在思考该怎么分析,接下来一起探讨怎么进行简单的数据分析
一、提出业务指标问题
从销售数据中分析下面的业务指标问题:
(1)月均消费次数
(2)月均消费金额
(3)客单价
(4)消费趋势
首先导入所需要的包
import matplotlib.pyplot as plt from pandas import Series,DataFrame import pandas as pd import numpy as np将销售Ecxcel数据导入到python中
fileNameStr=E:\\2018python\朝阳医院2018年销售数据.xlsx xls=pd.ExcelFile(fileNameStr,dtype=object) salesDf = xls.parse(Sheet1,dtype=object)查看前五行数据
salesDf.head()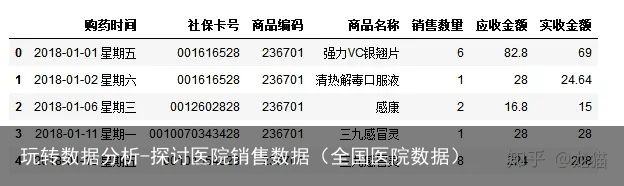
查看表格数据的行数和列数
salesDf.shape (6578, 7)可以查看到该数据有6578行,7列。
查看列的数据类型
salesDf.dtypes 购药时间 object 社保卡号 object 商品编码 object 商品名称 object 销售数量 object 应收金额 object 实收金额 object dtype: object二、数据清洗(数据预处理)
数据预处理主要有以下步骤:
(1)选择子集
(2)列名重命名
(3)删除缺失数据
(4)数据类型转换
(5)数据排序
(6)异常值处理
1.选择子集
本案例子集不用选择子集,需要的子集已经存在
2.列名重命名
salesDf.rename(columns ={购药时间:销售时间},inplace=True) #inplace=True,数据框本身会改动 salesDf.head()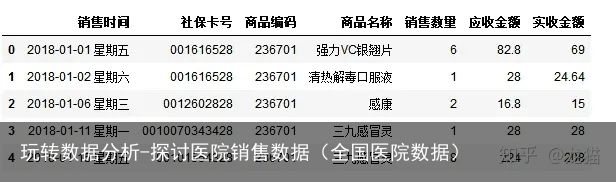
3. 删除缺失数据
删除列(销售时间,社保卡号)中为空的行,使用dropna删除缺失数据
print(删除缺失值前大小,salesDf.shape) #how=any 给定的任何一列中有缺失值就删除 salesDf=salesDf.dropna(subset=[销售时间,社保卡号],how=any) print(删除缺失后大小,salesDf.shape) 删除缺失值前大小 (6578, 7) 删除缺失后大小 (6575, 7)在删除缺失数据之前有6578行,删除缺失的数据之后是6575行,其中缺失数据有三行。
4. 数据类型转换
将字符串转换为浮点型数值
salesDf[销售数量]=salesDf[销售数量].astype(float) salesDf[应收金额]=salesDf[应收金额].astype(float) salesDf[实收金额]=salesDf[实收金额].astype(float) print(转换后的数据类型:\n,salesDf.dtypes) 转换后的数据类型: 销售时间 object 社保卡号 object 商品编码 object 商品名称 object 销售数量 float64 应收金额 float64 实收金额 float64 dtype: object日期列字符串转换为日期数据类型
#测试:字符串分割 testList=2018-06-03 星期五.split() testList [2018-06-03, 星期五] testList[0] 2018-06-03分割时间列,定义函数:分割销售日期,获取销售日期
def splitSaletime(timeColSer): timeList=[] for value in timeColSer: #例如2018-01-01 星期五,分割后为:2018-01-01 dateStr=value.split()[0] timeList.append(dateStr) timeSer=pd.Series(timeList) return timeSer获取“销售时间”这一列,对字符串进行分割,获取销售日期
timeSer=salesDf.loc[:,销售时间] dateSer=splitSaletime(timeSer)修改销售时间这一列的值
dateSer[0:3] 0 2018-01-01 1 2018-01-02 2 2018-01-06 dtype: object获取分割之后的销售日期,少了星期时间字符
salesDf.loc[:,销售时间]=dateSer salesDf.head()
数据类型转换:字符串转换为日期
salesDf.loc[:,销售时间]=pd.to_datetime(salesDf.loc[:,销售时间], format=%Y-%m-%d, errors=coerce) salesDf.dtypes 销售时间 datetime64[ns] 社保卡号 object 商品编码 object 商品名称 object 销售数量 float64 应收金额 float64 实收金额 float64 dtype: object转换日期过程中不符合日期格式的数值会被转换为空值,
这里删除列(销售时间,社保卡号)中为空的行salesDf=salesDf.dropna(subset=[销售时间,社保卡号],how=any)5. 数据排序
使用sort_values进行排序,by:按哪几列排序,ascending=True 表示升序排列,ascending=False表示降序排列
#按销售时间进行升序排列 salesDf=salesDf.sort_values(by=销售时间,ascending=True) #查看排序后的前10行 salesDf.head(10)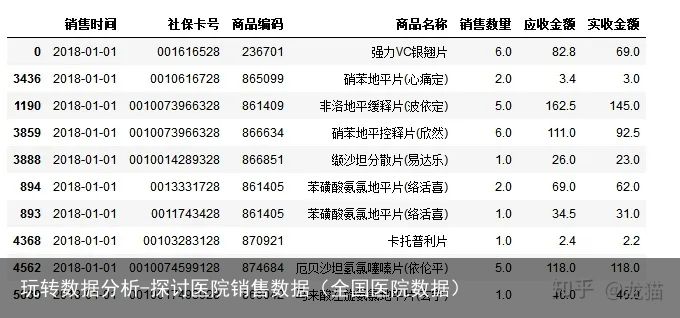
重命名行名(index),使用reset_index修改成从0到N按顺序排序的索引值index
salesDf=salesDf.reset_index(drop=True) salesDf.head(6)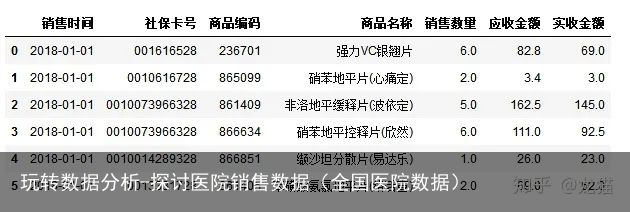
6. 异常值处理
查看汇总数据描述,其中销售数量值不能小于0
salesDf.describe()
通过条件判断来删除异常值
querySer=salesDf.loc[:,销售数量]>0 print(删除异常值前:,salesDf.shape) salesDf=salesDf.loc[querySer,:] print(删除异常值后:,salesDf.shape) 删除异常值前: (6549, 7) 删除异常值后: (6506, 7)数据的预处理工作完成,接下来分析业务的各个指标
三、构建模型,计算各个指标
1.月均消费次数
业务指标1:
1.月均消费次数=总消费次数 / 月份数
在计算总的消费次数当中将每个人每天的不同消费记录作为消费一次,用drop_duplicates去掉同一天同一个人的重复消费记录
根据列名(销售时间,社区卡号),如果这两个列值同时相同,只保留1条,将重复的数据删除
kpi1_Df=salesDf.drop_duplicates(subset=[销售时间, 社保卡号]) #总消费次数 totalI=kpi1_Df.shape[0] print(总消费次数=,totalI) 总消费次数= 5342计算月份数
#按销售时间升序排序 kpi1_Df=kpi1_Df.sort_values(by=销售时间,ascending=True) #重命名行名,索引排序 kpi1_Df=kpi1_Df.reset_index(drop=True) kpi1_Df.head()
计算总月份数,第一行时间与结尾时间之差除以30取整
startTime=kpi1_Df.loc[0,销售时间] endTime=kpi1_Df.loc[totalI-1,销售时间] daysI=(endTime-startTime).days #月份数: 运算符“//”表示取整除 monthsI=daysI//30 print(月份数:,monthsI) 月份数: 6月份数计算得出为6.
2.月均消费次数
业务指标2:月均消费次数=总消费次数 / 月份数
计算月均消费次数
kpi1_I=totalI // monthsI print(业务指标2:月均消费次数=,kpi1_I) 业务指标2:月均消费次数= 8903.月均消费金额
指标3:月均消费金额 = 总消费金额 / 月份数
#总消费金额 totalMoneyF=salesDf.loc[:,实收金额].sum() #月均消费金额 monthMoneyF=totalMoneyF / monthsI print(业务指标3:月均消费金额=,monthMoneyF) 业务指标3:月均消费金额= 50668.351666666664.客单价
指标4:客单价=总消费金额 / 总消费次数
客单价(per customer transaction)是指商场(超市)每一个顾客平均购买商品的金额,客单价也即是平均交易金额。
# totalMoneyF:总消费金额 ,totalI:总消费次数 pct=totalMoneyF / totalI print(客单价:,pct) 客单价: 56.9094178210408055.消费趋势图
指标5:消费趋势画图
groupDf=salesDf #重命名行名(index)为销售时间所在列的值 groupDf.index=groupDf[销售时间] groupDf.head()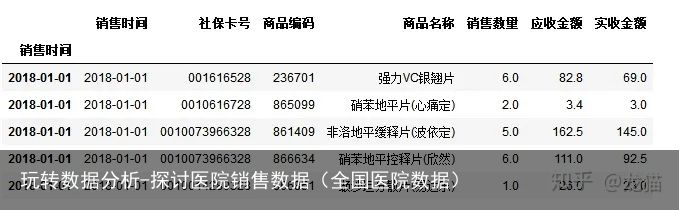
分组
gb=groupDf.groupby(groupDf.index.month) gb <pandas.core.groupby.DataFrameGroupBy object at 0x000000000EF047B8>应用函数,计算每个月的消费总额
mounthDf=gb.sum() mounthDf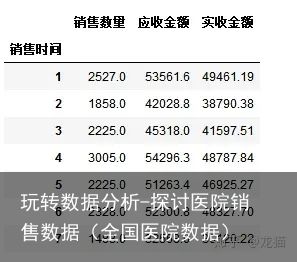
选取每个月的应收金额和实收金额的消费总额
mounthDf=DataFrame(mounthDf,columns=[应收金额,实收金额]) mounthDf6.数据可视化
对每个月的应收金额和实收金额的消费总额进行数据可视化,画出消费趋势图
from pylab import * mpl.rcParams[font.sans-serif] = [SimHei] #防止中文乱码 mounthDf.plot(title=2018年朝阳医院数据消费金额趋势图,figsize=(15,8),fontsize=20) <matplotlib.axes._subplots.AxesSubplot at 0x16731a20>医院销售趋势图以上可以看出第1月和第七月消费总金额是最高的,在第七月消费金额最低。
医药销售量和天气变化有一定的影响,尤其在冬季天气寒冷和初春季节,容易受到天气影响,气温变化大,市民容易感冒,从而在医药行业销售更多了医药,销售量上升,在气温平稳时期销售量下降。
总之,医药销售金额会受到当地天气和环境等因素的影响,销售医药需要考虑当地天气环境因素来制定相关的销售计划,备足急需的医药库存。相关技术知识:
1.在导入数据excel表格时需要先 pip install xlrd导入相应的包。
2.缺失数据处理方法,dropna函数详细使用地址:https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.dropna.html
3.matplotlib教程官网:Python plotting - Matplotlib 2.2.2 documentation
